
A pure object-oriented architecture is database-independent. In extreme cases, the application only touches the database at startup to read all state and at termination to write state back to the database. While this approach might work in certain scenarios, it is not suitable for multi-user business applications; if the state is kept at the workstation, you won't see other users' changes until the next startup. If state is kept at the server and is shared by all users, you will have to solve complex synchronization problems.
In this architecture, database capabilities are rarely exercised. The developer must manually handle transactions, concurrency, querying and traversing data. Obviously this is not a good architecture for .NET platform.
With database-centric architectures, most or all of the logic is moved from the client to the database server. The main disadvantage of this approach is that in many instances, logic must be present at the client side.
This architecture is not very flexible to suit several different classes of applications.
Windows DNA is described endlessly in many articles in MSDN. For a good round-up of Windows DNA see Frequently Asked Questions about Windows DNA article in MSDN. Windows DNA is targeted at using Microsoft technologies such as ASP, SQL Server and COM+ among many others. Windows DNA is based upon 3 tiers; presentation, business logic and data tiers (or layers ).
The lessons learned in the Windows DNA about designing N-tier applications should be rethought because .NET brings many changes that affect the way we build distributed applications. More important, the fundamental support for XML Web Services built in .NET allows creating new kinds of applications that go beyond the classic N-tier approach. This section explains some of the lessons gained by the widespread experience of building N-tier applications with Windows DNA technologies.
Windows DNA commonly implement their business logic using one or more of three implementation options:
Windows DNA supports both native Windows clients, written in languages such as VB and C++, and browser clients which are more limited. Application often have both Windows native clients and browser clients. The Windows clients provide a full-featured interface, whereas browser clients provide a more limited interface.
ASP applications can use different mechanisms to maintain state information on the server between client requests. A firm rule in Windows DNA is that the ASP Session object should never be used to hold per-client state if the application may be load-balanced across two or more servers. The Session object is locked to a single machine and so it won't work correctly with load-balanced applications.
Note that both the ASP Session and the ASP Applications objects have other limitations too. One important one is that using either to store an ADO recordset greatly reduces performance because it limits the application's ability to exploit threading.
In Windows DNA, choosing how components on different machines will communicate is easy: DCOM is the only choice (unless you want to use sockets and write your own communication and security layer!). Note however DCOM has several important implications:
Data-access architectures that can be built in Windows DNA utilize ADO. The architectures can be divided into two categories - light touch and heavy touch:
Light-touch ADO clients
These clients hold database connections as briefly as possible and they
write to the database using stored procedures. These clients receive data in one
of three ways:
Heavy-touch ADO clients
These clients hold database connections for longer periods of time. These
kinds of applications rely on open connections and the stateful server-side
cursors. This allows:
Light-touch applications are the most scalable as they use database connections effectively. Heavy-touch clients on the other side must maintain database connections since server-side cursors require them. This severely limits the application's scalability and can be a very bad choice for Internet-based applications. Heavy-touch clients are simpler to develop but are rarely the best choice.
Note that ADO is not well-suited to work with hierarchical data such as XML documents. Similarly, ADO offers limited support for accessing the XML features of SQL Server 2000. As a result, Windows DNA applications commonly avoid ADO when working with hierarchical data.
A critical aspect of any N-tier application is how to effectively move data from the middle tier to the presentation (client) tier. In Windows DNA, when DCOM is used for distributed communications, disconnected ADO recordsets is the answer. This option can also be used for browser clients when the browser is guaranteed to be IE.
.NET supports conventional N-tier applications, Web-Service applications, and applications that combine elements of both. This section walks through the categories described earlier describing how .NET framework changes affect the decisions an architect makes when building an N-tier application.
Unlike the three choices in Windows DNA for creating business logic - ASP pages, COM+, and stored procedures - the .NET framework really provides only two options: assemblies and stored procedures.
