This section discusses design and implementation guidelines for exception management systems that use .NET. The focus in on the process of handling exceptions within .NET technologies in a highly maintainable and supportable manner.
To build successful and flexible applications that can be maintained and supported easily, you must adopt an appropriate strategy for exception management. Spending time at the beginning to design a clear and consistent exception management strategy frees you from having to retrofit one during development, or worse still, having to retrofit it to an existing code base. You must design your system to ensure that it is capable of the following:
Exceptions represent a breach of an implicit assumption made within the code. An exception is not always an error. It is up to the application to determine whether an exception is an error or not. A 'File Not Found' exception may be a fatal error in some situations, but may not represent an error in other situations.
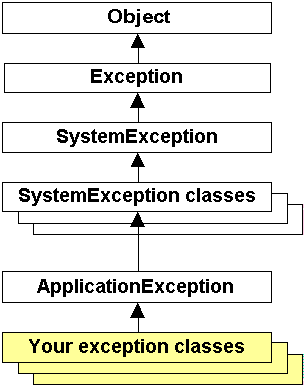
In .NET all exceptions should derive from the Exception class in the System namespace. In the following diagram ApplicationException serves as the base class for all application-specific exceptions. It derives from Exception but does not provide any functionality. Derive all custom application exceptions from this class:
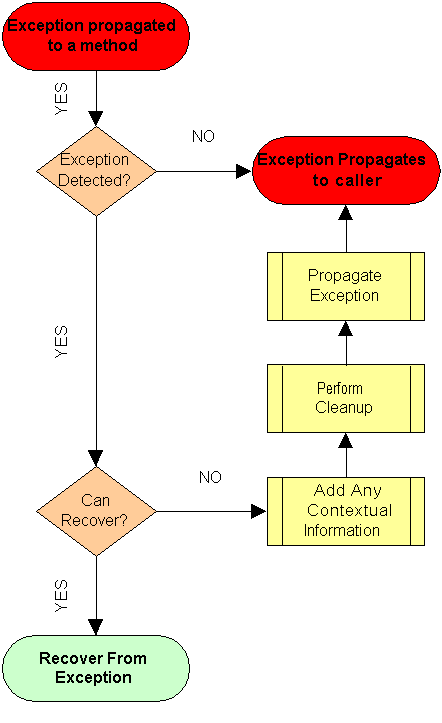
There are two main processes for handling exceptions. The first process deals with the steps that an application should perform to handle an exception, while the second process deals with the steps an application should perform when an exception is propagated to the last point or boundary at which the application can handle the exception before returning to the user.
Each method or procedure within an application should follow this process to ensure that exceptions are handled within the appropriate context defined by the scope of the current method. This process continues to occur as an exception propagates up the call stack:
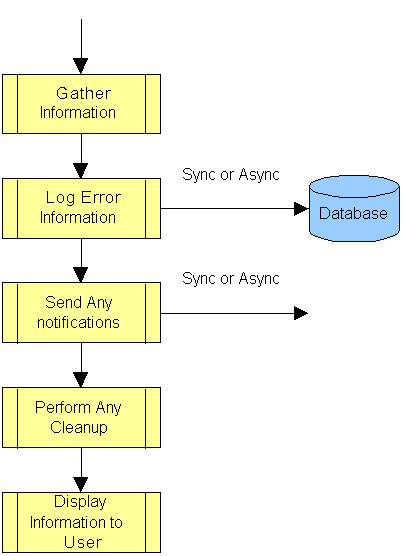
This process is vital to the application's ability to persist exception information, notify operational resources of exceptions, and properly manage the user experience.
Use try, catch, and finally to detect exceptions thrown within the code and to react to them appropriately:
try
{
// Some code that could throw an
exception
}
// Always ensure that multiple catch blocks are arranged
from the most specific to most general. This ensure
// that the most specific catch block is executed for any given exception
catch( SomeException e)
{
// Code to react to the exception
}
catch( SomeOtherException e)
{
// Code to react to the exception
}
finally
{
// This always gets executed,
irrespective of exception occurrence or not. This is usually the place for
// cleanup code.
