Key Concept: Different components have different requirements of their environment. It is these requirements that define the context in which a component will run. The following will use COM+ as an introduction to contexts.
COM+ Transactions require code to run in isolation, so COM+ ensures that all components that use the same transaction are synchronized - that is, there is only one thread of execution so that it is not possible for two components in a transaction to be executing at the same time. Synchronization is added automatically to components that use transactions.
.NET uses COM+ for its component services, but it broadens the idea of contexts. .NET components that use contexts need not use COM+. .NET code indicates the services it requires, and hence the context in which it should run Using attributes, the runtime ensures that the appropriate context exists when the object is created. Context attributes are understood by the .NET runtime, because it is the .NET runtime that creates contexts.
The following are key points with respect to contexts:
.NET components can be context bound or context agile. By default, objects are context agile which means that the context in which they are used does not matter. Therefore, they can be accessed through direct references when they are accessed from within the application domain where they were created - irrespective of the context of the object making the call.
A component that is context bound must run in a specific context. To indicate its context requirements, the object's type has a specific context attribute or derives from a specific base class - usually ContextBoundObject. If the context of the object's creator is suitable, the runtime will create the object there, otherwise it will create a new context for the new object. A context bound object remains in its context for the duration of the object's life.
You can obtain the Context object for the default context of the application domain by calling Context.DefaultContext, and for the current thread by calling Thread.DefaultContext. The properties of the Context object are then accessed using Context.ContextProperties.
You may decide that your context-agile object needs to have data that is specific to the context in which it is run. A simple example is context-agile object that can be called by different threads. You may decide that the object's data is specific to the thread that calls it, and out the data into thread-local storage. The generic way to do this is through data slots. Once you have the current context, you can call methods on the context object to access data slots - AllocateDateSlot, AllocateNamedDataSlot, GetNamedDataSlot, FreeNamedDataSlot, SetData, and GetData.
In general, context-agile objects can be divided into three types:
By default, primitive data types are passed by value - which means that the actual value is placed on the stack. After the method accesses the parameter, if the code alters the value, it is the value on the stack that is altered, and because the call stack lives only as long as the method class, this changed value is discarded when the function returns. In other words, when passing by value, a copy is made and all changes (if any) are made to the copy and not the original value. Recall that .NET defines an application domain as a unit of isolation within a process. A primitive value can be passed by value through method calls, within an application domain, and across application domain boundaries. This is true in both C# and C++.
Both C# and C++ also provide a mechanism to pass parameters by reference. In C#, use the ref keyword, In C++, use a __gc*:
// C#. Passing by reference. Not how
the ref keyword is used
void foo()
{
int i = 10;
TimesTwo( ref i ); //
i = 20
}
void bar( ref int i)
{
i *= 2;
}
// C++. Passing by reference. Not
how the a GC pointer is used
void foo()
{
int i = 10;
TimesTwo( &i );
// i = 20
}
void bar( int __gc* i)
{
*i *= 2;
}
This code indicates that we are passing a pointer, which means that by de-referencing the pointer, the called code gets access to the storage in the calling code. The parameter is said to be passed by reference. If this call is made across process or machine boundaries, the access is across those boundaries. Both C# and C++ can restrict how such pointer parameters are used: C# uses the out keyword. C++ uses the System::Runtime::InteropServices::OutAttribute attribute:
// C#
void foo()
{
int i = 0;
Two( out i
); // i = 2
}
void Two( int out i)
{
i = 2;
}
// C++
void foo()
{
int i = 0;
Two( &i
); //
i = 2
}
void Two([Out] int __gc* i)
{
*i = 2;
}
The runtime assumes that all parameters passed through pointers are in/out unless the [OutAttribute] is applied to indicate that data is returned only through the pointer.
What happens if the parameter type itself is a reference? Primitive types are passed by value. Pointers are also passed by value, but reference types are passed by reference. And in C#, a class is always a reference type:
// In C#, a class is a reference
parameter, and hence passed by reference
public class CNumber
{
public int nNum = 0;
public CNumber(int n) { nNum = n; }
...
}
...
public void foo()
{
CNumber o = new CNumber(10);
TimesTwo( o
);
// o is passed by reference because it is a reference
type. o = 20
}
public void TimesTwo( CNumber o ) //
No need to specify ref keyword
{
o.nNum *= 2;
}
A reference type such as a C# class is always passed by reference. But, a reference can be passed by value if they are written to support this capability. A reference type that is passed by value is serialized to a stream of bytes, and it is this stream that is passed to the method. The runtime creates an un-initialized instance of the object and used the stream to initialize it.
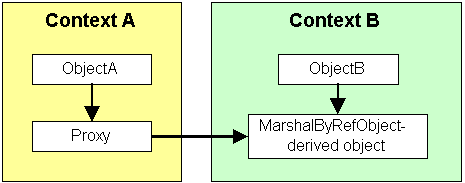
For example, a remote object is required to execute in a particular context, in a specific application domain. Such an object must be marshaled by reference so that it runs in the domain where it was created, but it can be accessed from another domain.
An object that is derived from MarshalByRefObject can be accessed through a direct pointer by an object within the same context (ObjectB), whereas an object in another context (ObjectA) can access the marshalable object only through a proxy.
The client code (say ObjectA above) can pass the reference to the out-context-object to another context. In such a case, the ObjRef object is passed to another context, which can use the information in the ObjRef object to create a proxy to the real object.
