The C# typing system contains the following three categories of types:
Value types directly contain their data whereas reference types store a reference (address) to their data. Note that with reference types it is possible for two variables to reference (point to ) the s ame object, and thus possible for operations on one variable to affect the value or the state of the object common to these two variables. With value-types, the variables each have their own copy of the data and it is not possible for operations on one value-type to affect another value-type.
Value-types directly contain their data, as opposed to reference types which contain an address or reference that points to the actual data. Value-types consist of two main categories:
Struct type
The struct types contain the following types:
Note the following features of value-types:
Value-types must be initialized before being used. Therefore, the following code gives a compile error:
int
nNum1; //
Not initialized
int nNum2 = nNum1; // Error
CS0165: Use of unassigned local variable 'Num1'
For simple types, the default value is the value produced by a bit pattern of all zeros. For an enum type, the default value is 0. And for a struct type, the default value is the value produced by setting all value-type fields to their default value and all reference-type fields to null.
There are many ways to initialize a value-type variable:
/* Different ways of initializing value-types
*/
// Decalre then initialize with new. Default constructor
is called and assigns default value to variable
int nNum1;
nNum1 = new int();
// Decalre then initialize with some value
int nNum2;
nNum2 = -1;
// Decalre and initialize with a default value. Default
constructor is called and assigns default value to variable
int nNum3 = new int();
// Declare and initialize with some value
int nNum4 = 100;
// Decalre and use user-defined value-types as above
MyPoint pt;
pt.x = 10;
A nullable type is a value type that can be assigned a null reference. Nullable types are instances of the System.Nullable struct. The ability to assign null to numeric and Boolean types is very useful when dealing with databases and other data types containing elements that may not be assigned a value. Any value type can be used as the basis for a nullable type.
The following code fragment illustrates features of nullable types:
private static void TestNullableTypes()
{
// Note the syntax for declaring
nullable values. Both forms are equivalent
int? nNum1 = null;
System.Nullable<int> nNum2 = null;
// Assigning an initial value
double? dNum1 = 10.0;
// Implicit conversion from double to double?
Nullable<double> dNum2 = dNum1;
// Nullable type have several new
methods to check for value. HasValue checks
// if nullable type has been assigned a value. If so, the
property Value is
// used to retrieve the nullable type's value
if (nNum1.HasValue)
// True if nNum1 is assigned a value. False if nNum1 is
null
Trace.WriteLine(nNum1.Value);
else
// Because
HasValue returned zero, the value of nNum1 is null
Trace.WriteLine("nNum1 is null");
// You can also test for null using
inequality operator
if (nNum1 != null)
Trace.WriteLine(nNum1.Value);
// System.Nullable.GetValueOrDefault()
can be used to return either the assigned value
// or the default value of the underlying type if the type's
value was null
int n1 = nNum2.GetValueOrDefault();
// n1 = 0 because nNum2 is null
double d1 = dNum1.GetValueOrDefault();
// d1 = 10.0 because dNum1 was previously assigned a value
// Note that a nullable type cannot be
assigned to a regule type. You have to used either
// casting or the value property
int n2 = nNum2;
// error CS0266: Cannot implicitly convert type 'int?' to
// int'. An explicit conversion exists (are you missing a cast?)
int n3 = (int)nNum2; // OK but
throws an exception if nNum1 is null
// The Value property throws
InvalidOperationException if the nullable type was null
try
{
short? sNum1 = null;
short s = sNum1.Value;
}
catch (InvalidOperationException ex)
{
Trace.WriteLine("sNum1 is null cannot
retrieve its value ");
}
// Using ?? operator defines a default
value that is returned when the nullable type
// is assigned to a non-nullable type
{
int? nNum = null;
int n = nNum ?? -1;
// n = nNum, unless nNum is null, in which case n = -1
// The ??
operator can also be used with multiple nullabe types
int? e = null;
int? f = null;
int g = e ?? f ?? -1;
// e or f, unless e and f are null, in which case g = -1
}
// Using operators: Predefine unary and
binary operators and any user-define operators that
// exist for value types may also be used by nullable types.
These operators produce a null
// value if the operand is null
{
int? a = 9;
int? b = null;
a++;
// a = 10
a = a + 10;
// a = 100
a = a * b;
// a = null because b is null
}
// Comparisons: When comparing nullable
types, if one of the nullable types is null, the
// comparison is evaluated to false. It is therefore
important NOT to assume that the opposite
// is true
{
int? a = 10;
int? b = null;
if (a > b)
Trace.WriteLine("a > b");
else
{
if (b.HasValue)
Trace.WriteLine("a < b ");
else
Trace.WriteLine("Undefined as b is null");
}
}
}
Nullable types can only be boxed if the value is non-null (i.e., HasValue is true). In this case, boxing takes place only if the underlying type the nullable object is based upon is boxed. Note that boxing a non-null nullable type boxes the underlying value itself, and not the System.Nullable that wraps the value type. If the nullable type is null (HasValue is false), then instead of boxing, the object reference is simply assigned null.
static private void
TestBoxingNullableTypes()
{
int? n1 = null;
object o1 = n1;
//because n1 is null, o1 is now null. There is no boxing
int? n2 = 10;
object o2 = n2;
// o2 contains a boxed int (and not a boxed nullable type)
// Boxed obejcts can be unboxed to
nullable types
int n3 = (int)o2;
}
The behaviour of nullable types when boxed provides two advantages:
Nullable objects and their counterparts can be tested for null.
bool? b = null;
object bBoxed = b;
if (b == null)
{
// True
}
if (bBoxed == null)
{
// Also true
}
Boxed nullable types full support the functionalities of the underlying type.
