What is the difference between Multithreading programming and Parallel programming? To answer this question, consider first the definitions of a few key concepts:
Note that while you can implement partitioning and collating using standard locking techniques, it's awkward and can be difficult. Using the Parallel Framework in .NET will almost always be a better choice.
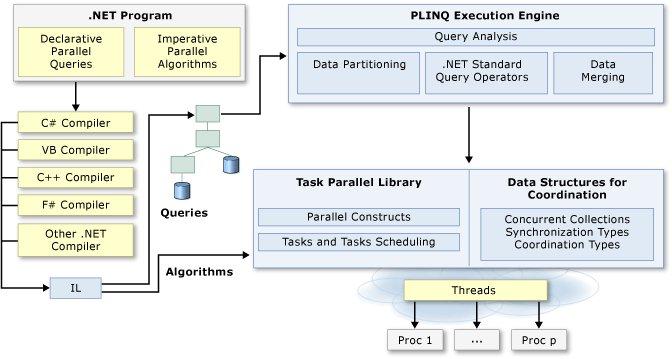
The following technologies are covered in this section and are collectively known as the Parallel Framework (PFX):
| Technology | Purpose |
| PLINQ | Useful for executing operations in parallel and then waiting for them to complete (structured parallelism). This includes non-CPU-intensive tasks such as calling a web service. |
| Parallel Class | |
| Task Parallelism constructs | Useful for running some operation on a pooled thread, and also to manage a task’s workflow through continuations and parent/child tasks. |
| Concurrent Collections | Appropriate when you want a thread-safe queue, stack, or dictionary. |
| SpinLock and SpinWait |
The primary use case for PFX is parallel programming: leveraging multicore processors to speed up computationally intensive code. Task Parallel Library (TPL) is a subset of PFX that comprises the Parallel Class and Task Parallelism constructs. A challenge in parallel programming is Amdahl's law, which states that the maximum performance improvement from parallelization is governed by the portion of the code that must execute sequentially. For instance, if only two-thirds of an algorithm’s execution time is parallelizable, you can never exceed a threefold performance gain — even with an infinite number of cores.
Therefore, it’s always worth verifying that the bottleneck is in parallelizable code. It’s also worth considering whether your code needs to be computationally intensive — optimization is often the easiest and most effective approach, however some optimization techniques make it harder to parallelize code.
There are two strategies for partitioning work among threads: data
parallelism and task parallelism.
When a set of tasks must be performed on many data values, we can parallelize by
having each thread perform the (same) set of tasks on a subset of values. This
is called data parallelism because we are partitioning the data between
threads. In contrast, with task parallelism we partition the tasks; in
other words, we have each thread perform a different task. Therefore,
data Parallelism
describes how to create parallel
for and
foreach
loops, while Task Parallelism describes how to create and run tasks either
implicitly using Parallel.Invoke or explicitly using
Task objects.
In general, data parallelism is easier and scales better because it reduces
or eliminates shared data thereby reducing contention and thread-safety
issues. Also, data parallelism leverages the fact that there are often more data
values than discrete tasks, increasing the parallelism potential. Data
parallelism is also conducive to structured parallelism, which
means that parallel work units start and finish in the same place in your
program. In contrast, task parallelism tends to be unstructured, meaning
that parallel work units may start and finish in places scattered across your
program.
PLINQ offers the richest functionality for automating all the steps of parallelization including partitioning work into tasks and collating the results into a single output sequence. In contrast, the other approaches are imperative, in that you need to explicitly write code to partition or collate. In the case of the Parallel class, you must collate results yourself, while with the task parallelism constructs you must partition the work yourself
| Technology | Partitions Work | Collates Results |
| PLINQ | Yes | Yes |
| Parallel Class | Yes | No |
| Task Parallelism | No | No |
The remaining two technologies, Concurrent Collections and Spinning primitives help you with your lower-level parallel programming activities. PLINQ and the Parallel class themselves rely on the concurrent collections and on spinning primitives for efficient management of work.
PLINQ automatically parallelizes local LINQ queries; it offloads the burden of both partitioning and collating to the Framework. To use PLINQ, simply call AsParallel() on the input sequence and then continue the LINQ query as usual. AsParallel is an extension method in System.Linq.ParallelEnumerable. It wraps the input in a sequence based on ParallelQuery<TSource>, which causes the LINQ query operators that you subsequently call to bind to an alternate set of extension methods defined in ParallelEnumerable. These provide parallel implementations of each of the standard query operators. Essentially, they work by partitioning the input sequence into chunks, executing them on different threads, and collating the results back into a single output sequence for consumption:
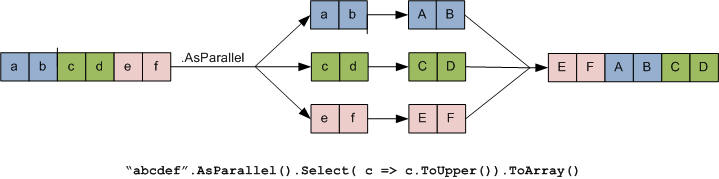
Note the following points:
// Calculate prime numbers between 3 and 50. Procedure: // a) for any given number n, calculate the square root of n and cast to int // b) Now check if the given number n is divisible by any of the numbers from 2 to w. public void TestSimplePLINQ() { // Create a test range IEnumerable<int> range = Enumerable.Range(3, 50 - 3); // Sequential prime number generator var primes = from n in range let w = (int) Math.Sqrt(n) where Enumerable.Range(2, w).All((i) => n % i > 0) select n; // Note sequence of output: // 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, foreach (var p in primes) Trace.Write(p + ", "); Trace.WriteLine(""); // Parallel prime number generator var primes2 = from n in range.AsParallel() let w = (int)Math.Sqrt(n) where Enumerable.Range(2, w).All((i) => n % i > 0) select n; // Note output is unordered // 5, 3, 23, 7, 31, 11, 47, 13, 17, 19, 29, 37, 41, 43, foreach (var p in primes2) Trace.Write(p + ", "); }
The following example illustrates basic PLINQ and some performance tips. In the code below, note that IndexedWord is a struct and not a class or an anonymous type; favouring stack-based allocations with parallel queries can improve performance; stack-based allocations are highly parallelizable as each thread has its own stack. If IndexedWord was a reference type (anonymous types are reference types) we'd incur the cost of heap-based allocation and garbage collection, but more importantly all threads must compete for the same heap. Note in the code below the use of ThreadLocal<T> when code is running in parallel (bUseParallel = true): The call to random.Next is not thread-safe, so it’s not as using AsParallel() on wordsToTest. One solution is to write a function that locks around random.Next; however, this would limit concurrency. The better option is to use ThreadLocal<Random> to create a separate Random object for each thread:
private const string WORDSFILE = "WorkLookup.txt"; internal struct IndexedWord { public string Word { get; set; } public int Index { get; set; } } public void TestSpellChecker() { // Load dictionary if not available if (!File.Exists(WORDSFILE)) new WebClient().DownloadFile("http://www.albahari.com/ispell/allwords.txt", WORDSFILE); // Read file into a hash set. Recall that a set is a collection that contains no duplicate elements, // and whose elements are in no particular order. A hash set implements set operations using a // a hash table HashSet<string> hs = new HashSet<string>(File.ReadAllLines(WORDSFILE), StringComparer.InvariantCultureIgnoreCase); // Create a test document consisting of a million random words List<string> lstWords = hs.ToList(); var range = Enumerable.Range(0, 1000000); bool bUseParallel = true; string[] wordsToTest; Random rand = new Random(111); if (!bUseParallel) wordsToTest = range.Select((i) => lstWords[rand.Next(0, lstWords.Count())]).ToArray(); else { var localRandom = new ThreadLocal<Random>(); localRandom.Value = new Random(1000); wordsToTest = range.AsParallel().Select((i) => lstWords[localRandom.Value.Next(0, lstWords.Count)] ).ToArray(); } // Introduce some spelling mistakes wordsToTest[100] = "adsf"; wordsToTest[200] = "qwerty"; // Perform parallel spell check. Cannot used indexed selection with query syntax // Need to use full syntax var q = wordsToTest.AsParallel(). Select((w, i) => new IndexedWord { Index = i, Word = w }). Where((word) => !hs.Contains(word.Word)). OrderBy((iw) => iw.Index); // Print results foreach (IndexedWord iw in q) Trace.WriteLine("Spelling error: " + iw.Word + " at location " + iw.Index); }
Because PLINQ runs query on parallel threads, be careful not to perform thread-unsafe operations by writing to variables. Writing to variables is side-effecting and is thread unsafe. Therefore, methods called from query operators should be thread-safe by not writing to fields or properties (non-side-effecting, or functionally pure). If they were thread-safe by using locking, the query's parallelism is limited.