When a marshal-by-value object is passed to another domain, the state of the object is extracted and put into a serialization stream that also has information about the object it represents (its type and assembly.) When the object is un-marshaled into the importing domain, the runtime reads the serialization stream to determine the type of the object. It then creates an un-initialized instance of the type by calling the default constructor, and it initializes the instance by writing the values held in the serialization stream directly into the fields of the object.
The above implies some important points: First, a serializable class must have a default constructor, but it does not need any other constructors. Second, the runtime initializes the object's fields by writing to them directly - it does not matter what access specifier has been assigned to serializable fields, as the runtime is able to read/write private fields. Third, you can control how an object is serialized by implementing the ISerializable interface.
The following table summarizes object types:
| Context | Base Class | Meaning |
| Not marshaled, but agile | Object | Can be used in any context within the domain through a direct reference. |
| Marshaled by value, agile | May use Serializable, may also derive from ISerializable. | State flows to another domain where the object is accessed through a direct reference. There is not distributed identity. |
| Domain-bound, agile | MarshalByRefObject | Object is bound to a specific application domain, but can be accessed by other objects in another domain through a proxy. The state is specific to a domain. The object has a distributed identity. |
| Context-bound | ContextBoundObject | The state is specific to a context. Out-of-context access is through a proxy. |
The following table summarizes access to instance members on the various object types, from objects in different locations:
| Type | Within Context | Within Domain | Outside of Domain |
| Context-bound | Direct | Proxy | Proxy |
| Domain-bound, marshaled by reference | Direct | Direct | Proxy |
| Marshaled by value | Direct | Direct (copy) | Direct (copy) |
| Not marshaled | Direct | Direct | Not allowed |
Note that marshaling occurs only when code accesses instance members; static members are always agile and can be accessed without marshaling. This means that if you have a static data member, the data will exist in the context where the member is accessed.
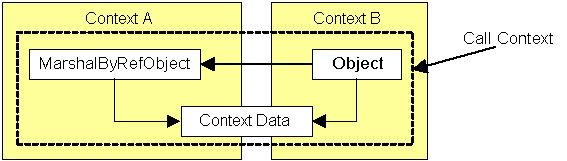
The call context acts like a logical thread, so the marshal-by-value class must derive from ILogicalThreadAffinative to indicate that it should be accessed only on this logical thread. The Framework provides a class called CallContext to give access to the call context through static methods. The call context has named data slots that are specific to the particular call, so the client can call CallContext.SetData() to store an ILogicalThreadAffinative object in a named data slot, and the object can call CallContext.GetData() to retrieve the out-of-band data. In addition, the call context can contains an array of objects called headers that have name/value pair. These cal be set/get through the SetHeaders() / GetHeaders() methods:
// A marshal-by-value object that
has a logical thread affinity
[Serializable]
public class ThreadAffinityObj : ILogicalThreadAffinative
{
// Data members
private string str;
// Constructors
public ThreadAffinityObj() { str = "Created in
" + AppDomain.CurrentDomain.FriendlyName; }
// Public interface
public void GetLocation()
{
Console.WriteLine("ThreadAffinityObj in " +
AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine( str );
}
}
// A context-bound object
public class CrossCtxObject : MarshalByRefObject
{
// Public interface
public void GetLocation( string strSlot)
{
Console.WriteLine("CrossCtxObject in " +
AppDomain.CurrentDomain.FriendlyName);
// Get
out-of-band data
ThreadAffinityObj obj;
obj = (ThreadAffinityObj)CallContext.GetData(
strSlot );
obj.GetLocation();
}
}
// Main application
class App
{
public static void Main()
{
// Create a
second domain
AppDomain ad =
AppDomain.CreateDomain( "Second AppDomain", null );
// Create
aninstance of the context-bound CrossCtxObject in the second domain
Assembly assembly =
Assembly.GetExecutingAssembly();
ObjectHandle oh = ad.CreateInstance(
assembly.FullName, "CrossCtxObject");
CrossCtxObject b = (CrossCtxObject)
oh.Unwrap();
// Now set a
dataslot with a marshal-by-value object (this object is created here in the
default app domain)
CallContext.SetData(
"Test", new ThreadAffinityObj() );
b.GetLocation("Test");
}
}
A context is a conglomeration of individual contexts. You may have a context made up of two subcontexts, with subcontext A applying synchronization and subcontext B applying additional security checks. As calls are made into or out of a context, they are intercepted by the subcontexts that make up the context, so that appropriate action may be taken. In .NET technology, the segments of code that perform this appropriate action are called sinks.
Contexts contain two chains of sinks and are summarized in this figure:
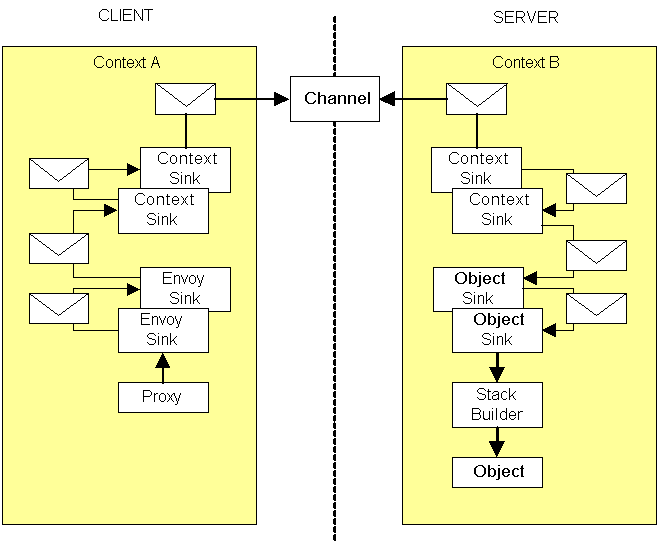
On the client side, the proxy calls through an Envoy Sink chain which then calls through the Client Context Sink chain, after which the Channel is contacted to transmit the call to the server. On the server side, the channel calls the Server Context Sink chain which calls the Object Sink chain, which eventually calls an object called the Stack Builder that constructs the stack before the calling the real object.