// Boxed nullable types
full support the functionalities of the underlying type.
int? n = 10;
object o = n;
// boxing
// Access IConvertible interface implemented by the boxed
variable
System.IConvertible ic = (System.IConvertible)o;
double d = ic.ToDouble(null);
C# provides a pre-define set of struct types called the simple types. The simple types are identified through reserved words (bool, int, short, etc.), but these reserved words are actually aliases for pre-defined struct types in the System namespace.
And because simple types are aliases for pre-defined struct types in the System namespace, every simple type has members. For example, int has members that are declared in System.Int32 and the members inherited from System.Object. Therefore, the following statements are permitted:
int i = int.MaxValue;
string s1 = i.ToString();
string s2 = 123.ToString();
Note that through the use of the const keyword, it is possible to create constants of simple types. It is not possible to have constants of other struct types, but a similar effect can be achieved using static readonly fields.
The char type is an alias for System.Char and is used to declare a Unicode character in the range U+0000 to U+fffff. Constants of the char type can be written as character literals, hexadecimal escape sequence or Unicode sequence. The char type is classified as an integral type but it differs from the other integral types in two ways:
char c1 =
'Y'; //
Character literal
char c2 = '\x0058'; //
Hexadecimal escape sequence
char c3 = '\u0058'; //
Unicode sequence
char c4 = char(88); //
Cast from integral type
byte is an alias for System.Byte and it refers to unsigned 8-bit numbers (0 - 255). When a literal is assigned to a byte, the literal will be implicitly converted from int to a byte as long as the value is less than 256, else a compile-time error is generated:
byte num1 = 267;
// Error:
value '267' cannot be converted to a 'byte'
byte num2 = 104;
// 104 is implicitly converted from int to byte.
You cannot implicitly convert non-literal numeric types of larger size to byte. In the code below, x + y expression is implicitly converted to an int. But you cannot assign a non-literal numeric type of larger size to a byte. Hence a compile-time error:
byte x = 10;
byte y = 20;
byte z = x + y;
// Error:
Cannot implicitly convert from type 'int' to type 'byte'
byte z2 = (byte)(x + y) // OK
sbyte is an alias for System.SByte and it refers to signed 8-bit numbers (-128 - 127). When a literal is assigned to an sbyte, the literal will be implicitly converted from int to a byte as long as the value is between -128 and 127, else a compile-time error is generated:
sbyte num1 = 200;
// Error:
value '200' cannot be converted to a 'sbyte'
sbyte num2 = 100;
// 100 is implicitly converted from int to s byte.
You cannot implicitly convert non-literal numeric types of larger size to sbyte. In the code below, x + y expression is implicitly converted to an int. But you cannot assign a non-literal numeric type of larger size to an sbyte. Hence a compile-time error:
sbyte x = 10;
sbyte y = 20;
sbyte z = x + y;
// Error:
Cannot implicitly convert from type 'int' to type 'sbyte'
sbyte z2 = (sbyte)(x + y) // OK
A short is an alias for System.Int16 and denotes an integral type that stores 16-bit integers. In the following, the literal 1234 is implicitly converted from int to short. If the integer literal did not fit into short, a compile-time error would be generated:
short s = 1234; // 1234 is implicitly converted from int to short
Note however that you cannot implicitly convert non-literal numeric types of larger size to short:
int n = 10;
short s = n; //
Error. Cannot
implicitly convert type 'int' to 'short'
Note that there is a predefined implicit conversion from short to int, long, float, double, or decimal.
short s1 = 10;
float f1 = s1; //
Implicit conversion of a short to a float.
A int is an alias for System.Int32 and denotes an integral type that stores signed 32-bit integers. Note that there is a predefined implicit conversion from int to long, float, double, or decimal.
float f1 = 10; // Implicit conversion of 10 from int to float.
Note however that you cannot implicitly convert non-literal numeric types of larger size to int:
long l = 10;
int n =
l; //
Error. Cannot
implicitly convert type 'long' to 'int'
Note that there is a predefined implicit conversion from int to long, float, double, or decimal.
int n1 = 10;
float f1 = n1; //
Implicit conversion of an int to a float.
An uint is an alias for System.UInt32 and denotes an integral type that stores unsigned 32-bit integers. You can use the U literal to indicate that the literal should be interpreted as wither uint or ulong (according to size):
uint u1 = 123U; // Assigning a numeric literal
There is a predefined implicit conversion from uint to long, ulong, float or double.
float f1 = 1234U; // Implicit conversion from uint to float
A long is an alias for System.Int64 and denotes an integral type that stores 64-bit integers. You can use the literal L to denote that the integral type is a long.