public void TestSideEffecting() { // The following multiplies each element by its position. It is thread-unsafe // because it is parallel and writes to variable i. // Incrementing i using Interlocked does not work because i will not necessarily // correspond to the position of the input element. Using AsOrdered() won't fix // the problem too because AsOrdered ensures that elements are output in an order // AS IF they were processed sequentially even though elements are NOT processed // sequentially int i = 0; var v = from n in Enumerable.Range(0, 20).AsParallel() select (n * i++); // Output: 0,18,38,3,8,15,24,35,48,63,80,99,120,143,168,195,224,255,288,323, foreach (var item in v) Trace.Write(item + ","); Trace.WriteLine(""); // The following multiplies each element by its position in a thread-safe manner // using the indexed version of Select var v2 = Enumerable.Range(0, 20).AsParallel().Select((n, index) => n * index); // Output: 0,1,4,9,16,25,36,49,64,81,100,121,144,169,196,225,256,289,324,361, foreach (var item in v2) Trace.Write(item + ","); }
A query may be long running because it waits on something such as downloading or processing a file. PLINQ can effectively parallelize such queries, providing that you hint it by calling WithDegreeOfParallelism after AsParallel. WithDegreeOfParallelism(n) forces PLINQ to run n number of tasks simultaneously, otherwise PLINQ defaults to running a task per core. On a two-core machine, for instance, PLINQ may default to running only two tasks at once, which is clearly undesirable in this situation. For instance, suppose we want to ping four websites simultaneously. Rather than using clumsy asynchronous delegates or manually spinning up four threads, we can accomplish this effortlessly with a PLINQ query:
public void TestBlocking() { IEnumerable<string> sites = new[] { "www.diranieh.com", "www.bbc.co.uk", "www.amazon.co.uk", "", "www.youtube.com" }; // Run query on x threads where x = sites.Count() var pings = from site in sites.AsParallel().WithDegreeOfParallelism(sites.Count()) let p = new Ping().Send(site) select new { Site = site, Status = p.Status, RoundTripTime = p.RoundtripTime }; try { foreach (var p in pings) Trace.WriteLine(p.Site + ":" + p.Status + "/" + p.RoundTripTime); } catch (AggregateException ae) { foreach (Exception e in ae.InnerExceptions) Trace.WriteLine(e.Message); } }
To cancel a PLINQ query whose results are being consumed in a foreach statement, simply break out of the foreach loop. A query that terminates with a conversion, element, or aggregation operator can be cancelled from another thread with a cancellation token (OperatoinCancelledException thrown on the query's consumer). Note that upon cancellation, PLINQ does not pre-emptively abort threads, instead,PLINQ waits for each worker thread to finish with its current element before ending the query. This means that any external methods that the query calls will run to completion.
public void TestCancellation() { // Create a range on which to calculate prime numbers IEnumerable<int> range = Enumerable.Range(3, 100000); // Create a cancellation token var cancelSource = new CancellationTokenSource(); // Create a cancellable query that creates prime numbers var v = from n in range.AsParallel().WithCancellation(cancelSource.Token) let w = (int)Math.Sqrt(n) where Enumerable.Range(2, w).All((i) => n % i > 0) select n; try { // Cancel query. Note the use of a thread to cancel a cancellable query // by calling Cancel on the token source new Thread(delegate() { cancelSource.Cancel(); Trace.WriteLine("Query cancelled via thread"); }).Start(); // Start query Thread.Sleep(300); // Time to allow cancel thread to start int[] aPrimes = v.ToArray(); } catch (OperationCanceledException ex) // Note exception used { Trace.WriteLine(ex.Message); // Output: The query has been cancelled via the // token supplied to WithCancellation. } }
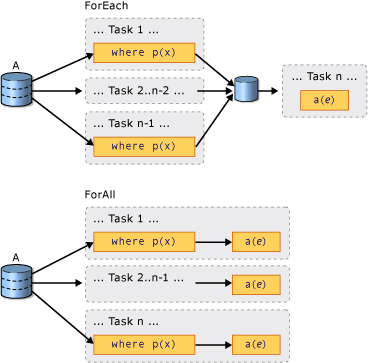
Recall that PLINQ collates results from parallelized work into a single output sequence. If all you need to do on that sequence is run a function over each element and you do not care about the order in which elements are processed, you can use ForAll to improve performance. ForAll runs a delegate over each output element bypassing the steps of collating and enumerating the results, as the following figure illustrates:
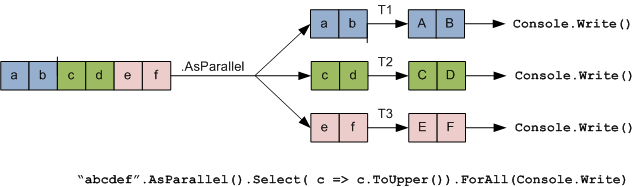
public void TestOptimizingLINQ_Basic() { // Output: BDFECAHJIGKML "abcdefghijklm".AsParallel().ForAll( (char (c) => Trace.Write(char.ToUpper(c))); }
PLINQ has three partitioning strategies to assign input elements to threads:
| Partitioning Strategy | Element Allocation | Relative Performance |
| Chunk | Dynamic | Average |
| Range | Static | Poor to Excellent |
| Hashing | Static | Poor |
For query operators that compare elements (GroupBy, Join, GroupJoin, Intersect, Except, Union, and Distinct), PLINQ always uses hash partitioning which is relatively inefficient since it must pre-calculate the hash code of every element (so that elements with identical hash codes can be processed on the same thread). If this is too slow, your only option is to call AsSequential to disable parallelization. For all other query operators you can use Range or Chunk partitioning: Range partitioning is faster with long sequences where every element takes a similar amount of CPU time to process. Otherwise, Chunk partitioning is usually faster. PLINQ chooses range partitioning if the input sequence is indexable (it's an array or implements IList), otherwise, PLINQ uses Chunk partitioning.
To force range partitioning, replace Enumerable.Range with ParallelEnumerable.Range or simply call ToList() or ToArray() on the input sequence. ParallelEnumerable.Range is not simply a shortcut for calling Enumerable.Range().AsParallel(). It changes the performance of the query by activating range partitioning. To force chunk partitioning, wrap the input sequence in a call to Partitioner.Create. The following figure shows how Chunk and Range partitioning are implemented:
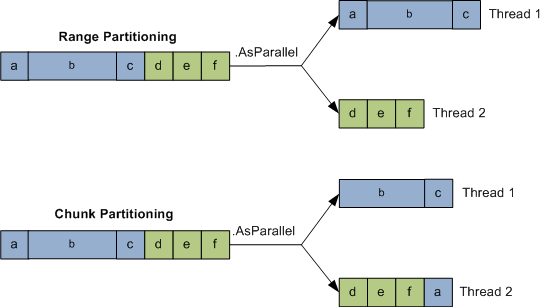
Chunk partitioning works by having each worker thread periodically grab small “chunks” of elements from the input sequence to process. PLINQ starts by allocating very small chunks (one or two elements at a time), then increases the chunk size as the query progresses: this ensures that small sequences are effectively parallelized and large sequences don’t cause excessive round-tripping. If a worker happens to get elements that process quickly, it will end up getting more chunks. This system keeps every thread equally busy. The only downside is that fetching elements from the shared input sequence requires synchronization (typically an exclusive lock) — and this can result in some overhead and contention.
Range partitioning bypasses the normal input-side enumeration and pre-allocates an equal number of elements to each worker, avoiding contention on the input sequence. But if some threads happen to get easy elements and finish early, they sit idle while the remaining threads continue working. Our earlier prime number calculator might perform poorly with range partitioning.
public void TestOptimizingLINQ() { // Test data int[] numbers = {1,2,3,4,5,6,7,8,9}; // Chunk partitioning: Partitioner provides common partitioning strategies for arrays, // lists, and enumerables. Partitioner.Create<int>( numbers, true).AsParallel().ForAll( (n) => Trace.WriteLine("Number " + n)); // Range partitioning: Faster with long sequences where each element requires a similar amount // of CPU time. Recall. Note that ParellelEnumerable.Range returns a ParallelQuery<T> so you do // not need to call AsParallel int nSum = ParallelEnumerable.Range(1, 10000).Sum(); }
PLINQ parallelizes the Sum, Average, Min, and Max operators without additional intervention. The Aggregate operator however presents special challenges. You can think of Aggregate as a generalized version of Sum, Average, Min, and Max - in other words, an operator that lets you plug in a custom accumulation algorithm for implementing unusual aggregations. The advantage of Aggregate is precisely that large or complex aggregations can be parallelized declaratively with PLINQ.