The contexts sinks are used to process messages as they enter or leave the context. Context sinks implement the IMessageSink interface and are called in response to a call to a context property. To create a context property, you derive an attribute from ContextAttribute and implement either IContributeClientContextSink or IContributeServerContextSink (or both) and then apply this attribute to the class that needs to use the custom context. The runtime calls GetClientContextSink or GetServerContextSink methods to create the context sink; both methods are passed a reference to the chain of sinks created so far. Your custom context sink will be called by the runtime when a call is made across a context boundary, and your sink should carry out its action before calling the next sink in the chain.
Envoy sinks on the client side are called within the context before the context sink chain - in effect, this is the client side representation of the server context. As with context sinks, envoy sinks and object sinks implement the IMessageSink interface. On the server side, the context property that provides the sink implements IContributeObjectSink; on the client side, the property should implement IContributeEnvoySink. These interfaces each have a method to create the appropriate sink - GetObjectSink and GetEnvoySink, respectively, which is called by the runtime.
Envoy sinks are available through the proxy for the object. The proxy holds the ObjRef instance for the object, and ObjRef has a property called EnvoyInfo which is an IEnvoyInfo interface reference.
Context sinks, envoy sinks, and object sinks should be considered part of the context - the context will not work without them. So if you want to temporarily add a sink to the chain at runtime - perhaps for debugging and/or logging - context sinks are not the way to do it. To perform this action, the .NET runtime offers dynamic sinks, available through dynamic context properties. These dynamic properties can be registered/unregistered at runtime. They do not take part in the context chain; they are just observers and add nothing to the context, and they are called when a message crosses a context or application domain boundary. The following figure illustrates these concepts:
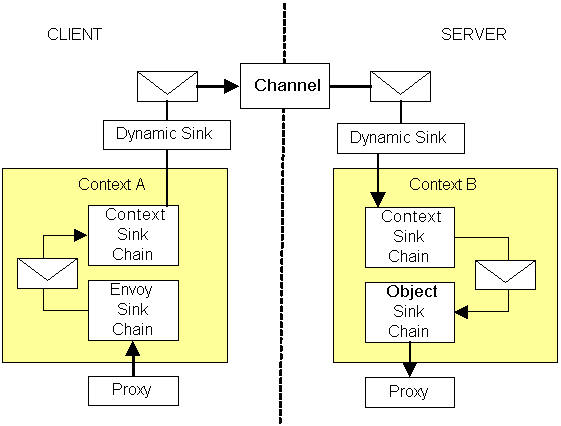
To write a dynamic property you should implement a class that 1) implements the IDynamicProperty interface which gives access to the dynamic property's name, and 2) implement the IContributeDynamicSink interface which has a method, GetDynamicSink(), that returns a reference to an object that implements IDynamicMessageSink interface. Because the dynamic sink does not contribute to the context, it does not implement IMessageSink. Instead, IDynamicMessageSink allows the dynamic sink to have access to the message merely to see what the message contains.
To indicate to the runtime that the dynamic sink should be used, you must register it with the runtime using Context.RegisterDynamicProperty(). Similarly, when you no longer need the dynamic sink, unregister it using Context.UnregisterDynamicProperty().
The following example defined a context-bound object that uses the [Synchornization] attribute to identify a context requirement of the object - in this case, to ensure that all out-of-context calls are synchronized so that only one call is active at any one time. To make sure that the object is called from another context, the object is created on the main thread, and then a new thread is created to call the object
[Synchronization]
public class App : ContextBoundObject
{
static void Main()
{
// Spy is a
class that implements a dynamic property as explained above
Context.RegisterDynamicProperty(
new Spy(), null, null );
App a = new App();
Thread t = new Thread( new
ThreadStart(a.CtxBoundMethod) );
t.Start();
t.Join();
}
public void CtxBoundMethod()
{
Console.WriteLine( "In
CtxBoundMethod" );
}
}
Recall that when a context-bound object is used across a context boundary, a proxy to that object is used. The proxy is created from an ObjRef object which among other things, identifies the location of the true object. The operation of creating an ObjRef object from an actual object is called Marshaling, and the process of creating a proxy from an ObjRef object is called unmarshaling.
You can define and create a tracking handler to monitor these calls to marshal and unmarshal ObjRef objects. A tracking handler implements the ITrackingHandler interface and is registered/unregistered using the TrackingServices class:
public class MyTracker : ITrackingHandler
{
public void DisconnectedObject( object o)
{
// trace
statements ...
}
public void MarshaledObject( object o, ObjRef or)
{
// trace
statements ...
}
public void UnmarshaledObject( object o, ObjRef or)
{
// trace
statements ...