Note that there is a predefined implicit conversion from long to float, double, or decimal.
long lNum = 1234L;
float f1 = 10L; //
Implicit conversion of 10 from long to float.
int n1 = 10L; //
Error. No
implicit conversion from long to int.
An ulong is an alias for System.UInt64 and denotes an integral type that stores unsigned 64-bit integers. You can use the literals L, U, or UL to denote that the integral type is an ulong.:
Note that there is a predefined implicit conversion from ulong to float, double, or decimal.
long lNum = 1234L;
float f1 = 10L; //
Implicit conversion of 10 from long to float.
int n1 = 10L; //
Error. No
implicit conversion from long to int.
A double is an alias for System.Double and denotes a simple type that stores 64-bit floating-point values.
double d1 = 100.0; // By default, a real numeric literal is treated as double
double d2 = 100D; // Use 'D' suffix to treat an integral as a double
int n = 100;
double d3 = n; // You can mix numeric integral types and floating-point types.
A float is an alias for System.Single and denotes a simple type that stores 32-bit floating-point values. By default a real numeric literal on the right-hand side of an assignment expression is treated as a double. To initialize as a float, use the F prefix:
float f1 = 10.0; //
Error
float f2 = 10.0f; // OK
float f3 = 10; // OK
The bool keyword is an alias of System.Boolean. In C#, there is no conversion between a bool and other types. In other words, unlike C++, a bool in C# cannot be converted to a value of int where false means 0 and true means a non-zero value.
int n = 10;
if
(n)
// Error.
Cannot implicitly convert type 'bool' to 'int'
Trace.WriteLine( n );
int n = 10;
if (n >
0)
// OK.
Trace.WriteLine( n );
The decimal type is an alias for System.Decimal and denotes a 128-bit data type. Compared to floating-point type, a decimal has greater precision and smaller range making it suitable for financial and monetary calculations. To assign a literal to a decimal, use the m or M suffix, else, the number will be considered a float and a compile-time error will be generated
decimal dMoney1 =
1000.00m; //
Must use the 'm' suffix when assigning a float value
decimal dMoney2 =
1000; //
Because an integral type is implicitly converted to decimal, no need to use m
suffix
There is an implicit conversion between decimal and integral types but not floating types:
double f1 = 100.0;
int n1 = 200;
decimal d1 = f1;
// error CS0029: Cannot implicitly convert type 'double' to 'decimal'
decimal d2 = n1;
// OK
The enum keyword is used to declare an enumeration. An enum is a distinct type that consists of a set of named constants. Every enum type has an underlying type which can be any integral type except char. The default underlying type is int. To declare an enum:
[attributes] [modifiers] enum identifier [:base_type] { enumerator-list }; // See MSDN for details on enum declaration
Where [modifiers] can be:
By default, the first enumerator has a default value of 0 and each successive enumerator is increased by 1:
[HelpString("Some meaningful description")] public enum Colors { Red, Green, Blue }; // Red = 0, Green = 1, and Blue = 2
[HelpString("Some meaningful description")] public enum Colors { Red = 1, Green, Blue }; // Red = 1, Green = 2, and Blue = 3
[HelpString("Some meaningful description")] public enum Colors { Red, Green = 10, Blue }; // Red = 0, Green = 10 and Blue = 11
Enum members are named and scoped in a manner similar to fields within a class - The scope of an enum member is the body of the containing enum type. Within that scope, enum members can be referred to using their simple names. From all other code, the name of the enum member must be qualified with the name of its enum type. Also note that enum members do not have any declared accessibility.
Also note that you need to use a cast to obtain the underlying value. This is because each enum type defines a new distinct type. Conversion between an enum type and an integral type therefore requires an explicit cast:
public class MyClass
{
private enum Colors { Red, Green, Blue };
private enum Range : long { Max = 1000, Min = -1000 };
private void foo()
{
int nRed1 = Colors.Red;
// error CS0029: Cannot implicitly convert type 'Primer.Form1.colors' to
'int'
int
nRed2 = (int)Colors.Red; // OK. Note need to
qualify enum member with name of containing enum as well as casting
long lMax = (long)Range.Max;
// OK. Note need to qualify enum member with name of
containing enum as well as casting
...
}
...
}
Also note that the associated constant value with each enum member must be in the range of the underlying type:
enum Color : uint
{
Red =
0, // OK
Green = -1, //
Error. The underlying type is unsigned int
Blue = -2, //
Error. The underlying type is unsigned int
}
Finally, every enum type is derived from System.Enum class. Therefore, inherited members and properties of this class can be used on values of an enum type.
A struct type is a value-type that can contain constructors, constants, fields, methods, properties, indexers, operators, and nested types. A struct is similar to classes in that they represent data structures that can contain data members and function members. Unlike classes, structs are value types and do not require heap-allocation (recall that value type directly contain the data as opposed to reference type that contain a reference/address that points to the data.) Note that the simple types provided by C# like int, double, float and others are in fact all struct types. This means that you can use a struct and operator overloading to define new primitive types in C#.