TSource Aggregate<TSource>(Func<TSource, TSource, TSource> func) : Aggregate works by calling Func one time for each element in source. Each time Func is called Aggregate passes both the element from the sequence and an aggregated value (as the first argument to Func). The first element of source is used as the initial aggregate value. The result of Func replaces the previous aggregated value. Aggregate returns the final result of Func. The following demonstrates how Aggregate can do the work of multiply:
public void TestBasicAggregate() { int[] numbers = { 1, 2, 3 }; int nInitValue = 0; // The first argument is the seem, the value from which accumulation starts. The second argument // is an expression to update the accumulated value, given a fresh element. You can optionally // supply a third argument to project the final result value from the accumulated value int nTotal = numbers.Aggregate(nInitValue, (total, n) => total * n); // nTotal = 0*1*2*3 = 0 // You can omit the seed value when calling Aggregate, in which case the first element becomes // the implicit seed, and aggregation proceeds from the second element: int nTotal2 = numbers.Aggregate((total, n) => total + n); // // nTotal2 = 1*2*3 = 6 }
Un-seeded aggregation methods are intended for use with delegates that are commutative and associative. TODO: Define Associative and Commutative. If used otherwise, the result is either unintuitive or nondeterministic:
public void TestBasicAggregate2() { int[] numbers = new[] { 2, 3, 4 }; // (total, n) => total + n * n is neither associative nor communtative. Instead of calculating // 2*2 + 3*3 + 4*4 = 29, it calculates 2 + 3*3 + 4*4 = 27 int nSum = numbers.Aggregate((total, n) => total + n * n); // Fix 1 is to include 0 as the first element. it might give incorrect results if parallelized // because PLINQ leverages the function’s assumed associativity by selecting multiple elements as // seeds. For example, if we denote our aggregation function // f(total, n) => total + n * n // then LINQ to Objects would calculate f(f(f(0, 2),3),4), whereas PLINQ may do: f(f(0,2),f(3,4)) int[] numbers2 = { 0, 1, 2, 3, 4 }; int nSum2 = numbers.Aggregate((total, n) => total + n * n); }
There are two solutions. The first is to turn this into a seeded aggregation — with zero as the seed. The only complication is that with PLINQ, we’d need to use a special overload in order for the query not to execute sequentially. The second solution is to restructure the query such that the aggregation function is commutative and associative:
int sum = numbers.Select(n => n * n).Aggregate((total, n) => total + n);
For unseeded aggregations, the supplied delegate must be associative and commutative. PLINQ will give incorrect results if this rule is violated. Explicitly seeded aggregations ordinarily execute sequentially because of the reliance on a single seed. To mitigate this, PLINQ provides another overload of Aggregate that lets you specify multiple seeds via a seed factory function. For each thread, it executes this function to generate a separate seed, which becomes a thread-local accumulator into which it locally aggregates elements. You must also supply a function to indicate how to combine the local and main accumulators. Finally, this Aggregate overload expects a delegate to perform any final transformation on the result (you can achieve this as easily by running some function on the result yourself afterward). So, here are the four delegates, in the order they are passed:
The following is a simple example:
public void TestParallelAggregate() { IEnumerable<int> numbers = new[] { 1, 2, 3, 4 }; int nSum = numbers.AsParallel().Aggregate( () => 0, // seedFactory (localTotal, n) => localTotal + n, // updateAccumulatorFunc (mainTot, localTot) => mainTot + localTot, // combineAccumulatorFunc finalResult => finalResult); // resultSelector }
Note that in simple scenarios, you can specify a seed value instead of a seed factory. This tactic fails when the seed is a reference type that you wish to mutate, because the same instance will then be shared by each thread.
// Another example of using Parallel aggregate: Calculate the frequency of each letter // for any given string public void TestParallelAggregate2() { string testString = "A test string to calculate frequency of each letter"; { // Non parallel case int[] result = testString.Aggregate(new int[26], (frequencies, letter) => { // Calcluate index of letter where 'A' is zero int nLetterIndex = char.ToUpper(letter) - 'A'; // Ensure we are only counting letters (i.e., ignore &, *, (, ... ) if (nLetterIndex >=0 && nLetterIndex <= 26) frequencies[nLetterIndex]++; return frequencies; }); // Parallel case { int[] nResult = testString.AsParallel().Aggregate( // New local accumulator () => new int[26], // Aggregate into local accumulator. localF is local to each thread. Note that // this local accumulation function mutates the localF array since localF is // local to each thread. Place a breakpoint on the first line of this lambda // expression open Parallel Tasks debug window: This lambda expression will be // called multiple times by multiple threads with localF being local to each // thread (localF, letter) => { // Calcluate index of letter where 'A' is zero int nLetterIndex = char.ToUpper(letter) - 'A'; // Ensure we are only counting letters (i.e., ignore &, *, (, ... ) if (nLetterIndex >= 0 && nLetterIndex <= 26) localF[nLetterIndex]++; return localF; }, // Aggregate all local frequencies to main frequency (mainF, localF) => { int[] aFinal = mainF.Zip(localF, (f1, f2) => f1 + f2).ToArray(); return aFinal; }, // Perform any required transformation. None in this case finalF => finalF); } }
Recall that when using the Parallel class, you must collate results yourself,:
| Technology | Partitions Work | Collates Results |
| PLINQ | Yes | Yes |
| Parallel Class | Yes | No |
| Task Parallelism | No | No |
The three main static methods in Parallel class are:
| Method | Purpose |
| Parallel.Invoke | Execute any number of delegates in parallel |
| Parallel.For | The parallel equivalent of C# for loop. Executes a single delegates against a sequence of numbers. |
| Parallel.ForEach | The parallel equivalent of C# foreach loop. Executes a single delegates against a sequence of numbers. |
Parallel.Invoke executes an array of Action delegates in parallel, and then waits (blocks) for them to complete. For example, to download multiple files at the same time:
// Note signatures: // public static void Invoke (params Action[] actions); // public static void Invoke(ParallelOptions options, params Action[] actions); Parallel.Invoke( () => new WebClient().DownloadFile("http://www.linqpad.net", "lp.html"), () => new WebClient().DownloadFile("http://www.jaoo.dk", "jaoo.html"));
Parallel.Invoke works efficiently if you pass in an array of a million delegates: :It partitions large numbers of elements into batches which it assigns to a handful of underlying Tasks rather than creating a separate Task for each delegate. As with all of Parallel’s methods, you’re on your own when it comes to collating the results. This means you need to keep thread safety in mind. The following is thread-unsafe:
var data = new List<string>(); Parallel.Invoke( () => data.Add(new WebClient().DownloadString("http://www.foo.com")), () => data.Add(new WebClient().DownloadString("http://www.far.com")));
Locking around adding to the list would resolve this, although locking would create a bottleneck. A better solution is to use a thread-safe collection such as ConcurrentBag.
