The relational database model puts a firm conceptual foundation under both the database and the DBMS features. The following sections discuss the major components of the relational database model
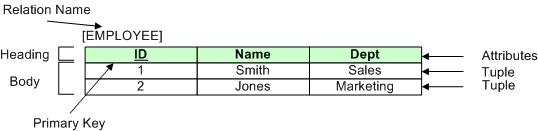
The relational database model consists of three parts: data structure (this section), data integrity, and data manipulation. The data structure model defines how to represent data. Most basic to the data structure model is the relation which is illustrated below:
A relation, which is the most basic part of the data structure model, has two parts: relation heading and relation body:
Being able to reference attributes (columns) by name and tuples (rows) by primary key values provides a data model that has no physical storage model associated with the data organization. The relational data model is the only one that achieves complete physical data independence. Applications do not need to know at all how data is organized as long as the database takes care of finding the right data when the application provides table and column names along with primary key values.
Another fundamental part of the relation model data structure is the concept of a domain. Simply stated, a domain combines two pieces of information - the set (possibly infinite) of allowable values that an attribute (column can have), and the semantics (meaning) of the values. In other words, a domain defines a set of allowable values. For example, for the ID column the domain is the set of all integers greater than zero, whereas for the Dept column the domain is the set of { Sales, Marketing, Research, Accountancy}.
The following table should help navigate relational model terminology:
| Relation Model Term | Database term |
| Attribute | Column |
| Domain | Column Type |
| Tuple | Row |
| Attribute value | Column value |
| Entity | Table |
Data normalization is a process in which data attributes (values) within an entity (table) are organized to increase the cohesion of entity types (tables) and to reduce coupling between entity types (tables). In other words, normalization is the process of splitting tables with redundant information into two or more tables. Denormalization on the other hand, is the exact opposite of normalization - it is the process of combining two or more tables together.
The goal of normalization is to reduce or even eliminate data redundancy. This is an important consideration for data developers because in an object-relational map it can be difficult to translate objects to their corresponding tables. The advantage of having a highly normalized data schema is that information is stored in one place and one place only, reducing the possibility of inconsistent data. Also, highly normalized data schema are close in general to object-oriented schemas and this makes it much easier to map objects (data access objects) to your schema.
The general approach to database normalization should be:
Unfortunately, data normalization does come with a performance cost. Consider the following table which has no normalization at all:
With this table schema, all data relevant to an order is stored in one row (assuming orders of up to nine items only - an unreasonable restriction). Because all data is in one row, data can be very easily and quickly accessed. For example, it is very easy to calculate the total amount by adding all ItemXPrice values. Now consider an alternative schema shown below:

The notation used to link the tables together is UML notation, although other notation types can be used. Irrespective of what notation type is used, reading the diagram is the same. To read the notation: start with the table name, then any symbols attached to the connecting line or any description attached to the connecting line, then any multiplicity attached to the end of the connecting line, then the end table name. In other words: [StartTableName] + Symbol | Description + Multiplicity + [EndTableName]. The following examples illustrate:
To calculate the total amount you need to read data from a row in the [Order] table, data from all the rows in the [OrderItem] table and data from the corresponding rows in the [Item] table for each order item. For this kind of query the previous schema provides better performance.
It is important to be clear about the meaning of redundancy. The redundancy that should be avoided is the repeated representation of the same fact. For example, in the following table which is 1NF, the fact that warehouse 1 is located in Stree1 is repeated twice (attributes in green are keys). This means that any change to a warehouse address must be made to all records that store the address:
| ItemID | WarehouseID | Qty | Warehouse Address |
| A | 1 | 10 | Street1 |
| A | 2 | 5 | Street2 |
| B | 1 | 30 | Street1 |
| C | 2 | 60 | Street2 |
Note: formally, the concept of facts is knows as functional dependence. If a table has two columns A and B, then B is functionally dependent on A if values of A uniquely determine values of B (in other words, the same value of A necessarily means the same value of B).
Let's look at another example that is not so obvious. Consider the [OrderItem] table which represents items for any given order:
| OrderID | ItemID | Quantity | Price |
| 1 | 54 | 1 | 39.99 |
| 2 | 89 | 2 | 24.99 |
| 2 | 54 | 5 | 39.99 |
| 3 | 54 | 6 | 39.99 |
The redundancy here is the price for each item. In many businesses, an item will always have one price and the preceding table contains redundant item prices. But what if item prices were negotiated on each order or there were special promotions? Then it would be possible for the relation above to have the following contents:
| OrderID | ItemID | Quantity | Price |
| 1 | 54 | 1 | 35.99 |
| 2 | 89 | 2 | 24.99 |
| 2 | 54 | 5 | 39.99 |
| 3 | 54 | 6 | 29.99 |
For the business model that this relation represents, there is no fact redundancy. The price of an item must be explicitly stored with each item.