To declare a struct:
[attributes] [modifiers] struct identifier [:interface] { body }; // See MSDN for details on struct declaration
Where [modifiers] can be:
The body of a struct can include any of the following declarations:
A struct object is suitable for representing lightweight objects that have value semantics such as Point, Rectangle and Color. Although it is possible to represent a Point as a class, a struct would be more suitable especially if you needed to create many Point objects. In this case, additional memory would have to be allocated for each Point object if Point was declared as a class. Hence, a struct is more suitable.
Some of the key points to observe when deciding to use a struct or a class are:
In C#, a class and a struct are semantically different from each other. A struct is a value type while a class is a reference type. Therefore, the recommended approach is - unless you need a reference-type semantics, a class that is smaller than 16 bytes is more efficiently handled by the system as a struct.
A default constructor is always provided automatically in a struct to initialize members to their default values. Therefore, it is an error to declare a default constructor in a struct. It is also an error to initialize an instance field in a constructor:
struct MyPoint
{
public int nX;
public int nY = 10; // error
CS0573: 'Primer.MyPoint.nY': cannot have instance field initializers in structs
public MyPoint() //
error CS0568: Structs cannot contain explicit parameterless constructors
{
nX = -1;
nY = -1;
}
}
A struct can be created with or without new. If a constructor is created with new, the struct gets created and the appropriate constructor gets called. If new was not used, the struct is created but cannot be used until its members have been initialized:
MyPoint pt1 = new MyPoint(); //
Appropriate (default) constructor called
MyPoint pt2 = pt1;
MyPoint pt3;
MyPoint pt4 =
p4;
// Error.
Use of assigned local variables
Note that a struct cannot be involved in inheritance except when inheriting from an interface. In other words, a struct cannot inherit from another class or struct. And it cannot be the base class of a class or a struct.
As a side-note, note the Managed C++ equivalents to a C# class and a C# struct:
| C# | Managed C++ |
| class | __gc class { ... }; __gc struct { ... }; |
| struct | __value struct { ... }; |
The following example illustrates:
public struct MyPoint
{
public int nX;
public int nY;
public MyPoint( int x, int y )
{
nX = x;
nY = y;
}
}
private void foo()
{
// Create initialized instances of MyPoint
MyPoint pt1 = new MyPoint();
// Compiles even though no default constructor was explicitly defined
MyPoint pt2 = new MyPoint( 10, 20 ); //
Calls the given constructro
// Create and then initialize an un-initialized struct
MyPoint pt3; //pt3
must be initialized before it can be used
pt3.nX = 10;
pt3.nY = 20;
}
A struct differs from a class in many important ways:
struct MyDictionaryEntry
{
// Data members
string strKey;
string strValue;
// Constructors
public MyDictionaryEntry( string key, string val )
{
strKey = key;
strValue = val;
}
// Properties
public string Key
{
get { return strKey; }
set { strKey = value; }
}
MyDictionaryEntry entry = new MyDictionaryEntry();
// Calls implicit default constructor
string strKey = entr.Key;
// return null
struct MyStruct
{
public int nNum;
public MyStruct(int n)
{
nNum = n;
}
public void GetThis( out MyStruct This )
{
This = this;
}
}
// Create a structure and initialize
it
MyStruct ob;
ob.nNum = 10;
// Create another structure but initialize it using the
previous structure instance
MyStruct ob2;
ob.GetThis( out ob2 );
int nNum = ob2.nNum;
public struct MyStruct
{
private int nNum = 10; //
error CS0573: 'Primer.MyStruct.nNum': cannot have instance field initializers in structs
}
Variables of reference types store references (addresses) to the actual data. Variables of reference types are referred to as objects .In NET, the following types are reference types:
Classes are discussed fully in Classes chapter.
An interface defines a contract. In other words, it declares members that must be implemented by other types that implement the interface. A class or struct or another interface that implements an interface must adhere to that contract by implementing all its methods. The interface itself does not provide any implementation at all. This approach is called interface-based programming.
An interface is closely related to an abstract class. However, an interface is a 'pure' contract - it cannot contain any sort of instance data whether public, private, or protected. Nor cannot it contain constructors/destructors or even operators which define how to apply expressions (+, -, etc) on instances. An abstract class on the other hand can contain all of the above and more, hence a class is more than a 'pure' contract.
The interface keyword declares a reference type that has abstract members. Declaring an interface takes the following form:
[attributes] [modifiers] interface identifier
[:base-list]
{
/* interface body */
} [;]
[modifiers] can be either new, public, protected, internal, or private. The new modifier is only permitted on nested interfaces and it specifies that the interface hides an inherited member by the same name. The remaining modifiers control the accessibility of the interface.
An interface can inherit from zero or more interfaces. These base interfaces are called the explicit base interfaces of the interface. The explicit base interfaces must be at least as accessible as the interface being declared. For example, you cannot specify a private or internal interface in the interface-base of a public interface.