For browser-based applications, the assemblies are created using Microsoft's ASP.NET aspx pages. Unlike ASP, writing business logic entirely using ASP.NET is often a good idea. One reason for this is the ASP.NET code-behind option. This option allows for the clean separation of presentation and logic code. So, while a Windows DNA might use ASP for presentation and COM components for logic, a .NET application may use just ASP.NET. Also business logic in ASP.NET can be written in any .NET language, not just the simple scripting languages supported by traditional ASP. And because ASP.NET compiles the pages rather than interpret them (as in ASP), ASP.NET applications can be very fast.
With the .NET framework, the need for a Windows client diminishes - a browser client may be all that is needed. One reason for this is that ASP.NET Web Controls allow building and/or reusing browser elements. Also the ability to download .NET framework-based components to IE clients, and then have those control run with partial trust rather than the all-or-nothing trust required for ActiveX controls helps build better user interfaces.
With the .NET framework, the ASP Session object is not longer limited to a single machine. Unlike ASP, the Session object can be shared by two or more machines. This obviously allows using the Session object to maintain state in a load-balanced Web server farm, making it much useful. Also because the contents of the Session object can optionally be stored in a SQL Server database, the mechanism can be used to persist client state in the event of failure.
Another removed limitation is that .NET DataSets can be stored in the Session or Application objects with no threading limitations. The firm Windows DNA rule that ADO Recordset should not be stored in the Session or Application objects does not apply to DataSets in .NET. This makes storing the results of a query simpler and more natural
The .NET framework provides more options for communicating with distributed parts of an application than Windows DNA. The choices include the following:
More options mean more architectural choices, but they also mean more factors to consider when making a choice. The following are the architectural issues to be aware of when creating distributed applications with the .NET framework:
Unlike ADO which makes it easy to build heavy-touch clients that do not scale well, ADO.NET is biased towards building light-touch clients. ADO.NET clients use forward-only, read-only cursors to read data. Stateful server-side cursors are not supported, so the programming model encourages short connection lifetimes.
The heavy-touch approach fostered by ADO has some advantages, and those issues can be resolved in ADO.NET as follows:
In Windows DNA, when DCOM is used, disconnected recordsets are used to transfer data back to clients. One significant change in .NET is that ADO.NET DataSets can be automatically serialized into XML, making it simple to pass data between tiers. While this was possible in Windows DNA, the .NET framework makes using XML to exchange information much more straightforward to accomplish.
N-tier design came as a result of the client/server model failings. There are many goals that a good N-tier design must accomplish:
However, N-tier applications also have many disadvantages:
An N-tier application is a distributed application where components are separated both logically and physically. An N-tier application can be configured in many different ways. The following is an example of an N-tier application.
The two main building blocks in this architecture model are Serviced Components and Stored Procedures.
Serviced Components: These are used to assist with enterprise infrastructure services. Examples of enterprise services to be used in suitable situations are Object Pooling, Just-In-Time-Activation (JITA), Transactions, Synchronizations, Resource Pooling, and Administrative support. Serviced components will affect the architecture by stating that non-default constructors and shared methods cannot be used as entry points in the .NET components used to implement the serviced components.