}
When an exception occurs, you should catch it only when you specifically need to perform any of the following:
If a method does not need to perform any of these actions, it should not catch the exception. Rather it should allow it to propagate back to the caller. This keeps your code clean, simple, and explicit - you only catch exception that you need to handle within the scope of a particular method while allowing all others to propagate up the call stack.
Only throw an exception when a condition outside the code's assumption occurs. Do not use exceptions to provide the intended functionality. For example, when logging on, an invalid password should not throw an exception. But if the database against which users are authenticated was unavailable, then throwing an exception is reasonable. Also note that excessive use of exceptions can create unreadable and unmanageable code.
In certain scenarios, an exception you throw may be caught by the runtime, and an exception of another type might be thrown up the call stack in place of the original.
Scenario 1: Consider the situation when you call Sort on an ArrayList of some object. If one of the objects throws an exception in the Compare method of its IComparable interface, the exception is caught by the runtime, and a System.InvalidOperationException exception is thrown to the code that called Sort.
Scenario 2: Any exception throw by a method called through reflection will be caught by the runtime and System.Reflection.TargetInvocationException will be thrown to your code.
In these scenarios, your original exception is not lost. It is set as the InnerException of the exception thrown by the runtime. Always test your applications thoroughly to minimize the impact of these occurrences
There are three main ways to propagate exceptions
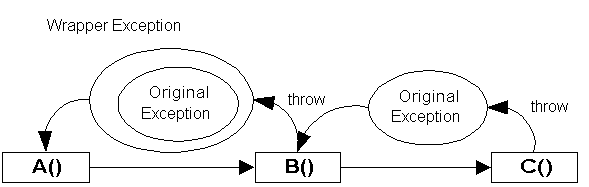
The following is a summary of the above:
| Way to catch exception | Allows you to react to the exception | Allows you to add relevancy |
|---|---|---|
| Let the exception propagate automatically | No | No |
| Catch and rethrow the exception | Yes | No |
| Catch, wrap, and throw the wrapped exception | Yes | Yes |
The following code shows how thee methods are used:
public foo()
{
try
{
// Some code that could throw an exception
}
catch( TypeAException
e) // Catch
and rethrow the exception
{
// Code to do any required processing
...
// Rethrow the exception
throw;
}
catch( TypeBException
e) // Catch,
wrap, and throw the wrapped exception
{
// Code to do
any required processing
...
// Wrap the current exception in a more relevant outer exception and rethrow the
new one
throw( new TypeCExcpetion(
strMessage, e);
}
finally
{
// Clean up code. Gets executed regardless of whether an exception was thrown or
not
}
//
All other exceptions are propagated automatically
}
The .NET framework is a type-based system that relies on the exception type for identification, rather than using method return codes such as HRESULT. You should, therefore, establish a custom hierarchy of application-specific exceptions classes that inherit from ApplicationException class, as illustrated below:
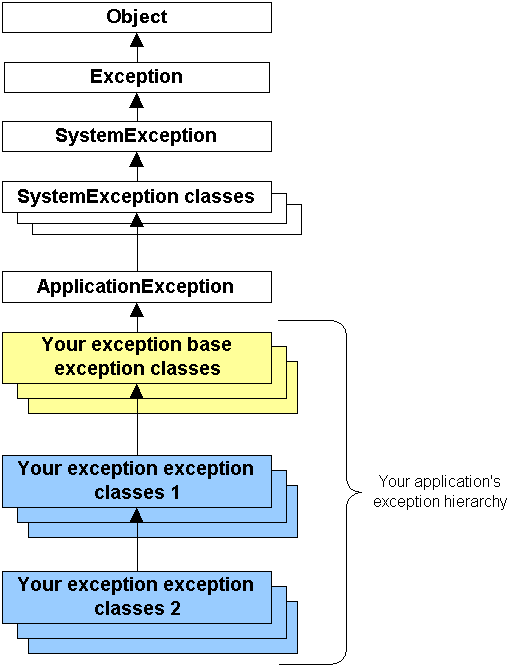
This hierarchy allows you to benefit from the following:
If a suitable exception class is already offered by the .NET framework, use it instead of creating a new exception class. You should only create a new custom exception class for an exception that you need to react and handle within the code that is not already available in the application's exception hierarchy. Most application exception hierarchies must be fairly flat wit grouping used for organization purposes or to allow some set of application exceptions to inherit common properties for functionality.