The interface body defines the contract (i.e., the members) of the interface. The interface body can contain signatures of the following members which implicitly have public access:
An interface body cannot contain:
The following interface declaration contains one each of the possible kinds of members:
public interface ICar : IEngine, IChasis
{
void
Start();
// Method
int HorsePower { get;
}
// Property
event BatteryLow
stop;
// Event
int this[int index] { get; set;
} // Indexer
}
Note that the inherited members of an interface are not part of the interface's declaration space. In other words, an interface is allowed to declare a member with the same name or signature as an inherited member. When this occurs, the derived interface member is said to hide the base interface member. Hiding an inherited member is not an error but causes the compiler to issue a warning. The warning can be suppressed by applying the new modifier to the derived interface member to explicitly indicate that the derived interface member is intended to hide the base interface member.
A class or a struct is required in order to implement an interface. To implement an interface, the interface identifier must appear in the base class list of the class or struct.:
public class MyClass : SomeBaseClass, ICloneable, IEnumerable, I... { ... }
A class or a struct that implements an interface must also implement all of the interface's base interfaces:
public interface IControl
{
void foo();
}
public interface ITextBox : IControl
{
void bar();
}
class TextBox : ITextBox
{
// Must implement ITextBox interface
and all of its base interfaces
public void foo() { ...
} //
IControl implementation
public void bar() { ...
} //
ITextBox implementation
}
The following code demonstrates how to declare and implement an interface:
public interface IPoint
{
// Properties
int x
{
get;
set;
}
int y
{
get;
set;
}
}
public class MyPoint : IPoint
{
// Data fields
private int nX;
private int nY;
// Constructors
public MyPoint( int x, int y )
{
nX = x;
nY = y;
}
// IPoint Interface implementation
public int x
{
get { return nX; }
set { nX = value; }
}
public int y
{
get { return nY; }
set { nY = value; }
}
}
public void SomeTestFunction()
{
// Create a (0,10) point
MyPoint ob = new MyPoint(0,10);
// Set the x-coordinate to 10
ob.x = 10;
}
Explicit interface member implementation is a method, property, event, or indexer declaration in an implementing class (or struct) that references the fully qualified interface member name. For example:
public interface IControl
{
void foo();
}
class TextBox : IControl
{
// Explicit interface member
implementation
void IControl.foo() { ...
} // Note the absence of the public
access modifier
}
Explicit interface member implementations have the following properties:
Based on the above characteristics, explicit interface member implementations have two main purposes:
The following shows an example of implementing explicit interface members:
// Implements an interface using explicit interface member implementation
public interface IMetricPoint
{
// Properties
double x
{
get;
}
double y
{
get;
}
}
public interface IEnglishPoint
{
// Properties
double x
{
get;
}
double y
{
get;
}
}
public class MyPoint2 : IMetricPoint, IEnglishPoint
{
// Data fields
private double fMetricX;
private double fMetricY;
// Constructors
public MyPoint2( double x, double y )
{
fMetricX = x;
fMetricY = y;
}
/* IMetricPoint Interface implementation */
// Explicit interface member implementation
double IMetricPoint.x
{
get { return fMetricX; }
}
// Explicit interface member implementation
double IMetricPoint.y
{
get { return fMetricY; }
}
// Explicit interface member implementation
double IEnglishPoint.x
{
get { return fMetricX * 2.54; }
}
// Explicit interface member implementation
double IEnglishPoint.y
{
get { return fMetricY * 2.54; }
}
}
// When an interface member is explicitly implemented, it cannot be accessed through
// a class instance, but only through an interface instance
MyPoint2 ob2 = new MyPoint2(10.0,20.0);
// Access IMetricPoint.x and IMetricPoint.y through an interface
instance
IMetricPoint ptMetric = (IMetricPoint)ob2;
double xMetric = ptMetric.x;
double yMetric = ptMetric.y;
IEnglishPoint ptEnglish = (IEnglishPoint)ob2;
double xEnglish = ptEnglish.x;
double yEnglish = ptEnglish.y;
The process of locating implementations of interface members in an implementing class or struct is known as interface mapping. A class inherits all interface implementations provided by its base classes. This means that a derived class cannot change the interface mappings it inherits from its base classes. Consider the following code:
public interface IX
{
void foo();
}
public class X: IX
{
public void foo() {Trace.WriteLine("X.foo()");}
}
public class X2 : X
{
new public void foo() {Trace.WriteLine("X2.foo()");}
}
public interface IY
{
void foo();
}
public class Y : IY
{
public virtual void foo() {Trace.WriteLine("Y.foo()");}
}
public class Y2 : Y
{
public override void foo() {Trace.WriteLine("Y2.foo()");}
}
// interface implementation inheritance
X x = new X();
X2 x2 = new X2();
IX ix = x;
IX ix2 = x2;
x.foo(); //
X.foo()
ix.foo(); //
X.foo()
x2.foo(); // X2.foo()
ix2.foo(); // X.foo()
Y y = new Y();
Y2 y2 = new Y2();
IY iy = y;
IY iy2 = y2;
y.foo(); //
Y.foo()
y2.foo(); // Y2.foo()
iy.foo(); // Y.foo()
iy2.foo(); // Y2.foo()
A class that inherits an interface implementation is permitted to re-implement the interface by adding it in its base-class list. Consider the following:
// Interface re-implementation
public interface IZ
{
void foo();
}
public class Z : IZ
{
public void foo() {Trace.WriteLine("Z.foo()");}
}
public class Z2 : Z, IZ
{
public void foo() {Trace.WriteLine("Z2.foo()");}
}
Z z = new Z();
z.foo();
// Z.foo()
Z2 z2 = new Z2();
z2.foo();
// Z2.foo()
Z2 inherits the interface mapping established by Z which says that IZ.foo() is implemented in class Z. However, However, because Z2 added IZ interface to its base-class set, Z2 has effectively declared that it wants to re-implement IZ.
