A demand cache populates data on command - i.e., lazily as applications request data. A demand cache is useful for data that is read frequently but unpredictably.
Trading systems often reference thousands of products frequently but do not necessarily modify them. This makes product information good candidates for caching, but the total time to initialize the cache with a complete set of products can be significant. An alternate strategy is to retrieve and cache product information only when required The application only incurs data source and cache storage overhead for the product data that corresponds to active users. Throughout the user's session, the application can retrieve product information from the cache quickly. Demand cache therefore, describes a strategy for populating caches incrementally as applications request data.
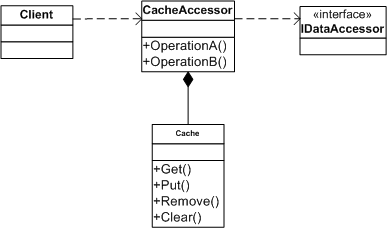
The following figure illustrates the static structure for the Demand Cache (identical to that of the Cache Accessor) :
As usual, we start with the entry point to the client and this is the CacheAccessor class. The CacheAccessor manages both cache and database operations. Class Cache implements the actual cache storage mechanism. Its operations refer to cached data using unique keys (unique keys uniquely identify each data item in the storage). If data is stored in an ADO.NET DataTable then the unique key should already be present if the underlying database table has a key. For domain object, keys are represented as identity objects.
CacheAccessor delegates all its database operations to IDataAccessor which can be an ADO.NET provider, a Data Accessor implementation, or a domain object mapping. Note that the closer your define CacheAccessor operations to match those of IDataAccessor, the more transparent the CacheAccessor will be to your client code.
The following figure illustrates the sequence diagram when a client uses Cache Accessor to read cached data:
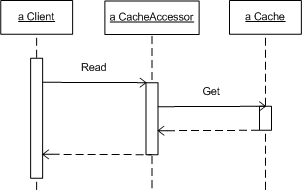
The CacheAccessor forms the cache key based on the Read operation's parameters. It finds the data in the cache and returns it without any database interaction. CacheAccessor class does not dictate when or how to populate the cache - all it does is access the cache.
The following sequence diagram illustrates what happens when a client requests data that is not cached. The CacheAccessor attempts to get data from the cache but receives null, so it attempts instead to read the data from the database. The CacheAccessor then stores this data in the cache before returning to the client. Now that the data is in the cache, the client will find much quicker the next time the client requests it.
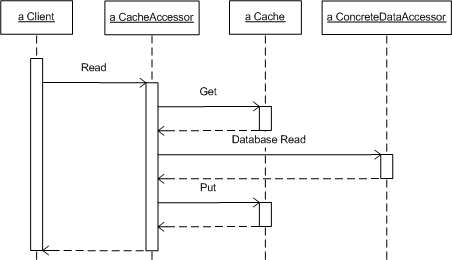
The cache always begins empty so the first request for data always requires a database access. However, as the system runs, the cache gradually gets populated and the database is rarely accessed.
public class CacheAccessor
{
// Data members
DataTable m_dtCache = null;
// Constructors
public CacheAccessor(DataTable dt)
{
m_dtCache = dt;
}
// Reads a cached entry by first
verifying that the primary keys are valid, and then finding data
// based on the supplied keys. If data is not found, it is
retrieved from the database
public DataRow Read( Hashtable keys )
{
DataRow row = null;
// Check that primary keys of the cache match those supplied by aPrimaryKeys (should match
// in number and in column names)
DataColumn[] dcPrimaryKeys =
m_dtCache.PrimaryKey;
if (dcPrimaryKeys.Length ==
keys.Count)
{
foreach (DataColumn dc in
dcPrimaryKeys)
if (!keys.Contains(dc.ColumnName))
throw new InvalidOperationException( "Invalid primary key names given" );
}
else
{
throw new
InvalidOperationException( "Invalid number of primary keys given" );
}
// Copy the columns names into an array than be used within DataTable.Contains()
object[] aPK = new object[ keys.Count ];
keys.Keys.CopyTo( aPK, 0 );
// Does the DataTable contain a record whose
primacy keys are described by aPrimaryKeys?
// If so, return the matching row
if (m_dtCache.Rows.Contains( aPK ))
row =
m_dtCache.Rows.Find( aPK );
else
{
// Data not found. Retrieve from database by first constructing the SQL and then
issuing a query
string
strWhere = ...; //
Construct a where expression from the keys map
string strSQL
= "select * from " + m_dtCache.TableName + " where " +
strWhere;
DataTable
dtNew = ExecuteSQL( strSQL );
row =
dtNew.Rows[0];
// Now attach the newly loaded data to the existing cache (create a new row,
populate it, then add it to m_dtCache)
DataRow r = m_dtCache.NewRow();
...
m_dtCache.Rows.Add( r );
}
return row;
}
}
// CLIENT
// Get data from database
DataTable dt = ExecuteSQL( "select TradeID, SecID, BrokerID, Cash, EntryDate from T" );
// Cache data in the accessor
CacheAccessor accessor = new CacheAccessor( dt );
// Now read data from the datatable
Hashtable htKeys = new Hashtable();
htKeys.Add( "TradeID", "12QWA" );
htKeys.Add( "SecID", "12333DF345" );
DataRow row = accessor.Read( htKeys );
...
Use this pattern when:
It may be valid for a customer to request data that does not exist in the database. Special flags may be used within the CacheAccessor to prevent it from repeatedly querying the database when no results are expected.