This example presents a crucial point in understanding normal forms: If you want to unambiguously represent various facts in a database, you must structure the relations so that they have no redundant representations of facts. The obvious consequence is that there is no mechanical method of normalizing relations. You must first know which facts you want to represent and then define the relations accordingly.
In database design there are a number of forms (or properties, or constraints) that a table scheme may possess. A table may assume a specific form to achieve certain design goals such as minimizing dependency. These forms are called normal forms. The following normal forms are discussed:
Each of these forms includes its predecessor. For example, a 2NF table is also a 1NF table, and a 3NF table is also a 2NF table, which is also a 1NF table. By definition, a table is 1NF. While it is generally desirable for database tables to have a high normal form, the situation is not as simple as it seems. Forcing all table schemes to be in a particular normal form may require some compromises. The following table summarizes the most common normalization rules that describe how to put entity types into a series of increasing levels of normalization.
| Normalization Level | Rule |
| First Normal Form 1NF | An entity type is 1NF when it contains no repeating groups of data. In other words, each attribute (column) value is atomic - it must not be a set of values. |
| Second Normal Form 2NF | An entity type is 2NF when it is 1NF and all of its non-key attributes (columns) are fully dependent on its primary key. |
| Third Normal Form 3NF | An entity type is 3NF when it is 2NF and all its attributes are directly dependent on its primary key. |
The important thing to remember is that you want to store data in one place and one place only. With respect to terminology, a database schema is at the level of normalization of its least normalizes entity types. For example, if all entity types are at 2NF or higher, then the database schema is at 2NF
In table Order0NF you can see that there are several repeating attributes - the ordered item information repeats nine times, and the contact information is repeated twice (once for shipping and once for billing). But what happens if an order has more than nine items? Do you create additional records for them? What about the majority of orders that have one or two items? Do you want to write redundant code to process the nine copies of order information?
The following figure represents a worked data schema where the [Order] schema is put into first normal form:
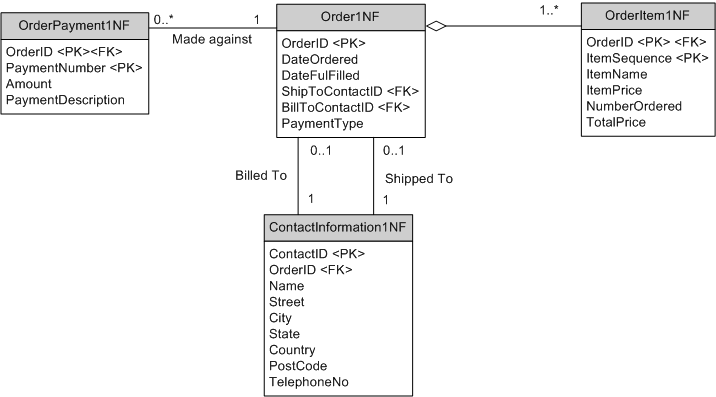
Table [OrderItem1NF] allows us to have as many order items as we like. This increases the flexibility of the schema while reducing storage requirements for small orders. Table [ContactInformation1NF] also offers a similar benefit when the billing and shipping addresses are the same. Table [OrderPayment1NF] was introduced to allow customers to make 0 or more payments against an order from [Order1NF] as table [Order0NF] presented previously could not accept more than two payments.
An important thing to notice here is the application of primary and foreign keys in the new schema. When a new table is introduced into the schema as the result of first normalization efforts, it is common to use the primary key of the original table as part of the primary key of the new table. For example, [OrderItem1NF] also includes the OrderID column within its schema. But because, many order items can have the same OrderID, ItemSequence was added to form a composite primary key for table [OrderItem1NF].
A different approach was taken with table [ContactInformation1NF]. The column ContactID, a surrogate column that has no business meaning, was made the primary key, while OrderID was needed as a foreign key to maintain the relationship back to table [Order1NF].