Parallel.For and Parallel.ForEach perform the equivalent of a C# for and foreach loop, but with each iteration executing in parallel instead of sequentially:
public void TestBasicParallelForAndForeach() { // Sequential for. Output: 0 1 2 3 4 5 6 7 8 9 for (int i = 0; i < 10; i++) Trace.Write(i.ToString() + " "); // Parallel for. Note that output is unordered: 0 1 2 4 5 6 3 7 8 9 Trace.WriteLine(""); Parallel.For( 0, 10, (int i) => Trace.Write(i.ToString() + " ")); // Sequential foreach. Output: 0 1 2 3 4 5 6 7 8 9 Trace.WriteLine(""); IEnumerable<int> numbers = Enumerable.Range(0, 10); foreach (int n in numbers) Trace.Write(n + " "); // Parallel foreach. Note that output is unordered: 0 5 6 4 9 3 2 1 7 8 Trace.WriteLine(""); Parallel.ForEach(numbers, (int i) => Trace.Write(i.ToString() + " ")); }
Sometimes it is useful to know the index of the iteration which you can get using the following version of Parallel.ForEach:
public static ParallelLoopResult ForEach<TSource> ( IEnumerable<TSource> source, Action<TSource,ParallelLoopState,long> body)
We’ll ignore ParallelLoopState.For now, Action’s third type parameter of type long, indicates the loop index. The following example:
public void TestIndexedPartallelForEach() { IEnumerable<string> numbers = new [] {"One", "Two", "Three"}; Parallel.ForEach(numbers, (s, state, i) => Trace.WriteLine("Numner: " + s + " Index: " + i)); }
The following example re-implements the spell checker that was previously implemented via PLINQ:
public void TestSpellCheckerWithParallel() { // Load dictionary if not available if (!File.Exists(WORDSFILE)) new WebClient().DownloadFile("http://www.albahari.com/ispell/allwords.txt", WORDSFILE); List<string> lstWords = new List<string>(File.ReadAllLines(WORDSFILE)); // Create a document (list of words) List<string> lstDoc = new List<string>(lstWords.Take(50)); lstDoc[20] = "adsf"; lstDoc[30] = "qwerty"; // Create a contains to hold misspellings. Each item in the bag is a tuplle // consisting of an index (int) and the misspelled word (string) var misspellings = new ConcurrentBag<Tuple<long, string>>(); // Perform parallel spell check using indexed version of Parallel.ForEach Parallel.ForEach(lstDoc, (word, state, index) => { Trace.WriteLine( "( Thread ID " + AppDomain.GetCurrentThreadId() + "): " + word) ; if (!lstWords.Contains(word)) misspellings.Add( new Tuple<long, string>(index, word) ); }); // Print results foreach (var tuple in misspellings) Trace.WriteLine("Spelling error: " + tuple.Item2 + " at location " + tuple.Item1); }
Output is shown below .Note that the output is not ordered; the location of the spelling error in list below does not reflect its location in lstDoc list:
( Thread ID 6312): duelled ( Thread ID 3260): acknowledgement ( Thread ID 2588): counsellors ( Thread ID 3520): channeller's ( Thread ID 6312): dueller ( Thread ID 2780): autodialler ( Thread ID 3520): channellers ( Thread ID 3520): channelling ( Thread ID 3520): chiselled ( Thread ID 2588): crystalize ( Thread ID 6312): appal ( Thread ID 3260): acknowledgement's ( Thread ID 2588): crystalized ( Thread ID 3520): chiseller ( Thread ID 2588): crystalizer ( Thread ID 6312): appals ( Thread ID 2780): barrelled ( Thread ID 2780): barrelling ( Thread ID 3520): chisellers ( Thread ID 3520): qwerty ( Thread ID 6312): apparelled ( Thread ID 3260): acknowledgements ( Thread ID 2588): crystalizes ( Thread ID 2780): bevelled ( Thread ID 6312): archeological ( Thread ID 6312): archeology ( Thread ID 6312): cancelled ( Thread ID 3520): councilor's ( Thread ID 2588): crystalizing ( Thread ID 3260): archeologically ( Thread ID 2780): bevelling ( Thread ID 6312): adsf ( Thread ID 3260): archeologist ( Thread ID 3520): counselled ( Thread ID 2588): dialled ( Thread ID 2780): canalled ( Thread ID 3260): archeologist's ( Thread ID 3520): counselling ( Thread ID 6312): cancelling ( Thread ID 2780): canalling ( Thread ID 2588): dialler ( Thread ID 3520): counsellor ( Thread ID 6312): channelled ( Thread ID 3260): archeologists ( Thread ID 3520): counsellor's ( Thread ID 6312): channeller ( Thread ID 2588): dialling ( Thread ID 2588): draught ( Thread ID 2588): draught's ( Thread ID 2588): draughts Spelling error: qwerty at location 30 Spelling error: adsf at location 20
Because the loop body in a parallel For or ForEach is a delegate, you can’t exit the loop early with a break statement. Instead, you must call Break or Stop on a ParallelLoopState object. All versions of For or ForEach are overloaded to accept loop bodies of type Action<TSource,ParallelLoopState>:
public void TestLoopExit() { IEnumerable<int> numbers = Enumerable.Range(0, 20); // Sequential foreach (int i in numbers) { if (i > 9) break; Trace.Write("\t" + i); } // In parallel using Break Trace.WriteLine(""); Parallel.ForEach( numbers, (number, state) => { if (number > 10) state.Break(); Trace.Write("\t" + number); }); // In parallel using Stop // Calling Stop instead of Break forces all threads to finish right after their current iteration. Trace.WriteLine(""); Parallel.ForEach( numbers, (number, state) => { if (number > 10) state.Stop(); Trace.Write("\t" + number); }); } Output: 0 1 2 3 4 5 6 7 8 9 0 1 3 5 6 2 4 10 7 13 11 15 9 8 12 17 18 1 3 2 4 6 7 8 0 9 5 10 11
Note that the parallel For or ForEach methods return a ParallelLoopResult object that exposes properties called IsCompleted and LowestBreakIteration. These tell you whether the loop ran to completion, and if not, at what cycle the loop was broken. If LowestBreakIteration returns null, it means that you called Stop (rather than Break) on the loop.
The Parallel class and PLINQ are internally built using task parallelism constructs which are the lowest-level approach to parallelization. The classes for working at this level are defined in System.Threading.Tasks namespace and comprise the following:
| Class | Purpose |
| Task | Managing a unit for work. |
| Task<TResult> | For managing a unit for work with a return value of type TResult. |
| TaskFactory | For creating tasks. |
| TaskFactory<TResult> | For creating tasks and continuations with the same return type. |
| TaskScheduler | For managing the scheduling of tasks. |
| TaskCompletionSource | For manually controlling a task’s workflow. |
A task is a lightweight object for managing a parallelizable unit of work. A task avoids the overhead of starting a dedicated thread by using the CLR’s thread pool. Tasks provide the following features for managing units of work:
The following examples show various ways to create and start tasks:
public void TestBasicTask() { // The usual way to start a parallel task passing in the required delegate. Note the // use of a non-generic Task. Note that StartNew schedules the task for execution // by the task scheduler, and does not start it immediately, in other words, StartNew // returns immediately Task.Factory.StartNew(() => Trace.WriteLine("This is a test task")); // A generic task lets you get data from the task UPON COMPLETION. TResult in // StartNew<TResult> is the type of the return result Task.Factory.StartNew<string>(() => { // Download file from the web and return resdults... return "test file"; }); // As the tasks above are running, you can do other work // DoSomethingElse(); // Task.Factory.StartNew creates and starts a task in one step. You can decouple // these operations by first instantiating a Task object, and then calling Start: Task<string> task = new Task<string>(() => { // Read file from web and return results.... return "test data"; }); task.Start(); // RunSynchronously() instead of Start to run synchronously }
// When instantiating a task or calling Task.Factory.StartNew, you can specify // a state object, which is passed to the target method. This is useful should // you want to call a method directly rather than using a lambda expression. Note // also that the state can be retrieved in the task using Task.AsyncState public void TestTaskStateObject() { Task task = Task.Factory.StartNew((object state) => { // Do something with the state object .... Trace.WriteLine("state object: " + ((state != null) ? state.ToString() : "Null")); }, "Test Data"); Trace.WriteLine("task.AsyncState: " + task.AsyncState); }
You can tune a task’s execution by specifying a TaskCreationOptions enum when calling StartNew (or instantiating a Task). TaskCreationOptions is a flags enum with the following (combinable) values:
When one task starts another, you can optionally establish a parent-child relationship by specifying TaskCreationOptions.AttachedToParent. With child tasks when you wait for the parent task to complete, the parent task waits for its children as well. This can be particularly useful when a child task is a continuation (see next section).
public void TestCreateChildTasks() { // Create a task Task taskParent = Task.Factory.StartNew(() => { Trace.WriteLine("This line is written by parent task"); // Create a child task attached to this parent. Note the use of TaskCreationOptions.AttachedToParent Task taskChild = Task.Factory.StartNew(() => { Trace.WriteLine("This line is written by child task"); }, TaskCreationOptions.AttachedToParent); // Create a task not attached to this parent (i.e., a detached task) Task taskDetached = Task.Factory.StartNew(() => { Trace.WriteLine("This line is written by detached task"); }); }); }
You can explicitly wait for a specific task to complete in two ways:
You can also wait on multiple tasks at once the static methods Task.WaitAll (waits for all the specified tasks to finish) and Task.WaitAny (waits for just one task to finish). WaitAll is similar to waiting out each task in turn, but is more efficient in that it requires (at most) just one context switch. Also, if one or more of the tasks throw an unhandled exception, WaitAll still waits out every task and then rethrows a single AggregateException that accumulates the exceptions from each faulted task.