}
}
// In the code that use MyTracker
TrackingServices.RegisterTrackingHandler( new Tracker() );
Serialization is important for contexts and remoting. Serialization is also important in other areas too. For example, with serialization, a marshal-by-value object can be stored in a database or passed through MSMQ.
The serialization process extracts the state of an object and places it in a stream that can be transmitted across to other contexts. A couple of things are implied - First, there must be a way to identify the fields that constitute the state of the object, and there must be a mechanism to extract the values in these fields. Second, there must be some code that can convert this data into a format the stream can hold.
The information about what items constitute the state of the object is held in metadata inserted by the attributes [Serialization] and [NonSerialized]. The [Serialization] attribute can be applied to classes, delegates, enums, fields, and structs. Note that it does not make sense to apply this attribute to temporary or derived fields that can be calculated from other fields within the object.
Note that the [Serialization] attribute is not inherited. If a base class declares this attribute, derived classes will not inherit it. On the other hand, [NonSerialized] attribute is inherited.
The runtime serializes an object using a formatter. The Framework provides several formatters with the base classes in System.Runtime.Serialization namespace. A formatter should implement the IFormatter interface:
public interface IFormatter
{
// This method serializes the given
object into the stream as appropriate. Note that the object
// is called graph because it may be a simple primitive type,
a simple object, or an object with
// embedded objects.
void Serialize( Stream serializationStream, object
graph);
// This method creates an object from
the serialization stream
void Deserialize( Stream serializationStream )
// This property has information about
the destination of the data when an object is being serialized,
// or the source of the data when the object is being
deserialized
StreamingContext Context {get; set;}
// This property is an object that
contains the surrogates that may be used to do the serialization.
ISurrogateSelect SurrogateSelector {get; set;}
// In some cases, the formatter
deserialization code may change the class to be loaded and initialized
// using the Binder property
SerializationBinder Binder {get; set;}
}
When an object is serialized, the formatter should write complete information about that object, including the full name of its type and the full name of the assembly that holds its type, so that an un-initialized instance of the type can be created during de-serialization and initialized with the serialization stream.
The framework provides two standard formatters - SoapFormatter and BinaryFormatter. Using a formatter is straightforward:
/* The following code serializes
an instance of a Point class into a file stream
*/
// Create an instance of a class to be serialized
Point pt = new Point( 1, -1);
// Create a binary formatter that will serialize into a
file stream
BinaryFormatter bf = new BinaryFormatter();
Stream stm = new
FileStream( "data.dat", FileMode.Create );
// Now serialize the Point object into the file stream
bf.Serialize( stm, pt);
// Cleanup
stm.Close();
/* The following code
de-serializes an instance of a Point class from
a file stream */
// Create a binary formatter that will deserialize a Point
object from a file stream
BinaryFormatter bf = new BinaryFormatter();
Stream stm = new
FileStream( "data.dat", FileMode.Open );
// Now deserialize the point object from the file stream
Point pt= null;
pt = (Point)bf.Deserialize( stm );
// Cleanup
stm.Close();
How does Deserialize() know what type of class the stream is holding? The Serialize() method places in the stream the name of the assembly, the complete name of the class, its version, the names of the fields that have been serialized, and finally, the values of those fields. You can use a hex viewer to view the results of the serialization in the file data.dat.
The serialization infrastructure is powerful because it has access to non-public members of the class. You too can access such members using the FormatterServices class but the code must have the SecurityPermissionFlag.SerializationFormatter permission. This class has a method called GetObjectData() that will return all the values of the specified members.
During deserialization, the formatter needs to know if the object in the stream has already been deserialized (a back reference) or not (a forward reference). When an object is being deserialized, the formatter can ask a runtime object called the ObjectManager if it knows about that object by passing it a reference ID to a function called GetObject(). If the ObjectManager knows about the object being deserialized, it will return the object's value, otherwise, it will return null. When the ObjectManager does not know about the object being deserialized, the formatter can deserialize the object and pass the ObjectManager the reference ID to that it is known to the ObjectManager for future reference.
If you want to control the data that is put into the stream and read out of the stream - essentially bypassing the use of the serialization metadata - you have to implement the ISerializable interface on your object. This interface has a single method called GetObjectData() which allows you to determine the information that is serialized into the stream. Your implementation of this method should write the data it wants serialized into the SerializationInfo object which is a parameter to GetObjectData(). ISerializable is unusual because it requires a implementing the ISerializable interface and a specific constructor:
public class MyObject : ISerializable
{
// Data members
private string str;
// Specific constructor. Must be added
when implementing ISerializable
internal MyObject(SerializationInfo info,
StreamingContext context)
{
str = info.GetString( "__str"
);
}
// ISerializable implementation
public void GetObjectData(SerializationInfo info,
StreamingContext context)
{
info.AddValue( "__str",
str);
}
}
Before discussing remoting, it is worth while listing some of the problems of DCOM that .NET remoting attempts to solve:
In .NET there are three ways to access a component remotely:
The choice of the type of remoting to use is based on several criteria:
Note the following points:
Client-activated objects are registered as such using RegisterActivatedServiceType() which is passed the type of the object that can be created remotely by the client:
// Server-side code to register a
client-activated object
ChannelServices.RegisterChannel( new TcpServerChannel(4000)
);
RemoteConfiguration.RegisterActivatedServiceType( typeof(MyClass)
);
// The following code is required to block the main
thread. Without it, the application will finish and
// the channel will stop listening. Requests for object activation will come
through the process thread pool
// so they will be handled by a thread other than the main thread
Console.WriteLine( "Press a key to stop this server
application" );
Console.ReadLine();
When a request from a client comes on the channel, the Framework can check whether the requested type is registered, and if so, create the object. The object is then assigned a URI and information about this URI is returned to the client, where the remoting infrastructure will create an ObjRef object. The client does not see the URI, it just sees and uses a proxy object. The client can still access the URI using RemotingServices.GetObjectUri() method.