When a class implements an interface, it also implicitly implements all of the interface's base interfaces. Likewise, an interface re-implementation of an interface is also implicitly a re-implementation of all the interface's base interfaces. For example:
// base interface re-implementation
public interface IBase
{
void foo();
}
public interface IDerived : IBase
{
void bar();
}
public class Imp1 : IDerived
{
public void foo() { Trace.WriteLine("Imp1.foo()"); }
public void bar() { Trace.WriteLine("Imp1.bar()"); }
}
public class Imp2 : Imp1, IDerived
{
public void foo() { Trace.WriteLine("Imp2.foo()"); }
public void bar() { Trace.WriteLine("Imp2.bar()"); }
}
// base-interfaced re-implementation
Imp1 imp1 = new Imp1();
imp1.foo(); // Imp1.foo()
imp1.bar(); // Imp1.bar()
Imp2 imp2 = new Imp2();
imp2.foo(); // Imp2.foo()
imp2.bar(); // Imp2.bar()
Abstract and non-abstract classes must provide implementation of all members of the interfaces that are listed in the base-class list. However, an abstract class is permitted to map interface methods into abstract methods:
public interface IX
{
void foo();
void bar();
}
public class MyClass : IX
{
public abstract void foo(); //
Implementation of IX.foo() is mapped into an abstract method
public abstract void bar(); //
Implementation of IX.bar() is mapped into an abstract method
}
The difference between abstract classes and interfaces is discussed in more detail in Interfaces and Abstract Classes in Implementing Components.
A delegate declaration defines a reference type that can be used to encapsulate a method with a specific signature. In other words, a delegate is the equivalent of a C++ function pointer, however, C# delegate are nore powerful:
A delegate declaration is a type declaration that takes the form of:
[attributes] [modifiers] delegate result-type identifier ([parameters]);
[modifiers] can be either new, public, protected, internal, or private. The new modifier is only permitted for delegates declared within another type (say class or struct) and it specifies that the delegate hides an inherited member by the same name. The remaining modifiers control the accessibility of the delegate. result-type and parameters match the return type and the parameters, respectively, of the encapsulated method.
In general, there are three ways to instantiate a delegate:
// This class contains methods that
will be wrapped by a delegate
public class MyClass
{
public static int
MyStaticFunction( int x, int y );
public int MyInstanceFunction( int x, int y );
}
// Delegate for a function whose signature must be: int f(int, int)
private delegate int D( int, int );
// Tests creating delegates
private void btnDelegates_Click(object sender, System.EventArgs e)
{
// Instantiate a new delegate with a
static function
D d1 = new D( MyClass.MyStaticFunction);
// Instantiate a new delegate with an
instance function
MyClass ob = new MyClass();
D d2 = new D( ob.MyInstanceFunction );
// Instantiate a new delegate from
another delegate
D d3 = new D( d2 );
}
Note that a delegate declaration transparently defines a class that derives from System.Delegate. Therefore, a delegate declaration is an instance of a System.Delegate-derived class. Given a delegate instance and an appropriate set of parameters, one can invoke all of that delegate's instance methods with that set of parameters. An interesting and useful property of a delegate instance is that it does not know or care about the classes of the method that it encapsulates - all that matters is that the method's signature is compatible with the delegate declaration. This makes delegates ideal for 'anonymous' invocation. Delegate types are implicitly sealed, so it is not allowed to derive any type from a delegate type. Any operation that can be applied to a class or class instance can also be applied to a delegate class or delegate instance, respectively. In particular, you can access members of System.Delegate via the usual member access syntax.
The set of methods encapsulated by a delegate instance is called an invocation list. When a delegate instance is created from a single method, the delegate will encapsulate that single method, and its invocation list will only contain one entry. However, when two non-null delegate instances are combined into a new delegate, their invocation lists are concatenated to form a new invocation list that contains two entries. Note that the invocation lists of the delegates combined or removed remain unchanged. The following example shows how to declare, create, and use a delegate:
// Delegate for a function whose signature must be: int
f(int, int)
private delegate int D(int n1, int n2);
// The delegate function to be wrapped by a delegate of type D
private int foo(int n1, int n2)
{
return n1 + n2;
}
// This function takes a delegate and invokes the underlying function
private void bar( D d )
{
// Invoke the function wrapped by the
delegate passing the given arguments. Note that the
// delegate invocation returns the same value as the wrapped
function
int nSum = d(10, 20);
// Sum = 30
}
// Test function
private void btnDelegates_Click(object sender, System.EventArgs e)
{
// Instantiate a new delegate
D d = new D(foo);
// Pass the delegate to a function that
will invoke the delegate
bar( d );
}
When a non-null delegate instance whose invocation list contains only one method is invoked, it invokes the one method with the same arguments that the delegate was given, and returns the same value as the referred-to method. If an exception occurs during the invocation of such a delegate and the exception is not caught in the invoked method, the search for an exception catch clause continues in the method that called the delegate, as if that method had directly called the method referred to by the delegate.