public void TestWaitingOnTasks() { // Create a parent task with a child task Task taskParent = Task.Factory.StartNew(() => { Trace.WriteLine("This line is written by parent task"); // Create a child task Task.Factory.StartNew(() => { // Throw an exception throw new Exception("Exception from child"); }, TaskCreationOptions.AttachedToParent); }); // Wait on parent task to finish - by accessing its Result property or calling // its Wait method. Note that any unhandled exceptions are conveniently rethrown // to the caller, wrapped in an AggregateException object. For parented tasks, // waiting on the parent implicitly waits on the children — and any child exceptions // then bubble up try { taskParent.Wait(); } catch (AggregateException ae) { Trace.WriteLine(ae.Message); } }
Note that TaskScheduler.UnobservedTaskException event provides a final last resort for dealing with unhandled task exceptions. By handling this event, you can intercept and handle task exceptions that would otherwise end the application — and provide your own logic for dealing with them. Finally, note that an alternative strategy for dealing with exceptions is with continuations.
You can optionally pass in a cancellation token when starting a task. This lets you cancel tasks via the cooperative cancellation pattern.
public void TestCancellingTasks() { // Setup cancellation token var cto = new CancellationTokenSource(); var ct = cto.Token; // Create and start a cancellable task. Task task = Task.Factory.StartNew(() => { // Do some work here... Thread.Sleep(1000); // Use the token created earlier to check if task has been cancelled ct.ThrowIfCancellationRequested(); // There was no cancellation request. Do some more work here... }); // StartNew schedules the task for execution and does not immediately start // running the task. So the following code can be used to simulate some other // function requesting task cancellation cto.Cancel(); // Wait on the task to finish. To detect a cancelled task, catch an AggregateException // and check the inner exception as follows try { task.Wait(); } catch (AggregateException ae) { if (ae.InnerException is OperationCanceledException) Trace.WriteLine("Task has been cancelled"); } }
If the task is cancelled before it has started, it won’t get scheduled — an OperationCanceledException will instead be thrown on the task immediately. Because cancellation tokens are recognized by other APIs, you can pass them into other constructs and cancellations will propagate seamlessly. See also PLINQ cancellations.
var cancelSource = new CancellationTokenSource(); CancellationToken token = cancelSource.Token; Task task = Task.Factory.StartNew (() => { // Pass our cancellation token into a PLINQ query: var query = someSequence.AsParallel().WithCancellation (token)... ... enumerate query ... });
Calling Cancel on cancelSource in this example will cancel the PLINQ query, which will throw an OperationCanceledException on the task body, which will then cancel the task.
Continuations are used when you want to start a task right after another one completes (or fails). Continuations are implemented using ContinueWith method:
public void TestSimpleContinuation() { // Start a simple task Task task1 = Task.Factory.StartNew(() => Trace.WriteLine("This is the first task")); Task task2 = task1.ContinueWith( (_task1) => { Trace.WriteLine("Antecedent task status: " + _task1.Status); Trace.WriteLine("This task continues (starts) after the first task"); }); // Wait for the task1 to be schedules and executed by the scheduler task1.Wait(); }
task1 is known as the antecedent task2 is known as the continuation. As soon as task1 finishes/fails/is cancelled, task2 automatically starts. If task1 had completed before ContinueWith was called, task2 would be scheduled to execute right away. The _task1 argument passed to the continuation’s lambda expression is a reference to the antecedent task.
Continuations are particularly useful if the antecedent task returns data that can be used by the continuation. Note that by default, antecedent and continuation tasks may execute on different threads. You can force them to execute on the same thread by specifying TaskContinuationOptions.ExecuteSynchronously when calling ContinueWith.
The following example shows how data returned antecedents can be used by their respective continuations. We calculate Math.Sqrt(20*5) using a series of chained tasks and then write out the result:
public void TestContinuationWithData() { // Create chained tasks Task<double> task = Task.Factory.StartNew<int>(() => 20). ContinueWith((antecedent) => antecedent.Result * 5). ContinueWith((antecedent) => Math.Sqrt(antecedent.Result)). ContinueWith((antecedent) => { Trace.WriteLine(antecedent.Result); return antecedent.Result; }); // Wait for tasks to return task.Wait(); }
A continuation can find out if an exception was thrown by the antecedent via the antecedent task’s Exception property. If an antecedent throws and the continuation fails to query the antecedent’s Exception property (and the antecedent isn’t otherwise waited upon), the exception is considered unhandled and the application dies (unless handled by TaskScheduler.UnobservedTaskException). A safe pattern is to rethrow antecedent exceptions. As long as the continuation is Waited upon, the exception will be propagated and rethrown to the Waiter:
public void TestContinuationWithException() { try { Task task = Task.Factory.StartNew(() => { // Lambda for this task fails and throws an exceptioj throw new ArgumentNullException("Some field is null"); }). ContinueWith((ant) => { // This continuation task must check for exceptions thrown by the antecedent // and rethrow then if (ant.Exception != null) throw ant.Exception; // No antecedent exceptions. Continue with logic.... }); // Wait for task to complete. Otherwise, you won't catch any thrown exceptions task.Wait(); } catch (AggregateException ae) { Trace.WriteLine(ae.Message); } }
Another way to deal with exceptions is to specify different continuations for exceptional versus non-exceptional outcomes. This is done with TaskContinuationOptions:
public void TestContinuationWithException2() { try { bool bTestThrow = true; Task task = Task.Factory.StartNew(() => { if (bTestThrow) // Lambda for this task fails and throws an exception. task childOnParentFault // task will then be called since its parent faulted. If logic for task // childOnParentFault throws an exception, the catch hanlder will be called throw new ArgumentNullException("Some field in parent task is null"); }); // Continuations Task childOnParentSuccess = task.ContinueWith((ant) => { // This continuation task does not need to check for exceptions thrown by // the antecedent as it is called only if the antecedent was not faulted. // No antecedent exceptions so continue with logic.... Trace.WriteLine("No parent faults. ant.IsFaulted: " + ant.IsFaulted); }, TaskContinuationOptions.NotOnFaulted); Task childOnParentFault = task.ContinueWith((ant) => { // This continuation task does not need to check for exceptions thrown by // the antecedent as it is called only if the antecedent was faulted. Trace.WriteLine("Parent faulted. ant.IsFaulted: " + ant.IsFaulted); // Logic for this task comes next. If this logic throws an exception // the catch handler will be called throw new ArgumentNullException("Some field in childOnParentFault task is null"); }, TaskContinuationOptions.OnlyOnFaulted); task.Wait(); } catch (AggregateException ae) { Trace.WriteLine(" Enter Exception Handler: "); foreach (Exception e in ae.InnerExceptions) Trace.WriteLine(e.Message); Trace.WriteLine(" Exit Exception Handler: "); } }
The following shows to use extension methods to swallow (ignore) exceptions from any task:
Task.Factory.StartNew (() => { throw null; }).IgnoreExceptions(); // IgnoreExceptions() is an extension method defined below
public static void IgnoreExceptions(this Task task) { // Add some logging to indicate what sort of exception task.ContinueWith(t => { var ignore = t.Exception; }, TaskContinuationOptions.OnlyOnFaulted); }
A powerful feature of continuations on a task that has child tasks is
that continuations kick off only when all child tasks have completed. At
that point, any exceptions thrown by the children are marshaled to the
continuation. In the following example, assume a parent task with a continuation
starts three child tasks with each throwing a NullReferenceException. We catch
all of the children's exceptions via a continuation on the parent:
public void TestContinuationWithChildTasks() { // Tasks with this option are attached to the containing task as children TaskCreationOptions tco = TaskCreationOptions.AttachedToParent; // Create a task with three children. Note the use of tco parameter Task taskParent = Task.Factory.StartNew(() => { Task.Factory.StartNew( () => {throw null;}, tco); Task.Factory.StartNew( () => {throw null;}, tco); Task.Factory.StartNew(() => { throw null;}, tco); }); taskParent.ContinueWith( (antecedent) => { Trace.WriteLine("Antecedent faulted: " + antecedent.IsFaulted); }, TaskContinuationOptions.OnlyOnFaulted); taskParent.ContinueWith( (antecedent) => { Trace.WriteLine("Antecedent faulted: " + antecedent.IsFaulted); Trace.WriteLine("Antecedent completed: " + antecedent.IsCompleted); }, TaskContinuationOptions.NotOnFaulted); }
The following diagram shows when continuations are kicked off for various scenarios:
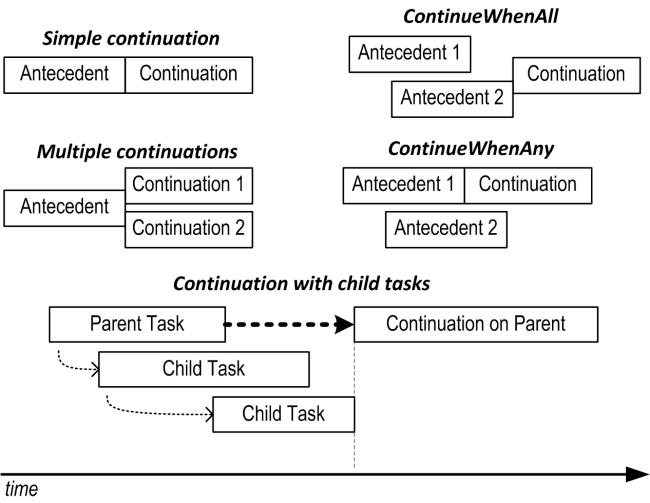
By default, continuations are scheduled unconditionally; whether the antecedent completes, throws an exception, or is cancelled. This behavior can be changed via a set of combinable flags included within the TaskContinuationOptions enum. The three core flags that control conditional continuation are:
NotOnRanToCompletion = 0x10000,
NotOnFaulted
= 0x20000,
NotOnCanceled
= 0x40000,
These flags are subtractive in the sense that the more you apply, the less likely the continuation is to execute. For convenience, there are also the following pre-combined values:
OnlyOnRanToCompletion = NotOnFaulted
| NotOnCanceled,
OnlyOnFaulted =
NotOnRanToCompletion | NotOnCanceled,
OnlyOnCanceled = NotOnRanToCompletion | NotOnFaulted
It's important to know that when a continuation task CT1 does not execute as a result of any of these flags, the continuation is cancelled. This means that any continuations on CT1 will run unless these continuations are specified with NotOnCanceled.