As you create the new hierarchy, use the following questions to help decide if you really need to create a new exception class:
Also not that the application's exception hierarchy should be stored in a single assembly that can be referenced throughout the application's code. This helps centralize the management and deployment of the exception classes.
To ensure standardized naming, always ensure the new exception class name ends with Exception. It is also good practice to supply the three constructors shown in the following class definition:
using System;
/* The base custom exception class must derive from
ApplicationException. Add fields to this class to capture specific application
information such as date, time, file name, line number, machine name, and so on.
This will encapsulate the common exception details of the custom base class and
makes this information available to other exception classes that will inherit
from this base class */
public class MyCustomBaseExceptionClass : ApplicationException
{
// Default constructor
public MyCustomBaseExceptionClass()
{}
// Constructor accepting a single
string message
public MyCustomBaseExceptionClass( string message
) : base(message)
{}
// Constructor accepting a single
string message and an inner exception which will be wrapped
// by this base custom exception class
public MyCustomBaseExceptionClass(string message,
Exception inner) : base(message, inner)
{}
...
}
The Exception class implements ISerializable interface, allowing it to manage its own serialization. To allow your exception to be marshaled through remoting boundaries, you need to attribute the exception class with the [Serializable] attribute and include the additional constructor shown below
public class MyCustomBaseExceptionClass : ApplicationException
{
...
protected MyCustomBaseExceptionClass(SerializationInfo info,
StreamingContext ctx) : base(info, ctx)
{}
...
}
If the exception class adds fields to the base ApplicationException class, you will need to persist these values programmatically into the serialized data stream. This can be done by overriding the GetObjectData method and adding these values into the SerializationInfo object:
/* A custom exception class that is
able to maintain its state (as it should) as it is marshaled across local and
remote boundaries. Always provide this functionality, even if the class will not
be remoted. Programming for the future means that class state will not be lost
if the class is required to be remoted in the future */
[Serializable]
public class MyCustomBaseExceptionClass : ApplicationException
{
// Required constructors. All four
mentioned above
...
// Data members
private string m_strMachineName = Environment.MachineName;
// Methods to get/set member variable
...
// Persist member variables into the
serialized data stream
public override void GetObjectData(
SerializationInfo info, StreamingContext ctx)
{
info.AddValue( "m_strMachineName",
m_strMachineName, typeof(String) );
base.GetObjectData( info, ctx );
}
}
This section discusses the tools available to handle unhandled exceptions at the system boundary.
ASP.NET code is now compiled and may be written in any .NET framework language. This means that ASP.NET allows you to utilize all the exception handling techniques that your component can. ASP.NET provides some specific functionality to allow you application to manage exceptions and configure how information should be displayed back to the user.
You should configure exception management settings within the application's Web.config file. The following is an example of the exception setting in Web.config:
<!-- In the customErrors section
specify a default redirect page. With mode="on", unhandled
exceptions will redirect the user to the specified defaultredirect page. With
mode="off", users will see the exception information and not be
redirected to the defaultredirect page. With mode="remoteonly", only
users accessing the site on the local machine will see exception information,
all others will be redirected to the defaultredirect page. This option is mainly
used for debugging -->
<customErrors defaultredirect="Some Error handling URL"
mode="on">
<error statuscode="500" redirect="/errorpages/servererror.aspx"/>
<error statuscode="404" redirect="/errorpages/filenotfound.htm"/>
</customErrors>
Be aware that these settings only apply to ASP.NET files, i.e., those with specific extensions such as .aspx and .asmx.