Invocation of a delegate instance whose invocation list contains multiple entries proceeds by invoking each method in the invocation list synchronously and in the order in which those methods were added. Each method is passed the same set of arguments as was given to the delegate instance. If such a delegate instance includes reference parameters, each method invocation will occur with a reference to the same variable; changes to that variable by one method in the invocation list will be visible to methods down the chain. If the delegate function includes output or return values, the final value will come from the invocation of the last function in the list. If an exception occurs during the invocation of such a delegate and the exception is not caught in the invoked method, the search for an exception catch clause continues in the method that called the delegate, as if that method had directly called the method referred to by the delegate. Any methods further down the invocation list will not be invoked.
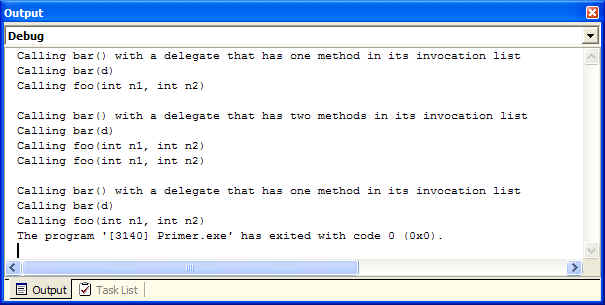
. Consider the following example. Output shown below:
private void btnDelegates_Click(object sender, System.EventArgs e)
{
// Instantiate a new delegate
Trace.WriteLine( "Calling bar() with a delegate that has one method in its invocation list");
D d1 = new D(foo);
bar( d1 );
// Instantiate another delegate
D d2 = new D(foo);
// Now combine delegates d1 and d2 into
d3. Note that the invocation lists of d1 and d2 remain unchanged
Trace.WriteLine( "\nCalling bar() with a delegate that has two methods in its invocation list");
D d3 = d1 + d2;
bar( d3 );
// Remove delegate d1 from d3. Note
that the invocation lists of d1 and d2 also remain unchanged
Trace.WriteLine( "\nCalling bar() with a delegate that has one method in its invocation list");
d3 -= d1;
bar( d3 );
}
Note: Although a delegate function can have an out parameter, it is not recommended to use it with multicast event delegates because there is no way to know which delegate will be called.
Both delegates and interfaces allow a class designer to separate type declarations and implementations. A given interface can be inherited and implemented by a class or a struct. Likewise, a delegate can be created for any method in a class as long as the method fits the delegate's signature. An interface reference or a delegate can be used by an object with no knowledge of the class that implements the interface of the delegate's method. Given these similarities, the following suggests when to use delegates and when to use interfaces.
Use delegates when:
An evebting pattern is desired.
You want to encapsulate a static method.
Caller has no need to access other properties, methods, or interfaces of the implementing object.
A class may need more than one implementation of method.
Use an interface when:
You have a group of methods that are logically related.
A class needs only one implementation of a method.
The class using that interface may want to cast that interface to other interfaces or class types.
The method being implemented is linked to the type or identity of the class (i.e., comparison methods).
A good example of using a single-method interface instead of a delegate is IComparable and IConvertible. For example, IComparable declares the CompareTo method which is used to compare two objects of the same type. IComparable is often used as the basis of a sort algorithm. While using a delegate comparison method as the basis of a sort algorithm would also work, it is not ideal simply because the ability to compare belongs to the class and the comparison algorithm does not change at run-time.
Covariance and contravariance relate to the degree of flexibility when matching a delegate methods with delegate signatures, in other words, how much can the method signature differ from the delegate signature? Note the following two distinctions:
Covariance allows a method with a derived return-type to be
used as the delegate method.
When a delegate method has a return type that is more derived than the
delegate signature, it is said to be covariant. Because the method's return
type is more specific than the delegate signature, it can be converted via the
IS-A inheritance relationship. Such a method is acceptable for use as a
delegate method.
Contravariance allows a method with derived parameters to be
used as the delegate method.
When a delegate method signature has one or more parameters whose types are
derived from the types of the method parameters, that method is said to be
covariant. Because the delegate method parameters are more specific than the
method parameters, they can be converted via the IS-A inheritance
relationship. Such a method is acceptable for use as a delegate method.
The following is an example:
// A base and a derived
class
public class Person
{
...
}
public class Programmer : Person
{
...