Task t1 = Task.Factory.StartNew (...); // If t1 succeeds, fault task will be cancelled. fault runs only if t1 is faulted (throws an exception) Task fault = t1.ContinueWith (ant => Console.WriteLine ("fault"), TaskContinuationOptions.OnlyOnFaulted); // t3 will execute unconditionally irrespective of fault Task t3 = fault.ContinueWith (ant => Console.WriteLine ("t3")); // t4 will execute only if fault actually runs Task t4 = fault.ContinueWith (ant => Console.WriteLine ("t4"), TaskContinuationOptions.NotOnCanceled);
Continuations can be scheduled to execute based on the completion of multiple antecedents. ContinueWhenAll schedules execution when all antecedents have completed; ContinueWhenAny schedules execution when one antecedent completes
public void TestContinuationsWithMultipleAntecedents() { Task<int> t1 = Task.Factory.StartNew<int>(() => 100); Task<int> t2 = Task.Factory.StartNew<int>(() => 200); Task<int> c1 = Task.Factory.ContinueWhenAll(new Task<int>[] {t1, t2}, (tasks) => { int nSum = tasks.Sum((t) => t.Result); return nSum; }); Trace.WriteLine(c1.Result); }
A task scheduler allocates tasks to threads. All tasks are associated with a task scheduler, which is represented by the abstract TaskScheduler class. The .NET Framework provides two concrete implementations:
The following example suppose we wanted to fetch data from some WCF service and then update UI in a WPF application. This can be done using tasks as follows:
public partial class MyWindow : Window { // Declare the task scheduler as a field that can be used throughout our class. TaskScheduler _uiScheduler; public MyWindow() { InitializeComponent(); // Get the UI scheduler for the thread that created the form: _uiScheduler = TaskScheduler.FromCurrentSynchronizationContext(); Task.Factory.StartNew<string>( GetDataFromWCF ) .ContinueWith(ant => lblResult.Content = ant.Result, _uiScheduler); } string GetDataFromWCF() { ... } }
Consider the static Factory property:
Task t1 = Task.Factory.StartNew (...);
Task.Factory returns a default
TaskFactory object. TaskFactory
is not an abstract factory: you can actually instantiate the class, and this is
useful when you want to repeatedly create tasks using the same (nonstandard)
values for TaskCreationOptions,
TaskContinuationOptions, or TaskScheduler.
For example, if we wanted to repeatedly create long-running parented tasks, we
could create a custom factory and then use this factory to create out customized
tasks. Note that custom continuation options are applied when calling
ContinueWhenAll and
ContinueWhenAny:
var factory = new TaskFactory( TaskCreationOptions.LongRunning | TaskCreationOptions.AttachedToParent, TaskContinuationOptions.None); // Calling StartNew on factory will create tasks according to factory configuration. Task task1 = factory.StartNew(Method1); Task task2 = factory.StartNew(Method2);
Recall that the .NET Framework provides the following two standard patterns for performing asynchronous operations:
Asynchronous Programming Model (APM), in which asynchronous operations are represented by a pair of Begin/End methods such as FileStream.BeginRead and FileStream.EndRead .
The following example illustrates the APM for a simple delegate:
private delegate int delFoo(string name); public void TestAsyncPorgammingPattern() { // Use the Asynchronous Programming Model (APM) to invoke Foo asynchronously delFoo del = Foo; AsyncCallback acb = new AsyncCallback(FooAsyncCallBack); DateTime state = DateTime.Now; del.BeginInvoke("test", acb, state); } // Function wrapped (called) by delegate private int Foo(string name) { return 10; } // Async call back called when the function execution is complete private void FooAsyncCallBack(IAsyncResult iar) { // Get delegate and call EndInvoke on it to get return value delFoo del = ((AsyncResult)iar).AsyncDelegate as delFoo; int nRetValue = del.EndInvoke(iar); // Use the return value to perform some additional work WriteResultToLog(nRetValue); } private void WriteResultToLog(int nValue) { Trace.WriteLine("Writing result to log ...."); }
Now comes the somewhat confusing part. Recall that a .NET task represents an asynchronous operation, and is very similar to creating new thread or ThreadPool work item. In other words, a Task is ultimately an asynchronous call. The example above can in fact be implemented using tasks (shown below). So which approach should be used? In the .NET Framework 4, tasks are the preferred API for writing multi-threaded, asynchronous, and parallel code. This is because tasks are more efficient, more scalable, and offer more programmatic control than working with threads or asynchronous delegates.