Stored Procedures: Using stored procedures is extremely recommended for the following reasons:
The following architecture is based on Windows DNA. It is focused on solving all actions with one single round-trip between tiers. The following figure is an overview of the main tiers, layers within each tier, and inter-relationships:
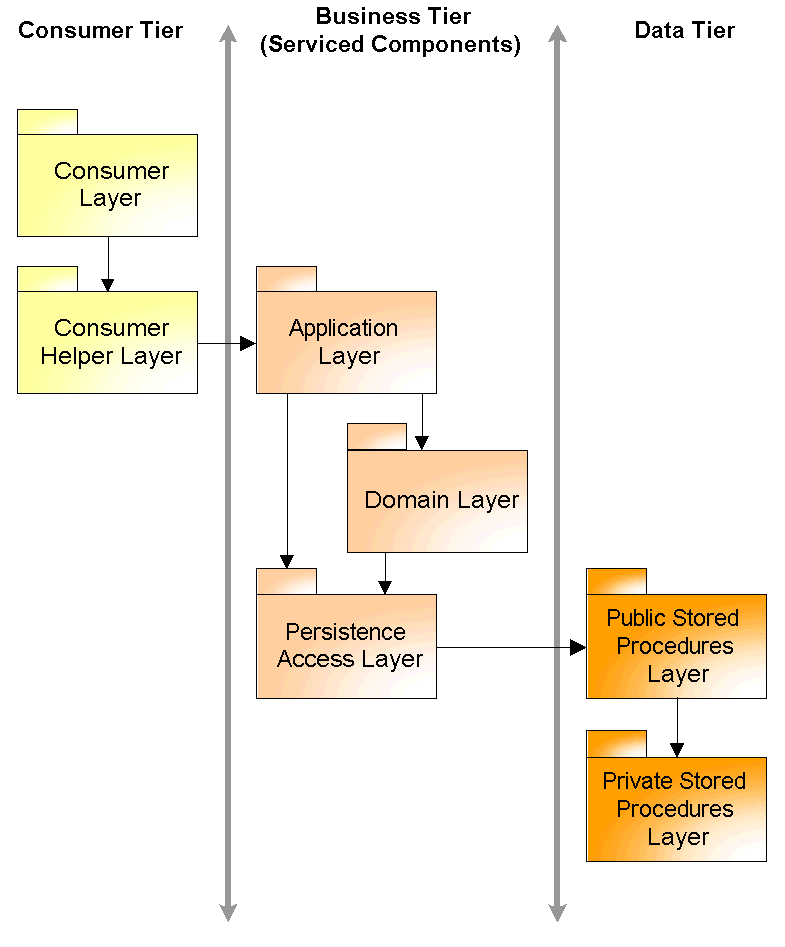
This architecture model is intended to be used as a starting point, and often several layers will be merged or even skipped all together. The key point here is that this architecture must be adapted to your specific applications and requirements. When implementing this architecture model, the default solution is implement each layer as a separate assembly. Again, certain layers can be merged into one assembly. The following sections describe each tier in detail.
The consumer tier will be different for different types of consumers. For Windows Forms, this tier is typically a single EXE containing both the Consumer and Consumer helper layers.
Consumer Layer: The purpose of this layer is to provide presentation services to the user. It's better to keep this layer as thin as possible and to delegate responsibilities to the Consumer Helper layer.
Consumer Helper Layer: As the name implies, the purpose of this layer is to help the Consumer Layer by providing services and hiding complexities. This layer is not a host for business rules. Even though it might seem tempting, do not add any business rules to this layer. The following lists some of the typical tasks implemented by this layer:
The Business Tier is built with serviced (COM+) components and is executed at an application server. This tier is made up of three layers:
The following sections discuss each layer in detail.
Application Layer: This layer is also called the Process Layer,
the Facade Layer, and so on. This layer is called the Application Layer
because it is really the API that that consumer uses to implement its
functionalities The purpose of this layer is to provide a class for each use
case. When the system is modeled, this layer is the first to be modeled,
typically along with tables in the database.
It is important to note that this layer should be consumer-independent, i.e., it
can be used by different consumer types without any code changes. This layer is
a core layer and should not be skipped. It is the entry point fro the Consumer
tier.
The Application Layer is also the ideal place for security. End users should be
authenticated by this layer which will use use COM+ security at the component
layer. If later layers need information about the user, that must be provided
from the Application Layer as parameters to the following layers. Even if COM+
security was not used because .NET Remoting was used for example, the
Application Layer is still the place for checking authorization.
Domain Layer: This layer is also called the Entity Layer or the
Business Layer. It is called the Domain Layer because is deals with the concepts
in the domain problem. The purpose of this layer is to validate rules and to
provide core algorithms.