Note also that the remote object class can also be implemented in a separate assembly, as long as the assembly metadata is available during compilation and the assembly is accessible at runtime.
When a class is registered on the server, the server will add it to a list of registered classes that it maintains. You can access this list using RemotingConfiguraiton.GetRegisterdActivatedServiceTypes() which returns an array of ActivatedServiceTypeEntry objects. Each of these objects has information about the class type and assembly, as well as a list of the context attributes of the type.
If the remote class is in a separate assembly, the client-side administration is easy: All you have to do is make that assembly accessible to the client assembly so that the client can access the metadata. If distributing the remote object's assembly is a problem, you have two options:
The client needs to activate the object, and to do so, it must specify the location of the remote object. RegisterActivatedClientType() does this by associating a type with he URI where the object can be found:
// Client-side code to activate a
remote object. Note that the port 4000 is where the server is listening.
RemotingConfiguration.RegisterActivatedClientType( typeof(MyClass),
"tcp://SOME_MACHINE_NAME:4000");
// Now instantiate and use the remote object. When you use
the managed 'new' operator, the runtime will make
// the activation request through the specified channel. When the server has
created the object, the client
// will have a unique URI beneath the activation URI, and this URI will be
returned through an ObjRef instance
MyClass remoteObject = new MyClass();
remoteObject.Foo();
The above explained client and server registration of client-activated objects using code. Client and server registration of client-activated objects can also be achieved using configuration files. Configuration files are not automatically loaded, so you have to tell the runtime which file to load. Here is an example of a server-side configuration file:
<!-- The following code indicated
that the application identified by Server has TCP channel on port 4000 and will
allow clients to activate instanced of MyClass in the MyAssembly assembly -->
<Configuration>
<system.runtime.remoting>
<application
name="Server">
<service>
<activated type="MyClass, MyAssembly"/>
</service>
<channels>
<channel type="Sytem.Runtime.Remoting.Channels.Tcp.TcpChannel,
System.Runtime.Remoting" port="4000"/>
</channels>
</application>
</system.runtime.remoting>
</Configuration>
// The new server code looks like
this
RemotingConfiguraiton.Configure( "myserver.config" );
Console.WriteLine( "Press a key to stop this server application" );
Console.ReadLine();
Because the information about the types that will be available through the server is given by the configuration file, the server can be compiled without the object's metadata. This means that you can write a generic server and determine the available classes at deployment time.
In the above code, all the Configure() method does is read the configuration file and use the information to call the appropriate RemotingConfiguration method. This is deliberate so that you can use whatever mechanism you choose for determining which object are available as remote objects. Configuration files are convenient where there only a few classes to configure. A system that makes many object available could store the information in a database and register them in code.
On the client side, the configuration file is similar:
<Configuration>
<system.runtime.remoting>
<application
name="Client">
<client
url="tcp://localhost:4000">
<activated type="MyClass, MyAssembly" />
</client>
</application>
</system.runtime.remoting>
</Configuration>
This time we do not need to use the channel collection because the url attribute of the client specifies enough information for the runtime to create the channel to the server activator object. The client code is also straightforward:
// Client-side code to activate a remote object
RemotingConfiguraiton.Configure( "myclient.config" );
MyClass remoteObject = new MyClass();
remoteObject.Foo();
When the object is created in the server, the server creates an ObjRef object that is returned back to the client to allow the client to find the actual object. The server maintains a map containing references to all of the objects that are accessed remotely, and the ObjRef objects that are used to access them. When a method request comes in, it will contain the information from the client ObjRef, and the remoting framework can use this map to ensure that the request goes to the correct object. When the server process dies, all the registered channels and objects will be releases and will no longer be available.
The difference between client-activated and server-activated objects is the initiation of the activation request: server-activated objects are created by the server, whereas client-activated objects initiate the request to an activator on the server, and the activator returns information that identifies the activated object and is used in the client to create the ObjRef. However, because server-activated objects do not use this extra step, the client cannot get the URI of the object from the server. To retrieve the URI, .NET registers the type on the server as being activated at a specific URI. This URI is known to both the server and the client, and because the client developer knows this URI, he/she can use it to access the server-activated object.
To use server-activated objects, you do have to have specialized knowledge about the object's URI, so server-activated objects could really be considered developer-known rather than well-known.