Using tasks to implement asynchronous operations offers the following advantages:
Both the TaskFactory and TaskFactory<TResult> classes provide several overloads of the FromAsync methods that let you encapsulate an APM Begin/End method pair in one Task instance or Task<TResult> instance. The various overloads accommodate any Begin/End method pair that have from zero to three input parameters. For example, consider this overload:
public Task<TResult> FromAsync<TArg1>( Func<TArg1, AsyncCallback, Object, IAsyncResult> beginMethod, Func<IAsyncResult, TResult> endMethod, TArg1 arg1, Object state);
Here TResult refers to the result type of the actual function we want the task to run. The function we want to run is Foo which has a return type of int. As we are using a delegate asynchronously to run Foo, TResult is here also the return type of the delegate's EndInvoke()method. TArg1 refers to the type of the first argument of the actual function we want the task to run. The function we want to run is Foo which has a first argument of type string. As we are using a delegate asynchronously to run Foo, TArg1 is there also the first parameter type of the delegate's BeginInvoke() method. The following code illustrates:
private delegate int delFoo(string name); // Function wrapped (called) by delegate private int Foo(string name) { return 10; } public void TestTaskWithAsyncPorgammingPattern() { // Set up the asynchronous method delFoo del = Foo; DateTime state = DateTime.Now; // Create a task to wrap Begin/End methods. The following signature was used: // public Task<TResult> FromAsync<TArg1>( // Func<TArg1, AsyncCallback, Object, IAsyncResult> beginMethod, // Func<IAsyncResult, TResult> endMethod, // TArg1 // arg1, // Object state) Task<int> task = Task<int>.Factory.FromAsync<string>( del.BeginInvoke, // Func<TArg1, AsyncCallback, Object, IAsyncResult > beginMethod, del.EndInvoke, "test", state, TaskCreationOptions.None); // Get task result. Note that there was no use of AsyncCallBack task.Wait(); int nResult = task.Result; DateTime dt = Convert.ToDateTime(task.AsyncState); }
Note that we do not specify an AsyncCallBack method. We just get back the result from function Foo which was invoked asynchronously via a Task object. But what about functionality in the AsyncCallBack method FooAsyncCallBack? In this case, you need to add a continuation to the original task. The continuation performs the work that would typically be performed by the AsyncCallBack delegate. It is invoked when the antecedent completes:
public void TestTaskContinuationWithAsyncPorgammingPattern() { // Set up the asynchronous method delFoo del = Foo; DateTime state = DateTime.Now; // Create a task to wrap Begin/End methods. The following signature was used: // public Task<TResult> FromAsync<TArg1>( // Func<TArg1, AsyncCallback, Object, IAsyncResult> beginMethod, // Func<IAsyncResult, TResult> endMethod, // TArg1 // arg1, // Object state) Task<int> task = Task<int>.Factory.FromAsync<string>( del.BeginInvoke, // Func<TArg1, AsyncCallback, Object, IAsyncResult > beginMethod, del.EndInvoke, "test", null, // No need to pass 'state' becuase it is already visible TaskCreationOptions.None); // Add a continuatio Task continuation = task.ContinueWith((Task<int> antecedent) => { int nResult = antecedent.Result; Trace.WriteLine("Result: " + nResult); // Access state. Note that it was passed null because it is still accessible // to the delegate of the continuation DateTime dt = Convert.ToDateTime(state); // Use the return value to perform some additional work WriteResultToLog(nResult); }); // Task executed sometime. You can uncomment the line below to wait // until the task is executed //continuation.Wait(); }
The following example shows how to initiate multiple asynchronous I/O operations, and then wait for all of them to complete before you execute the continuation:
public void TestMultipleTaskContinuationWithAPM() { // Create a list of 4 files to read List<string> lstFileNames = new List<string> { "A.txt", "B.txt", "C.txt" }; // Create an array of tasks for these files Task<string>[] tasks = new Task<string>[lstFileNames.Count]; // Iterate over all file names, creating a FileStream for each file // and associated task object FileStream fs; byte[] fileData; int i = 0; foreach (string strFile in lstFileNames) { // Create FileStream object fileData = new byte[0x2000]; fs = new FileStream(strFile, FileMode.Open, FileAccess.Read, FileShare.Read, fileData.Length, // Buffer size to hold data true); // When calling the task method, recall that TResult refers to the return value of the // function to be invoked, i.e., return value for Read (not BeginRead) which is 'int'. // TArg1, TArge2, etc. refer to the type arguments of the asynchronous version of the // function we want to invoke, i.e., BeginRead and EndRead Task<int> task = Task<int>.Factory.FromAsync( fs.BeginRead, // BeginMethod fs.EndRead, // EndMethod fileData, // arg1 0, // arg2 fileData.Length, // arg3 null); // state // Tasks returned from FromAsync have a status of 'WaitingForActivation' and will be // started by the system at some point after the task is created. If you attempt to // call Start on such a task, an exception will be raised Trace.WriteLine("Current task status: " + task.Status); tasks[i] = task.ContinueWith((Task<int> antecedent) => { // Close file fs.Close(); // Check how many bytes were read. If less than the initial buffer size, then // resize to actual length if (antecedent.Result < fileData.Length) Array.Resize(ref fileData, antecedent.Result); // Return contents of file return new UTF8Encoding().GetString(fileData); }); i++; } // Collect results from all tasks Task continuation = Task.Factory.ContinueWhenAll(tasks, (data) => { foreach (var v in data) Trace.WriteLine(v.Result); }); continuation.Wait(); } Output: Line 1 from A.text Line 2 from A.text Line 3 from A.text Line 1 from B.text Line 2 from B.text Line 3 from B.text Line 1 from C.text Line 2 from C.text Line 3 from C.text
The Task class achieves two distinct things:
Key point is that you can leverage a task’s features for managing work items without scheduling anything to run on the thread pool. The class that enables this pattern of use is called TaskCompletionSource and is used as follows: Instantiate TaskCompletionSource and use its Task property to get a task upon which you can wait and attach continuations—just like any other task. The task is entirely controlled by the TaskCompletionSource methods SetResult, SetException, SetCanceled, etc:
Also recall the Event-Base Asynchronous Pattern (EAP): For some synchronous
method
Foo, the EAP provides an asynchronous
counterpart
FooAsync. Calling this method launches the
asynchronous work, and when the work completes, a corresponding
FooCompleted event is raised.
The TPL does not provide any methods that are specifically designed to
encapsulate an event-based asynchronous operation in the same way that
the
FromAsync family of methods wrap the
IAsyncResult pattern. However, the TPL does
provide the
TaskCompletionSource
public void TestTaskCompletionSource() { // The type argument int specifies we want to get a Task<int> var tcs = new TaskCompletionSource<int>(); // Create a thread to run a lengthy operation and then set the result on // TaskCompletionSource new Thread(() => { // Simulate long-running operation, perhaps a call to a WCF/Web service Thread.Sleep(500); // Assume we now have result from WCF/Web service tcs.SetResult(100); }).Start(); // Get the underlying task Task<int> task = tcs.Task; // Run a child task task.ContinueWith((ant) => { Trace.WriteLine("Task via TaskCompletionSource returned " + ant.Result); }); // Wait for results task.Wait(); }
PLINQ, the Parallel class, and Tasks automatically marshal exceptions to the consumer. Because these libraries leverage many threads, it’s possible for two or more exceptions to be thrown simultaneously. To ensure that all exceptions are reported, exceptions are wrapped in an AggregateException container, which exposes an InnerExceptions property containing each of the caught exception(s):
public void TestAggregateExceptions() { try { var v = from i in ParallelEnumerable.Range(1, 100) select 1 / (i - i); foreach (int n in v) Trace.WriteLine(n); } catch (AggregateException ex) { Trace.WriteLine(" Caught " + ex.InnerExceptions.Count + " Exceptions"); foreach (Exception e in ex.InnerExceptions) Trace.WriteLine( e.Message ); } }
AggregateException provides Flatten and Handle methods to simplify exception handling:
catch (AggregateException aex) { foreach (Exception ex in aex.Flatten().InnerExceptions) myLogWriter.LogException(ex); }
.NET Framework 4.0 provides a set of thread-safe collections in System.Collections.Concurrent:
| Concurrent Collection | Non-concurrent Equivalent |
| ConcurrentStack<T> | Stack<T> |
| ConcurrentQueue<T> | Queue<T> |
| ConcurrentDictionary<TKey, TValue> | Dictionary<TKey, TValue> |
| ConcurrentBag<T> | None |
| BlockingCollection<T> | None |
Note the following key points about concurrent collections:
IProduceConsumerCollection<T>
A producer/consumer collection is a collection where the two main uses are adding an element (producing) and retrieving an element (consuming). IProducerConsumerCollection means that the implementing class behaves as a thread-safe producer/consumer collection. Producer/consumer collections are important in parallel programming because they’re conducive to efficient lock-free implementations. The following classes implement IProducerConsumerCollection:
IProducerConsumerCollection is defined as follows:
public interface IProducerConsumerCollection<T> : IEnumerable<T>, ICollection, IEnumerable { // Copies the elements of the IProducerConsumerCollection<T> to an System.Array, starting at a specified index. void CopyTo(T[] array, int index); // Copies the elements contained in the IProducerConsumerCollection<T> to a new array. T[] ToArray(); // Attempts to add an object to the IProducerConsumerCollection<T>. bool TryAdd(T item); // Attempts to remove and return an object from the IProducerConsumerCollection<T>. bool TryTake(out T item); }
Note that TryAdd and TryTake eliminate the need to lock as you would around a conventional collection:
int result; lock (myStack) if (myStack.Count > 0) result = myStack.Pop();
TryAdd always succeeds and returns true in the three implementations provided. If you wrote your own concurrent collection that prohibited duplicates, however, you’d make TryAdd return false if the element already existed (an example would be if you wrote a concurrent set). The particular element that TryTake removes is defined by the subclass:
The three concrete classes mostly implement the TryTake and TryAdd methods explicitly, exposing the same functionality through more specifically named public methods such as TryDequeue and TryPop.