The Web.config settings apply only to its directory and any child directories. These settings can be overridden for specific pages using the ErrorPage attribute of the Page directive:
<!-- Override Web.config settings
for this page -->
<%@ Page ErrorPage="CustomError.aspc" %>
...
ASP.NET provides two main events for reacting to unhandled exceptions that propagates up from the application code:
Web services are discussed fully in the Web Services section. However, note that .NET provides the SoapException class as the only means to raise exceptions using SOAP.
Always ensure that you capture all appropriate information that accurately represents the exception condition. Note that potential recipients of this information include the following:
It is important that each of the above groups receive information relevant to them. Not all information is appropriate for all users. For example, users should not see cryptic messages with source code file name and line number, or other cryptic messages such as 'index of out range"! Always capture all relevant information and filter the display according to the recipient's needs. The following table summarizes the needs of each group of audience:
| Audience | Required Information |
|---|---|
| End Users |
|
| Application Developers |
|
| Operators |
|
To allow your application to provide rich information that can be tailored to the specific needs of each group, you should capture the details presented in the following table. Note that the Source column indicates the class and the class member that can generate this information:
| Data | Source |
|---|---|
| Date and time of exception | DateTime.Now |
| Machine Name | Environment.MachineName |
| Exception Source | Exception.Source |
| Exception type | Type.FullName obtained from Object.GetType |
| Exception message | Exception.Message |
| Exception stack trace | Exception.StackTrace |
| Call Stack | Environment.StackTrace - the complete call stack |
| Application domain name | AppDomain.FriendlyName |
| Assembly Name | AssemblyName.FullName in the System.Reflection namespace |
| Assembly version | Include in the AssemblyName.FullName |
| Thread ID | AppDomain.GetCurrentThreadId |
| Thread User | Thread.CurrentPrincipal in the System.Threading namespace |
Exceptions can have various structures and expose different public properties that offer valuable information about the cause of the exception. It is important to capture all of the information in order to provide a complete picture of what went wrong. You can easily walk the various public properties of an exception class and their values using reflection. This is very useful for generic logging techniques that accept an argument of type Exception.
In addition to detecting exceptions and gathering related data, you must ensure that such information is stored in a consistent and reliable way. If exception information is not properly logged, it may be impossible to understand what caused the exception.
There are a number of options for storing information, each with distinct advantages and disadvantages. Options include the following:
The event log provides a consistent and central repository for error, warning, and informational messages on a single machine. With .NET framework, it is easy to log and monitor.
To solve the problem associated with a local event log for each machine, a database can be used to store information .
This option should be used only when the event log cannot satisfy some logging need.
In conjunction with the options above, MSMQ can be used to provide a reliable transport mechanism to deliver data asynchronously to your chosen data store, which may be the event log, the database, or even the custom log file. The transactional nature of MSMQ ensures that data will not be lost, even in the event of a server or network failure. However, not the following:
Notification is a critical component of any exception management system. While logging is essential to help you understand what went wrong and what needs to be done to rectify the problem, notification informs you about the condition in the first place. The notification processes adopted by the application must be decoupled from the application's code. You should not have to change code every time you need to modify the notification mechanism. For example, you should be able to manage the list of recipients without changing any application code.
When working in an environment with a monitoring system, you can provide notifications in several ways:
The monitoring system can be configured to watch the log and monitor the arrival of messages. The monitor may be tuned to react to a set of messages. Tools such the Application Center Server can detect certain information logged to the event log and then take action based on pre-configured settings.
Advantages
Disadvantages
WMI is Microsoft's implementation of an industry standard for accessing management information for enterprise systems. The WMI event infrastructure provides the ability for applications to raise WMI events that can be monitored and handled. This approach decouples the notification rules and procedures from the application's code. The application needs to raise only certain events that a monitoring system can catch and then implement the correct notification procedures. .NET provides classes within the System.Management and System.Management.Instrumentation namespaces to simplify WMI programming.