A good rule of thumb is that if two tables are strongly related (i.e., [Order1NF] and [OrderItem1NF]) then it makes sense to include the primary key of the original table as part of the primary key of the new table. If the two tables are not as strongly related (i.e., [Order1NF] and [ContactInformation1NF]), then a surrogate key makes more sense
The schema presented in First Normal Form 1NF can be further improved to the second normal form 2NF as shown below:
Recall that an entity type is 2NF when it is 1NF and all of its non-key attributes (columns) are fully dependent on its primary key. This is definitely not the case with OrderItem1NF - item information in OrderItem1NF does not depend on an order for that item. For example, if customer A orders 1 computer and customer B orders 2 printers, the fact that the items are called "computer" and "printer" and that the unit prices are $999 and $399 does not depend on the order and are constant. Item name and price depends on the concept of the item and not the concept of an order, and therefore should not be stored in the OrderItem2F table but rather in the new table Item2F. OrderItem2F retains the TotalPrice as this is a calculated column.
Recall that an entity type is 3NF when it is 2NF and all its attributes are directly dependent on its primary key. A better way to word this rule is that the attributes (columns) of an entity type (table) must depend on all parts of the primary key. Therefore, 3NF is only an issue for tables with composite primary keys:
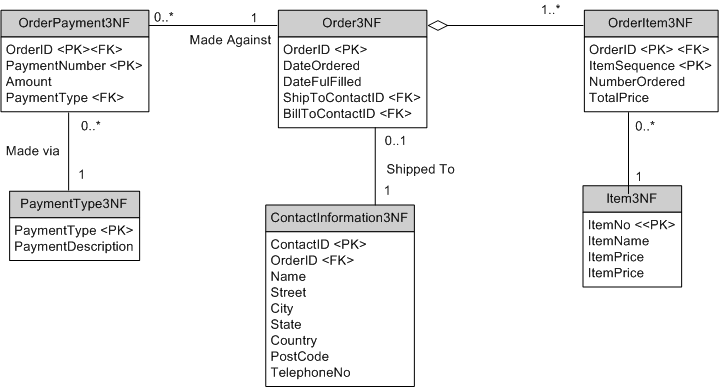
In table [OrderPayment2NF], the payment-type description (i.e., Cash, Visa, etc) depends only on the payment type and not on the combination or Order ID and payment type attributes. To resolve this problem, [PaymentType3NF] was introduced as shown above. Note now that in [PaymentType3NF], PaymentDescription fully depends on PayementType.
What normal form does the following table have?
| ItemID | WarehouseID | Qty | Warehouse Address |
| A | 1 | 10 | Street1 |
| A | 2 | 5 | Street2 |
| B | 1 | 30 | Street1 |
| C | 2 | 60 | Street2 |
The table above has atomic values for all attributes (columns), therefore, it is at least 1NF. Is it 2NF as well? If it was 2NF then a non-key attribute such as the WarehouseAddress would have to fully depend on the primary key, which in this case is a composite key consisting of ItemID and WarehouseID attributes. In other words, WarehouseAddress values would only be known by knowing both ItemID and WarehouseID values. However, this is not case as WarehouseAddress values would only be known by knowing only WarehouseID values. Therefore, table above is 1NF only.
The table above can be normalized (split into two tables) into 2NF as shown below:
| ItemID | WarehouseID | Qty |
| A | 1 | 10 |
| A | 2 | 5 |
| B | 1 | 30 |
| C | 2 | 60 |
| WarehouseID | Warehouse Address |
| 1 | Street1 |
| 2 | Street2 |
| 1 | Street1 |
| 2 | Street2 |
While the Relational Model: Data Structure section discusses the form for representing data, the data integrity portion of the relation model defines mechanisms for ensuring that stored data is valid. At a minimum this requires the following:
ItemID WarehouseID Qty A 1 10 A 2 5 B 1 30 C 2 60
WarehouseID Warehouse Address 1 Street1 2 Street2 1 Street1 2 Street2 WarehouseID is used as a column in both tables. Referential integrity ensures that a WarehouseID value in the [Inventory] table can be used to look up or reference the appropriate row in the [Warehouse] table. The WarehouseID in the [Inventory] table acts as a foreign key - it addresses rows that reside in another table. The WarehouseID column in the [Warehouse] table acts as a primary key and hence can never be NULL. .
Note the following points about foreign keys:
- A foreign key value can be NULL. This means that the related row in the foreign table is unknown or does not exist.
- If a foreign key value is not NULL, the related row in the foreign table must exist.
- Composite foreign keys cannot be NULL. This would make it impossible to uniquely identify the relate row in the foreign table.
Data representation and data integrity do not make a complete model. There must be some means of manipulating data as well. Details on how to manipulate data are covered in the DML section.