ConcurrentBag<T>
ConcurrentBag<T> stores an unordered collection of objects with duplicates permitted (unlike sets), and you don't care which element you get when you attempt to retrieve an element from the bag. Note the following points about ConcurrentBag<T>:
BlockingCollection<T>
If you call TryTake on any of ConcurrentStack<T>, ConcurrentQueue<T> or ConcurrentBag<T> and the collection was empty, the method returns false. Sometimes it's more useful if the collection would block (wait) until an element is available. A blocking collection wraps any collection that implements IProducerConsumerCollection<T> allowing removal attempts from the collection to block until data is available to be removed. A blocking collection also lets you limit the total size of the collection, blocking the producer if that size is exceeded. A collection limited in this manner is called a bounded blocking collection.
To use BlockingCollection<T>:
public void TestBlockingColleciton() { // Recall that BlockingCollection<T> is a wrapper for an IProducerConsumerCollection<T> // instance, allowing collection removals to block until data is available to be removed. // Similary, BlockingCollection<T> can be given an upper bound on the number of elements // allowed; adding extra elements will block if the upper bound was reached int nCapacity = 3; BlockingCollection<int> bc = new BlockingCollection<int>(nCapacity); // Create a task to populate the collection (a producer) Task.Factory.StartNew(() => { // Since bounded capacity was specified a call to Add may block until space // is available to store the additional item for (int i = 0; i < (nCapacity * 2); i++) { Trace.WriteLine("Waiting to add value: " + i); bc.Add(i); Trace.WriteLine("Added value: " + i); } // Mark the blocking collection as not accepting any more additions. // Attempts to remove from the collection will not wait when it is empty bc.CompleteAdding(); }); // Create a task to read from the collection (a consumer) Task.Factory.StartNew(() => { try { // A call to Take may block until an item is available to be removed. // Take throws InvalidOperationExceptio if BlockingCollection<T> is empty // and the collection has been marked as complete for adding. while (true) { Trace.WriteLine("Count = " + bc.Count + ". Attempting to take item..."); Trace.WriteLine("Took item " + bc.Take()); } } catch (Exception ex) { Trace.WriteLine("Failed to take item. Error: " + ex.Message); } }); } Output Shown below: Count = 0. Attempting to take item... Waiting to add value: 0 Added value: 0 Waiting to add value: 1 Took item 0 Count = 1. Attempting to take item... Added value: 1 Waiting to add value: 2 Added value: 2 Waiting to add value: 3 Took item 1 Added value: 3 Count = 2. Attempting to take item... Took item 2 Count = 1. Attempting to take item... Took item 3 Count = 0. Attempting to take item... (throws exception below) A first chance exception of type 'System.OperationCanceledException' occurred in mscorlib.dll A first chance exception of type 'System.InvalidOperationException' occurred in System.dll Failed to take item. Error: The collection argument is empty and has been marked as complete with regards to additions.
The following shows an example of a blocking collection:
// Represents a cancellable task that represents an external async delegate class WorkItem { // Work to be done public Action Action { get; protected set; } // Propagates notification that work on item should be canceled public CancellationToken? CancelToken { get; protected set; } // Enables the creation of a task that can be handed out to consumers who can then // explicitly set the state of the task using TaskCompletionSource methods. In other // words, we’ve got the richness of the task model while, in effect, implementing our // own scheduler. public TaskCompletionSource<object> TaskSource {get; protected set;} public WorkItem(Action act, CancellationToken? ct, TaskCompletionSource<object> tcs) { Action = act; CancelToken = ct; TaskSource = tcs; } } // Implements a producer/consumer queue using a blocking collection with the following features // 1. Indicates when a work item has completed // 2. Cancels an unstarted work item // 3. Deals with exceptions thrown by a work item class ProducerConsumerQueue : IDisposable { private BlockingCollection<WorkItem> _taskQ = new BlockingCollection<WorkItem>(); public ProducerConsumerQueue(int workCount) { // Start a number of tasks to consume work for (int i = 0; i < workCount; i++) { Trace.WriteLine("Adding task " + i); Task.Factory.StartNew(Consume); } } // Add a WorkItem to the blocking collection public Task Enqueue(Action action, CancellationToken? ct = null) { // Add WorkItem to blocking queue var tcs = new TaskCompletionSource<object>(); _taskQ.Add(new WorkItem(action, ct, tcs)); // Return task wraped by TAskCompletionSource return tcs.Task; } private void Consume() { Trace.WriteLine("Starting Consume on thread ID " + Thread.CurrentThread.ManagedThreadId); // GetConsumingEnumerable yields elements as they become available. Use // _taskQ.GetConsumingEnumerable() instead of just _taskQ because _taskQ will // simply take a snapshot of the current state, while _taskQ.GetConsumingEnumerable() // blocks waiting for completion (i.e. a call to CompleteAdding) foreach (WorkItem wi in _taskQ.GetConsumingEnumerable()) { Trace.WriteLine("Processing item on thread ID " + Thread.CurrentThread.ManagedThreadId); // If work item was cancelled, set its task as cancelled if (wi.CancelToken.HasValue && wi.CancelToken.Value.IsCancellationRequested) wi.TaskSource.SetCanceled(); else { try { // Invoke action for task wi.Action(); wi.TaskSource.SetResult(null); } catch (Exception ex) { wi.TaskSource.SetException(ex); } } } } public void Dispose() { throw new NotImplementedException(); } }
public void TestConsumerProducer() { ProducerConsumerQueue pc = new ProducerConsumerQueue(2); pc.Enqueue(EnqueueAction); pc.Enqueue(EnqueueAction); pc.Enqueue(EnqueueAction); pc.Enqueue(EnqueueAction); pc.Enqueue(EnqueueAction); } private void EnqueueAction() { Trace.WriteLine("ManagedThreadId: " + Thread.CurrentThread.ManagedThreadId); } Output: Adding task 0 Adding task 1 Starting Consume on thread ID 6 Processing item on thread ID 6 Starting Consume on thread ID 11 ManagedThreadId: 6 Processing item on thread ID 11 ManagedThreadId: 11 Processing item on thread ID 6 ManagedThreadId: 6 Processing item on thread ID 6 ManagedThreadId: 6 Processing item on thread ID 11 ManagedThreadId: 11 The program '[2684] Threads.vshost.exe: Managed (v4.0.30319)' has exited with code 0 (0x0).
SpinLock and SpinWait are designed to help in situations where a brief episode of spinning is preferable to locking as it avoids the cost of context switching. Their main use is in writing custom synchronization constructs. Note that SpinLock and SpinWait are value types (struct) and not reference types (class). This is an optimization technique to avoid the cost of indirection and garbage collection. You must be careful not to unintentionally copy instances — by passing them to another method without the ref modifier, or declaring them as readonly fields.
The SpinLock struct lets you lock without incurring the cost of a context switch, at the expense of keeping a thread spinning (uselessly busy) if the lock could not be taken. This approach is valid in high-contention scenarios when locking will be very brief (e.g., in writing a thread-safe linked list from scratch). If you leave a SpinLock contended for too long (milliseconds at most), it will yield its time slice, causing a context switch just like an ordinary lock. When rescheduled, it will yield again — in a continual cycle of “spin yielding.” This consumes far fewer CPU resources than outright spinning — but more than blocking. On a single-core machine, a spinlock will start “spin yielding” immediately if contended.
Note the following points regarding a SpinLock:
public void SpinLockUsagePattern() { bool bLockTaken = false; // SpinLock provides a mutual exclusion lock primitive where a thread trying // to acquire the lock waits in a loop repeatedly checking until the lock becomes available SpinLock sp = new SpinLock(false); // false: Disable thread tracking try { // Acquire lock // bLockTaken: True if the lock is acquired; otherwise, false. bLockTaken must be // initialized to false prior to calling SpinLock.Enter sp.Enter(ref bLockTaken); // Thread-safe code comes here ... } finally { if (bLockTaken) sp.Exit(); } }
SpinLock still limits concurrency and it wastes CPU time doing nothing useful. Often, a better choice is to spend some of that time doing something speculative — with the help of SpinWait.
SpinWait helps you write lock-free code that spins rather than blocks. Lock-free programming with SpinWait is as hardcore as multithreading gets and is intended for when none of the higher-level constructs will do. A prerequisite is to understand Non-blocking Synchronization.
TODO:
Custom Partitioners for TPL and PLINQ
Parallel Diagnostic Tools