There are two types of server-activated objects:
The server should register the channel and the class. This can be accomplished using either code or a configuration file. Examples are given below:
/* The following code register
MyClass class as a single-call server-activated object. And because this object
is well known, you also have to provide a URI for the class */
ChannelServices.RegisterChannel( new TcpChannelService(4000) );
RemotingConfiguration.RegisterWellKnownServiceType( typeof(MyClass), "MyClassURI",
WellKnownObjectMode.SingleCall);
Console.WriteLine( "Press a key to stop this server application" );
Console.ReadLine();
<Configuration>
<system.runtime.remoting>
<application
name="Server">
<service>
<wellknown mode="SingleCall" type="MyClass, MyAssembly"
objectUri="MyClassURI" />
</service>
<channels>
<channel type="Sytem.Runtime.Remoting.Channels.Tcp.TcpChannel,
System.Runtime.Remoting" port="4000"/>
</channels>
</application>
</system.runtime.remoting>
</Configuration>
On the client side, you have three options:
/* Option 1: Use
Activator.GetObject() */
MyClass c = (MyClass)Activator.GetObject(typeof(MyClass), "tcp://localhost:4000/MyClassURI")
c.Foo();
/* Option 2: Register the
object on the client side as a well-known object. This means that the remote
object must be instantiated using the managed new operator */
RemotingConfiguration.RegisterWellKnownClientType( typeof(MyClass), "tcp://localhost:4000/MyClassURI");
MyClass c = new MyClass();
c.Foo();
/* Option 3: Use a
configuration file */
<application name="Client">
<client
<wellknown type="MyClass,
MyAssembly" url="tcp://localhost:4000/MyClassURI" />
</client>
</application>
Note that the call to Activator.GetObject() or new does not activate the object, instead, the client gets a proxy object. A network connection is made only when a method is called through the proxy, and if the object is a single-call, it is destroyed after the method completes.
When you register a client channel, it is just that - a channel used to send messages to the server. If the remote server object makes callbacks to the client, the client itself acts as a server and must register a server channel.
Assume we have the following class:
public delegate void CallBack(string s);
public class MyClass : MarshalByRefObject
{
public void CallYou() { ... }
public void CallYou( CallBack d ) { ... }
}
For a client-activated object, the client configuration file must have a <channels> collection in the <application> node. If the client is run on the same machine as the server, it must have a different port from that of the server object:
<channels>
<channel port="4001" type="Sytem.Runtime.Remoting.Channels.Tcp.TcpChannel,
System.Runtime.Remoting"/>
</channels>
The client code looks like:
public class CalledObject : MarshalByRefObject
{
static public void CallMe( string s ) { /* The callback
function implementation */ }
public static void Main()
{
RemotingConfiguration.Configure(
"remote.config" );
MyClass c = new MyClass();
b.CalleMe( new
CallBack(CalledObject.CallMe) );
// ...
}
}
Recall that exceptions are serializable. This means that when an exception is generated in an application domain, it is transmitted by value from the application domain where it was generated to the calling application domain where it is rethrown. As a consequence, there will be two stack dumps: one on the server side, and one on the client side. There are several important ramifications here:
Note that the remote exception is caught on the thread where the remote object is executing before being serialized and returned to the client. This means that you cannot use the AppDomain.UnhandledException event on the server side to catch the exception.
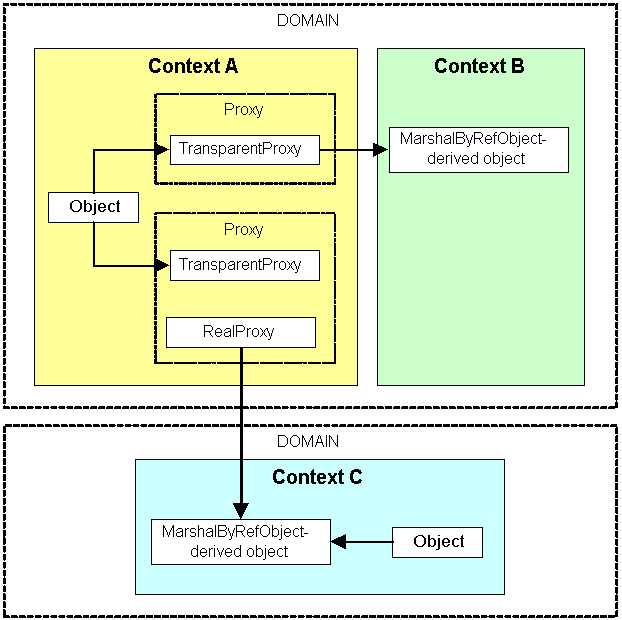
When a client gets a reference to an object of a class derived from MarshalByRefObject class, it actually gets a proxy object. This is true when the object is on a different machine from the client, or even if it is in a different application domain in the same process.
When a client makes an activation call or calls a method that return an object reference, what it will actually get is a reference to an object called a transparent proxy. The transparent proxy looks exactly like the remote object that is requested, but when the client makes a call through the transparent proxy, the runtime determines if the MarshalByRefObject object is in the same application domain as the client, and if so, the call foes directly to that object. If the object is in another application domain, the call is converted to a message (an object with an IMessage interface) and is passed to a RealProxy object. This object forwards the message to the MarshalByRefObject through the appropriate channel. This process is summarized below:
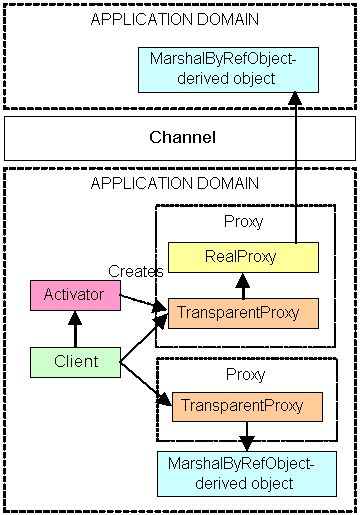
Note that if the object is server-activated, no network calls are made to obtain the reference to the transparent proxy. The only time that network calls are made is when the client accesses the object through a method call or a property access. For client-activated objects, the transparent proxy is returned from an activation request, which of course, requires a call to the remote application domain.
The transparent proxy is not extendable, but the RealProxy class is. You call determine if a reference is a transparent proxy by calling the static method RemotingServices.IsTransparentProxy(), and you can access the RealProxy object from a transparent proxy by calling the static method RemotingServices.GetRealProxy().
The proxy object has to know how to connect to the remote object, so it consults data in an ObjRef object. When an object reference is passed across a remoting boundary, the object reference is serialized into an ObjRef object by a call to RemotingServices.Marshal(). Some of the methods on ObjRef are virtual, meaning that you can extend ObjRef to hold custom marshaling data - yet another place where the remoting infrastructure is extensible.
The ObjRef object contains a URI that uniquely locates the remote object to which it refers. This URI is used to make the connection when the proxy object is created by unmarshaling the ObjRef object with a call to RemotingServices.Unmarshal(). Connecting to the remote object requires more than just the URI: the remote connection goes through a channel object that transmits method requests as messages, and information about this channel is held in the ChannelInfo property. The EnvoyInfo property holds information about the envoy chain which is a representation of the server context.
The server has no knowledge of the lifetime of a client-activated object. The client could hold on to the remote object reference for a short or a long time, or it could pass the reference to another object, meaning that the lifetime of the object is determined by two references. When the server creates the object, it does not know which of these two situations is appropriate. To complicate things further, the remote object could be accessed over a network that could be unreliable, so what might appear as a long object lifetime could actually be a broken network link.
.NET solves the issue of lifetime with leases. Each application domain has a lease manager that acts as the root for the lease and for remote objects as far as the garbage collector is concerned. Each remote object has a lease with an expiration time, and the lease manager has the responsibility of checking each lease to see if it has expired. It does this by maintaining a list of the leases in the order of the time left. When the lease expires, the lease manager contacts the sponsors of the lease to see if they want to renew. If they do not want to renew, the lease manager releases its reference on the lease and the object, thus allowing the garbage collector to collect them. The time between each check performed by the lease manager is set with LifetimeServices.LeaseManagerPollTime (default is 10 seconds)
There are several ways to set the lease time for an object:
<!-- The lease time for MyClass
is 30 seconds, and for all other objects it is 60 seconds -->
<system.runtime.remoting>
<application>
<lifetime leaseTime="60s"/>
<activated type="MyClass,
MyClassAssembly">
<lifetime
leaseTime="30s"/>
</activated>
</application>
</system.runtime.remoting>
When the timeout expires, the lease manager contacts the sponsors of the lease to see if they want to renew. A sponsor is a separate object that implements ISponsor. It could be a remote object which means that the lease manager will have to make a network call. There are two important issues here: 1) the network may not be reliable, so the lease manager could use a timeout value to determine if the sponsor was accessible and if it wasn't, contact the next sponsor on its list. 2) If the sponsor is remote, the application that hosts the sponsor must provide a channel to allow the lease manager to call back to the sponsor..
There are several ways to set the sponsor timeout: You can use the default value set by LifetimeServices.SponsorshipTimeout, or by the property of the same name on the object's least object, or you can set these values through the sponsorshipTimeout attribute of the <lifetime> node in the remoting configuration file. If no sponsor can be contacted, the object with the lease will be garbage collected.
The Framework provides a class called ClientSponsor that can be used as is for a sponsor. This class is intended to be used on the client side:
MyClass obj = new MyClass();
// When the lease expires, the lease manages will call
ClientSponsor to extend the lease by 5 minutes
ILease lease = (ILease)RemotingServices.GetLifetimeService( obj );
lease.Register( new ClientSponsor(TimeSpan.FromMinutes(5)) );
Here the sponsor is living in the same application domain as the client. This is not a requirement. The sponsor could live on another machine, possibly on the same subnet as the remote object to make lease manager's access to the sponsor more reliable.
Using a sponsor to keep a client-activated object alive means that the machine that has the sponsor is contacted only when the lease has expired. This is an improvement on the ping packet used by DCOM, but it still involves periodic network access., and it presents the developer with the dilemma of how big to make the lease time.
Another option is to assume that if a client calls the object, the network connection to the client still exists and therefore, the lease should remain until the next client call. This option is called renew on call: When a client makes a call, the lease time is set to the value of the property ILease.RenewOnCallTime.
Objects are called through messages sent via channels. Messages package method requests through the transparent proxy, which passes the message to the RealProxy object through its Invoke() method. The RealProxy object passes the message to the remote object via the channel, and in the process the message passes through message sinks, which are extensibility points. This process is summarized below:
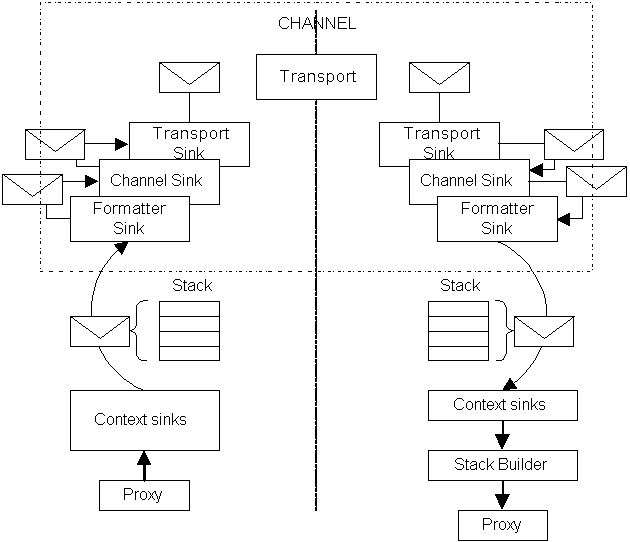
In effect, the transparent proxy serializes the stack resulting from the client call to a message object, and this stack is passed to the first message sink, which processes the message and then passes it to the next message sink in the chain. On the server side, the final message sink in the chain is the stack builder that deserializes the message and constructs a stack frame to call the remote object.
Message objects are passed from sink to sink as IMessage interface references., but they also support other message interfaces such as IConstructionCallMessage, IMethodCallMessage, etc.
Information can be added to a message through a message sink, which implements the IMessageSink interface. Each sink object has a reference to the sink sink in the chain, so it can perform its manipulation of the message - or another action - before passing the message to the next message sink. Sink objects pass messages by calling IMessageSink.SyncProcessMessage() for synchronous calls and IMessageSink.AsyncProcessMessage() for asynchronous calls.
Channels and their sinks must be registered before they can be used. Channels can registered using either ChannelServices.RegisterChannel() or a configuration file passed to RemotingConfiguration.Configure().
The Framework contains two channel classes: HttpChannel and TcpChannel (both client and server versions). The channels implement IChannel and either IChannelReceiver or IChannelSender. When a remote object is activated, a sink capable of communicating with the remote object is retrieved from the channel by a call to IChannelSender.CreateMessageSink(). This sink implements IMessageSink which is called by the remoting infrastructure to perform synchronous or asynchronous calls.
.NET remoting has been build with extensibility in mind. On the server side you can customize the ObjRef object (the distributed, serialized representation of the object), as well as the message sinks, channel sinks, formatters, and the channel itself:
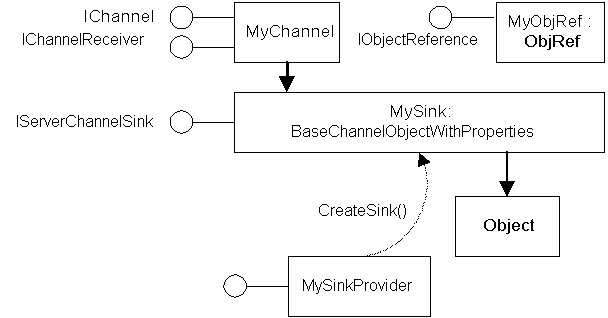
A custom channel implements IChannelReceiver which is called by the runtime to start listening on the custom channel, StartListening(), and then to stop listening, StopListening(). The channel should listen for client connections, and when a connection is made, handle the request. In addition, the receiver channel should provide access to its properties so that the runtime can query and set values. To do this, the channel must implement the IDictionary interface. To help, the Framework provides BaseChannelWithProperties, which has a basic dictionary implementation.
On the client side, you can customize the proxy, message sinks, channel sinks, formatters, and the channel itself:
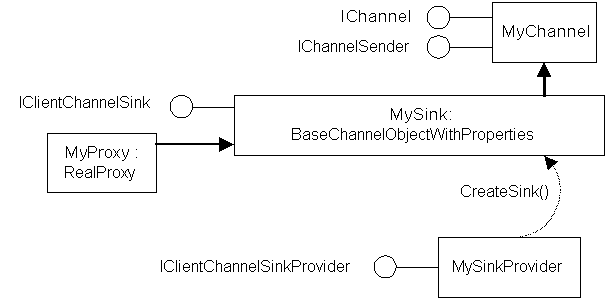
Note that you have to provide an implementation of CreateMessageSink(). This method is called by the Framework when the client attempts to activate the object. The object that is created will have a URI, and this and the message sink are returned from CreateMessageSink().
Remote objects present a whole series of security problems. Imaging the possible calls -
You could argue that the channel is a 'door' through which external code can access your machine. Therefore, it is very important that this 'door' be carefully regulated and that security be enforced to prevent an entry by a hacker.
The Framework class libraries that are involved in setting up and configuring remote channels (RemotingConfiguration, ChannelServices, and Context) all make code access checks. In effect, code that has full trust on your machine or on your local intranet, has permission to configure only channels and remote types, whereas only code that is fully trusted by the entire system can add code to the channel, message, and context sink chains.
Once the remoting channel has been created, the client will attempt to make activation calls, which travels along the channel. To ensure that the call is not hijacked, you will want to use authentication and possible a message digest. The simplest way to apply authentication is to use HttpChannel because this class uses IIS, which in turn can be configured to use authentication. HttpChannel can also support Secure Sockets Layer (SSL), but this means IIS must have an installed certificate. With the TcpChannel class you can use Internet Protocol Security (IPSec) to protect the channel.
If you use Windows authentication in IIS, your code will access the identity of the authenticated client through a WindowsIdentity object. This class also has properties to allow you to determine if the client is authenticated , and if so, what authentication was used.
.NET remoting allows you to add sinks into extensibility points, so you can design your own custom sinks that encrypt the contents of the message when it is being sent with sensitive data, and decrypt the data when a message is received by the server. If you use TcpChannel and you do not have access to IPSec, this is the only way to encrypt the contents of the channel packets.