Note that the classes in the Application Layer are use case-specific; there is
one class for each use case. The classes in the Domain Layer are used by several
use cases.
Persistent Access Layer: Another common name for this layer is the Data Access Layer. The purpose of this class is to hide all details about how different stored procedures are called, and how SQL statements are executed. Between this layer and the next layer, Public Stored Procedures Layer, there is often machine to machine communication.
The Data tier is located at the database server and it consists of the Public Stored Procedures Layer and the Private Stored Procedures Layer.
Public Stored Procedures Layer: This layer contains a small and controlled set of entry points to the database. Only the public stored stored procedures will be called by the Persistent Access Layer. The public stored procedures in this layer will do the work on their own, but they will usually delegate to private stored procedures
Private Stored Procedures Layer: The purpose of this layer is to do the real work and access tables, views, and User-Defined Functions (UDF). This layer can be skipped in smaller systems.
Because stored procedures are used as the only entry point to the database, views and UDFs are less of a must than in other systems. However, Views and UDFs can be very helpful in the long run when the schema changes. A View or a UDF can hide this change from the rest of the system.
Recall from Distributed Communications, there are several different methods how a client might talk to serviced components over the network:
XML Web Services is designed for situations when the client application is not in our control. The following figure shows the appearance of the Business Tier when it is deployed in an XML Web Service. Note that the Business Tier is deployed as a COM+ application. IIS is on the same machine to provide a listener with the calls to the XML Web Service.
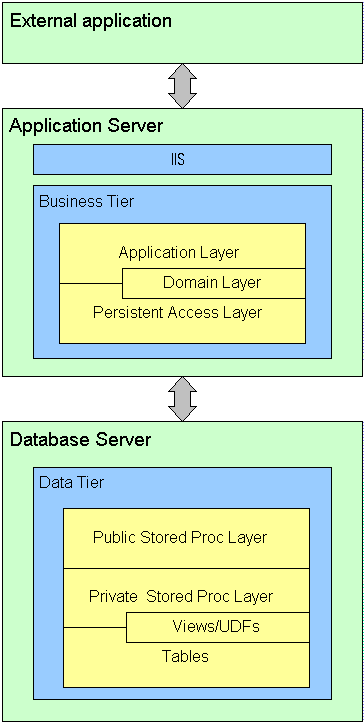
In the following scenarios, a Windows Forms applications is talking to the Business tier. In this scenario, there is more tight coupling than the previous one. DCOM or .NET Remoting can be used for network communication. With DCOM, you automatically get a proxy and a stub, but with .NET Remoting, you will have to write a custom listener. More importantly, note that XML Web Services could also be used for communication between the workstation and the application server. This is indicated by the IIS box

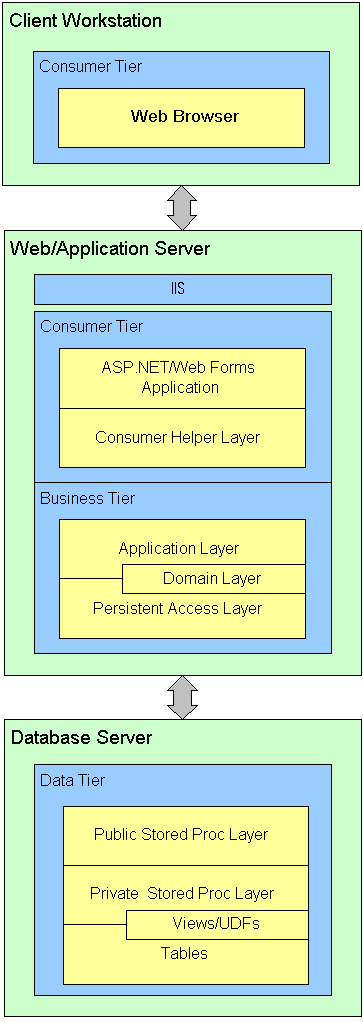
The last scenario is when a Web Browser communicates with an ASP.NET/Web Forms applications. In this case, the Business tier is most often on the same machine as the ASP.NET application.