Advantages
Disadvantages
If the application does not have the advantage of working with a monitoring system, there are several ways to create notifications:
In this scenarios, an email is sent out to a list of support personnel. While a common approach, it is not the most stable or robust choice:
Advantages
Disadvantages
In this scenario, you develop a notification program that can accept messages from the application and then react appropriately to those messages based on some configurable action. MSMQ can be uses to provide a reliable asynchronous delivery mechanism to pass data to the notification system. The custom notification program only needs to provide a subset of the functionality of a monitoring application.
Advantages
Disadvantages
This section focuses on strategies particular to the server-side layers and how they can be applied to the overall architecture. When considering exception handling as part of the architecture proposal, we must look at whether all layers must catch exceptions or not. Recall that the Consumer Helper Layer is responsible for translating the exception information from programming information to user-friendly information.
To illustrate, we discuss three types of exceptions that you cannot prevent completely:
Sooner or later, you will get error code 1205 from SQL Server informing you that you have been selected as the victim of a deadlock. The error handling in the stored procedures will be of no help at all and the stored procedure in which the deadlock was detected will be interrupted and so will the calling batch. Therefore, you're right back in Persistent Access Layer again.
In this case an exception of type System.Data.SqlClient.SqlException will be raised. If you do use COM+ transactions, the transaction is doomed and you have to leave the transaction stream. You do this by going all the way back to the Consumer Helper Layer which can restart the scenario and call the Application layer class again, and a new COM+ transaction is started. The Consumer Helper Layer will repeat this behavior a couple of time after a random-length pause before it gives up and tell the user that something is wrong because the transaction has been interrupted n times.
When a transaction times out, an exception of type System.Data.SqlClient.SqlException will be raised in the .NET component. Note that the default value for a timeout is 60 seconds, but only for debugging. You should probably decrease it to about 5 seconds in production systems.
When a transaction times out, there is nothing much to do except to trust the Consumer Helper Layer class to take care of the problem again by retrying the call to the Application layer class a couple of times before giving up.
Sometimes COM+ may terminate the COM+ application leading to 'RPC Server is unavailable' message. Again, the Consumer Helper Layer class helps out by just creating a new instance. Again, the the Consumer Helper Layer class will try a couple of times before giving up.
/* Error handling in SQL is done by
checking @@ERROR values after each potentially dangerous statement. If @@ERROR
is different from zero, then an error has occurred.
*/
CREATE PROCEDURE spMyProc ( ... parameters )
AS
-- Tracing for start of stored proc
EXEC spTraceStart @theSource
-- Standardized declarations
required for error handling
DECLARE @theSource
uddtSource,
@anError
INT,
@anErrorMessage
uddtErrorMessage,
@anReturnValue
INT,
@theTranCountAtEntry
INT
-- Standardized initializations
-- NOCOUNT is set on so as not to send back to the client
information about how many rows were
-- selected. In ADO, not using this clause can often lead to
problems
SET NOCOUNT ON
SET @anError = 0
SET @anErrorMessage = ''
SET @anSource = OBJECT_NAME(@@PROCID)
-- Decide whether a transaction
needs to be started
-- A transaction is started
if there is not already an active transaction
SET @theTranCountAtEntry = @@TRANCOUNT
IF (@theTranCountAtEntry = 0)
BEGIN
SET TRANSACTION ISOLATION LEVEL
SERIALIZABLE
BEGIN TRAN
END
-- Error handling
after EXEC of a stored proc
-- If @anError or @anReturnValue is
different from zero, then there was some problem. @anError is checked
-- to guard against situation where the stored proc might not
exist
EXEC @anReturnValue = spSomeStoredProc
SET @anError = @@ERROR
IF ( (@anError <> 0) OR (@anReturnValue <> 0))
BEGIN
SET @anErrorMessage = 'Failed to ...
'
IF @anError = 0
BEGIN
SET @anError
= @anReturnValue
END
GOTO ExitHandler
END
-- Error handling
after INSERT / UPDATE / DELETE statements
-- For INSERT/UPDATE/DELETE you do not
have a return value to check, instead @@ROWCOUNT tells you how
-- many rows were affected by the operation. @anError and @anRowCount
are obtained using SELECT instead
-- of SET because using SET to catch @anError value will
reset @@ROWCOUNT.
-- If the error is because @@ROWCOUNT is zero, we have to
decide on the error code on ourselves. A common
-- reason for @@ROWCOUNT = 0 is usually concurrency issues
INSERT INTO T1( F1, F2) VALUES( 1, 'yazan')
SELECT @anError = @@ERROR, @anRowCount = @@ROWCOUNT
IF @anError <> 0 OR @aRowCount = 0
BEGIN
SET @anErrorMessage = 'There was a
problem with ... '
IF @anRowCount = 0
BEGIN
SET @anError
= 80001 -- Unexpected error
END
GOTO ExitHandler
END
-- Error handling
after a SELECT statement
-- Note that most SELECT errors, such
as incorrect columns, will abort the entire call batch making it
-- impossible to capture @@ERROR. However, there are some
cases where @@ERROR is not zero, so error handling
-- is used for it all the time. Examples of @@ERROR not equal
to zero after SELECT are arithmetic overflow,
-- division by zero, and timeout when a lock could not be
granted.
-- Note that it is sometime an error for SELECT if @@ROWCOUNT
is zero (i.e., no row were returned). In this
-- case you can switch to the construction used for INSERT /
UPDATE / DELETE
SELECT * FROM T1
SET @anError = @@ERROR
IF @anError <> 0
BEGIN
SET @anErrorMessage = 'There was a
problem with ... '
GOTO ExitHandler
END
-- Error handling
after a violation of a business rule
-- A business rule is broken for
example, if a value is not within a certain range
IF @nPaymountAmount < @nExpectedPayment
BEGIN
SET @anError
= 710010
-- For example
SET @anErrorMessage = 'Payment is too
low' -- Very useful if @nPaymentAmount
was part of the error message
GOTO ExitHandler
END
-- Exit Handler
-- After each dangerous
statement, we check to see if there was an error. If so, we set
-- an error variable and then GOTO to the ExitHandler
ExitHandler:
-- If this stored proc started a
transaction, commit it if there was no error (@anError = 0), or abort it if
-- there was an error (@anError > 0). Note that it is
possible that some earlier code might have committed
-- the transaction and if all went well then @@TRANCOUNT is 0
and the code block won't execute. But if there
-- was an error, then the code below will ensure that the
transaction is aborted
IF (@theTranCountAtEntry = 0) AND (@@TRANCOUNT > 0)
BEGIN
IF @anError = 0
BEGIN
COMMIT TRAN
ELSE
BEGIN
ROLLBACK TRAN
END
END
-- Raise an
error on error conditions
-- If there was an error (hence
transaction aborted if started by this stored porc), then raise an error
-- spRaiseError calls RAISERROR. Note that RAISERROR
translates into a SqlException back to the .NET
-- component. In this case, RAISERROR solves the problem
concerning context information.
IF (@anError <> 0)
BEGIN
EXEC spRaiseError @theSource, @anError,
@anErrorMessage
END
-- Tracing for end of stored proc
EXEC spTraceEnd @theSource
-- Return Error code
return @anError
CREATE PROCEDURE spRaiseError ( @source udttSource, @error
INT, @strMsg udttErrorMessage, @severityLevel INT = 11 )
AS
DECLARE @Buf
VARCHAR(255)
DECLARE @strStandardErrorMessage udttErrorMessage
-- Initializations
SET NOCOUNT ON
SET @Buf = ''
-- Get the error message from our own table of error
messages. Using our own table rather than sysmessages tables
-- allows us to add extra information such as possible reasons for the error,
etc.
IF @error > 5000
SELECT @Buf = T.Description FROM ErrorDesc T WHERE T.ID =
@error
-- Now construct the final error message with other
information such as error number, source, etc
SET @strStandardErrorMessage = 'Error = ' + CAST(@error as
VARCHAR(10) +
' Description = ' + @strMsg
+
' Detail = ' + @Buf
+
' Source = ' + @source
-- Finally, raise the error
RAISERROR (@strStandardErrorMessage, @severityLevel, 1)