}
public class Variance
{
// define a delegate whose return type
is a base class
private delegate Person Locate();
private delegate void Process(Programmer ob);
public void TestCoVariance()
{
// Assign the
Locate delegate a method whose signature has a return type more
// derived than the return type of
the delegate, (the following two statements are
// equivalent -
just different syntax)
Locate del1 = new Locate(Search);
Locate del2 = Search;
}
public void TestContravariance()
{
// Assign the
Process delegate a method whose parameters are less derived
// than the parameters of the
delegate (the following two statements are
// equivalent - just different
syntax)
Process del1 = Hire;
Process del2 = new Process(Hire);
}
public Programmer Search()
{
return null;
}
public void Hire(Person ob)
{
...
}
}
Prior to C\ 2.0, delegates would only accept named methods. A named method is just a class member method with a specific signature. However, in a situation where creating a new method is undesirable and overhead, C# allows you to instantiate a delegate and specify a code block that the delegate will process when called. The following example illustrates:
class Delegates
{
private string strName = "Some
value";
private delegate void delTest1(int n);
public void Test1()
{
// d is an
outer or captured variable
double d = 10.0;
// Instantiate
an anonymous method
delTest1 d1 = delegate(int n)
{
Trace.WriteLine(n);
Trace.WriteLine(d);
};
// Call the
anonymous method
d1(1);
}
// A common use
of anonymous methods is when launching new threads without the need to
// create a class for the method
function
public void Test2()
{
// nValue is an
outer variable
int nValue = 10;
System.Threading.Thread t = new
System.Threading.Thread(
delegate()
{
// Note how we are usign a member variable
Trace.WriteLine(strName);
// Note how we are using an outer parameter
Trace.WriteLine( nValue );
// Do some other work
// ...
});
t.Start();
}
}
Note the following:
The scope of the parameter for an anonymous method is the anonymous-method block.
It is an error to have a jump statement (continue, break, goto) inside the anonymous-method block whose target is outside the block.
Local variables and parameters whose scope contains an anonymous method declaration are called outer or captured variables of the anonymous method (d in Test1 and nValue in Test2). Unlike local variables, the lifetime of outer variables extends until the delegates that reference the anonymous methods are eligible for destruction. For example, a reference to nValue in Test2 is captured at the time the delegate is created.
An anonymous method cannot access the ref and out parameters of the outer scope.
string is an alias for System.String and it represents a string of Unicode characters. Note that although string is a reference type, the equality operators (== and !=) are defined to compare the values of the string object and not the reference.
string a = "hello";
string b = "hello";
Console.WriteLine( a == b
);
// True. both a and b have the same value
Console.WriteLine( (object)a == (object)b ); //
False. both a and b are different objects
The object keyword is an alias for System.Object. You can assign values of any type to a variable of type object. All data types inherit from System.Object. The object data type is the data type to and from which objects are boxed.
object a =
1;
// boxing;
object b = new MyClass();
Boxing and unboxing is a central concept in the C# type system. They are used to provide a bridge between value-types and reference-types by allowing the conversion of value-types to reference types and vice-versa. Boxing and unboxing and therefore provide a unified view of the type system wherein a value of any type can be treated as an object.
Boxing is an implicit conversion of a value-type to the type object or to an interface type implemented by this value-type. Boxing a value allocates a new object instance and copies the value-type to this new object instance. Note that a boxed value of type T has a dynamic type T and the is operator is used to check the dynamic type:
int i =
123; // Declare
a value-type
object o = i; //
Implicitly convert value-type to reference type
if (o is int) //
Check dynamic type.
Console.WriteLine( "..." );
The statement object o = i implicitly creates a new reference-type on the stack that references a value of type int on the heap. This value is a copy of the value-type assigned to the variable i. The difference between the value-type i variable and the reference-type o variable is illustrated below:
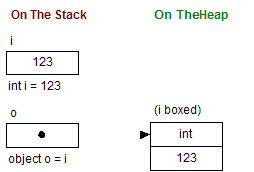
Note that boxing uses a copy of the value-type. This means that both the original value-type and the boxed value-type can be changed independently:
int i =
123; // i is
originally 123
object o = i; //
o which boxed i is also 123
i =
456; // i is now
456. object o remains 123 (because it has its own copy of i)
Unboxing is the complete opposite of boxing. Unboxing is the process of explicitly converting from the type object to a value-type or from an interface type to a value-type that implements that interface. An unboxing operation consists of:
int i =
123; //
A value-type
object o = i;
// boxing
int j = (int)o; //
unbxoing
The following diagram illustrates the unboxing process:
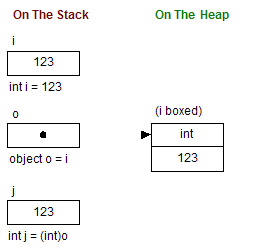
For an unboxing operation to succeed, the object to be unboxed (o in the above diagram) must a reference variable that was created by boxing a value-type. In other words, unboxing can only be applied to a variable created by a boxing operation. Otherwise, an InvalidCastException is thrown:
try
{
object o = 123;
// 123 literal is an int
int i = (short) o;
// operation fails
}
catch( System.Exception ex)
{
Trace.WriteLine( ex.Message );
}
TO DO ...