While it is not a must, it is recommended that you call Dispose() when done with an object of a serviced component. Dispose() is an important concept that muse be understood well when building consumers for Serviced Components, which are scarce resources. This same recommendation applies to all scarce resources.
In the case of JIT activation with AutoComplete() method, we know when to call Dispose(). In all other cases where you do not want to wait for the garbage collector to kick in to release your object's resources, you must call Dispose(). Currently, object pooling (without JIT activation and AutoComplete() is the only feature where calling Dispose() is a must.
The Using() C# statement is a good solution to the problem of objects at the method level. But it is of no use if you want the object to love over several methods, because Using() has to be used at the method level.
It is usually not a catastrophe if Dispose() is not called; sooner or later, the garbage collector will kick in and cleanup the resources.
The Template Method pattern is used to help with implementing issues surrounding Dispose(). A helper class inherits from ServiceComponent .NET base class where most of the Dispose() problems will be handled for the ordinary serviced components. All serviced components will then derive from the helper class.

Note that no COM+ attributes should be used on the helper class, because derived classes may have conflicting COM+ attributes if any were specified on the helper base class.
To use the declarative transactions of COM+, you must use JIT. In most other cases, you probably shouldn't use JIT. The following are two example where using JIT is not appropriate:
One reason to avoid JIT activation is that it is interception-based and requires an instance of a serviced component to live in a non-default context. If you skip JIT activation you are one step close to using co-location in the caller's context or using COM+ 1.5 to use the default context instead. Both settings will save memory, instantiation time, and call overhead. Lookup more info on 'Must be activated in the default context' COM+ 1.5 setting.
Because of context issues, all components in the Domain and Persistent Access Layers are placed in DLLs of their own. Those DLLs are then configured in a separate COM+ library application. No services will be used for that application or its components. All services that require interception will be used for the components in the Application Layer.
The rule of thumb is to configure components to use the services they need. If interception is needed, use a non-default context for the root object and co-locate secondary objects in the root object's context. If interception is not needed, use the default context for all objects.
There are new concepts that SQL Server 2000 makes available. These are discussed below
UDFs were discussed previously in User-Defined Functions (UDF). Note that there are many restrictions imposed on UDFs. For example, you are not allowed to call a stored procedures from a UDF. In general, UDFs have an advantage over Views, namely the possibility of using parameters.
GUIDs can typically be used as primary keys. There are several reasons to use GUIDs (or UNIQUE IDENTIFIERS as SQL Server calls them) as primary keys:
In the graph for the architecture model, what if you want to have more than one machine for any given tier?
It is preferable to clone rather than physical partition serviced components. This is especially true if cloning or partitioning is done for performance and scalability reasons.
Prior to SQL Server 2000 it was not common to partition tables in On Line Transaction Processing (OLTP) systems. When partitioning was done, it was done for complete tables. SQL Server 2000 has a new solution called Distributed Partitioned Views (DPV).
DPVs make it easy to scale the database. The main philosophy is to create the same table in different databases at different database servers, but with different mutually exclusive constraints. A View is then created that uses a UNION to combine the rows from each table into a virtual table at each database server. To the consumer, it is transparent where the data is actually located since; the consumer can talk to any of the database servers to get any row.
It will be most efficient if the consumer always hits the correct database to fetch the required row. The Persistent Access Layer can use a routing trick where it sends the request to the right database based on the ID of the row to be fetched. For example, if database server A contains rows 1-1000 and row 666 is requested, then the Persistent Access Layer will forward the request to database server A.
This technology is new and there are disadvantages. You will also have to make design preparations for using DPVs; you are not allowed to have columns of data type ROWVERSION in tables that will be partitioned.
Reasons to standardize code structures: