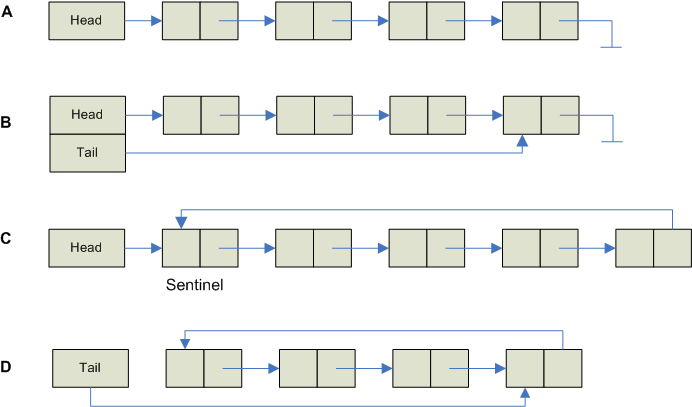
The singly-linked list is the most basic of all the linked data structures. A singly-linked list is simply a sequence of dynamically allocated objects, each of which refers to its successor in the list. Despite this simplicity, there are many possible implementations, some of which are shown in the figure below:
A. B, C and D are variations of a singly-linked list:
Linked list A is the most basic implementation where each element refers to its successor and the last element refers to null. One variable labelled Head points to the first item in the list and is used to keep track of the list. However, this implementation is inefficient when we want to add elements to both ends of the list. To add an element at the end (the tail), we need to traverse the entire list to locate the last element. Obviously, not very efficient.
Linked list B is an improvement over A because it makes adding elements to the tail of the list much more efficient. Here we use a second variable called Tail which always refers to the last element in the list.
Linked List C illustrates two common programming tricks:
The sentinel element is never used to hold data and is always present. It is used because it simplifies the programming of certain operations. For example, since there is always a sentinel standing guard, we never need to modify the Head variable.
Linked list C is a circular list. Instead of having the tail point to null to demarcate the last element in the list, the last element refers to the sentinel. The advantage of this trick is that insertion at the head, at the tail, or at an arbitrary location of the list are all identical operations (the first element follows the last element immediately).
Linked list D is again a circular list, but this time the variable Tail refers to the last element in the list. And since this is a circular list, the first element follows the last element immediately, therefore, it is relatively simple to insert both at the head and at the tail of this list.
The following figure shows the empty list representation for each of the above implementations. Note that the sentinel is always present.
![]()
Note that with a linked list there is no notion of an inherent limit on the number of items that can be placed in a linked list. Items can be added until memory is exhausted.
The implementation that follows uses variation B since it supports append and prepend operations efficiently. The following figure illustrates the our singly-linked list scheme. There are two main classes:
Element class which is used to represent each element in the list. Element class has three fields - list, value, and next.
LinkedList class which is the main data structure. A LinkedList instance contains 0 or more Elements. LinkedList class has two fields - Head and Tail.
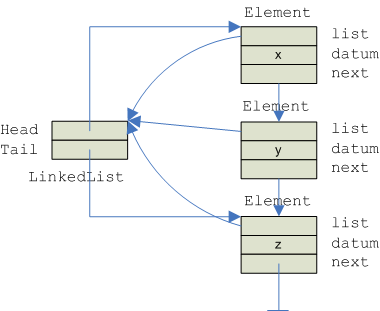
The following shows a complete implementation of a linked list using scheme B. When studying the code, it is crucial that you refer back to the diagrams above. Otherwise, understanding the code can be difficult:
// Represents a node for linked lists
public sealed class Element<T> where T : IEquatable<T>
{
#region Data members
// Note: declaring member variables private or protected is
incorrect because then
// they cannot be accessed by SingleLinkedList class.
Declaring them public is also
// incorrect because these members are not supposed to be
accessed by any class except
// SinglyLinkedList. Therefore, the best solution is to
declare them internal
internal SinglyLinkedList<T> list;
// Container
internal T
datum = default(T); // get default value of
generic type parameter T
internal Element<T>
next;
#endregion
#region Constructors
// Used to initialize member variables
public Element(SinglyLinkedList<T> container, T value,
Element<T> nextElement)
{
list = container;
datum = value;
next = nextElement;
}
#endregion
#region Properties to expose data members
internal SinglyLinkedList<T> List
{
get { return list; }
}
internal T Value
{
get { return datum; }
}
internal Element<T> NextElement
{
get { return next; }
set { next = value; }
}
#endregion
#region public interface
// Inserts an element after the current element (identified
by 'this')
public void InsertAfter(T oValue)
{
// To understand this: the next
element pointed to by the current element
// should become the element that we
wish to insert. Visualize the situation
// by drawing a linked list
representation
next = new Element<T>(list, oValue,
this.next);
// Check if we are inserting at the
end
if (list.Tail == this)
list.Tail =
next;
}
// Inserts an element before the current element (identified
by 'this')
public void InsertBefore(T oValue)
{
// Create a new element whose next
element is the current element. The following
// statement, does the above but it
does not properly place the new element in the
// list. For example, which element
in the list has this new element as its next
// element?
Element<T> eNew = new
Element<T>(list, oValue, this);
// Check for boundary conditions: If
current element (this) is the head, then the
// new element eNew should become the
head (in other words, if Head points to the
// current element, then Head should
be changed to point to the new element).
// Otherwise, it becomes necessary to
traverse the linked list starting from the
// head to locate the element that
must precede the new element
if (this == list.Head)
list.Head =
eNew;
// Head now points to the new element
else
{
// Loop from
the beginning until the element identified by 'this', i.e., the
// current
element is located.
Element<T>
ePrevious = list.Head;
while (ePrevious
!= null && ePrevious.next != this)
ePrevious = ePrevious.next;
// Element
was found. Now make its next element, the newly created element
ePrevious.next = eNew;
}
}
#endregion
}
// This class can be enumerated therefore, it inherits from IEnumerable<T>
public class SinglyLinkedList<T> :IEnumerable<T> where T : IEquatable<T>
{
#region Data members
// Data members are protected as this class could be
specialized by a derived class. Again
// refer to linked list implementation to explain the
functionality of 'head' and 'tail'
protected Element<T> head = null; // always points to the first element in the list (unless empty)
protected Element<T> tail = null; // always points to the last element in the list (unless empty)
#endregion
#region Constructors
// When the list is first created, it is empty. Therefore,
fields head and tail
// are initially null as per their declaration. The
constructor therefore, does nothing
public SinglyLinkedList()
{
/* Empty implementation */
}
#endregion
#region Properties
public Element<T> Head
{
get { return head; }
set { head = value; }
}
public Element<T> Tail
{
get { return tail; }
set { tail = value; }
}
public bool IsEmpty
{
get { return (head == null); }
}
// Retrieve value of the first element
public T FirstValue
{
get
{
if (IsEmpty)
throw new InvalidOperationException("List is empty");
return
head.Value;
}
}
// Retrieve value of the last element
public T LastValue
{
get
{
if (IsEmpty)
throw new InvalidOperationException("List is empty");
return
tail.Value;
}
}
#endregion
#region Public methods
// Empties the contents of the cell. No need to traverse list
and de-allocate each
// element as the GC will take care this. To clear the list,
just re-initialize the
// head and tail to null.
public void Clear()
{
head = null;
tail = null;
}
// Insert an element at the top of the list. The newly
inserted element becomes
// the head of the list
public void Prepend(T oValue)
{
// Create a new element. Because the
element is required to be at the top of the list,
// the next element it should point
to should be the current head
Element<T> e = new Element<T>(this,
oValue, head);
// Recall the meaning of head and
tail: head always points to the first
// element (unless empty). tail
always points to the last element (unless
// empty).
// Now, if the list is initially
empty, the new element is the only element
// (i.e., first and last element),
hence head and tail both point to the new
// element (look at the structure
diagram for B). If list is not empty, the
// new element is now the first
element and head should point to the new
// first element. tail need not
modified as it always points to the last element
// which is different from the first
element.
if (IsEmpty)
{
tail = e;
head = e;
}
else
{
head = e;
}
}
// Insert an element at the bottom of the list. The newly
inserted element becomes
// the tail of the list
public void Append(T oValue)
{
// Create a new
element. Because the
element is required to be at the bottom of the list,
// the next element it should point
to should be null
Element<T> e = new Element<T>(this,
oValue, null);
// Recall the meaning of head and
tail: head always points to the first element (unless empty).
// tail always points to the last
element (unless empty). Now,if the list is initially empty, the new
// element is the only element (i.e.,
first and last element), hence head and tail both point to the
// new element (look at the structure
diagram for B). If list is not empty, the new element is now the
// last element and tail should point
to the new last element. head need not modified as it always
// points to the first element which
is different from the last element.
if (IsEmpty)
{
tail = e;
head = e;
}
else
{
tail.NextElement = e;
tail= e;
}
}
// Copies the elements of of the given source list to the
current list
public void Copy(SinglyLinkedList<T> source)
{
// Check against self copy
if (source == this)
return;
// Not a self-copy. First, clear all
the elements in the current list
this.Clear();
// Then copy
elements one-by-one from
the source list to the current list
// Note the for-loop structure for a
linked list: the start condition is the
// head of the list, the end
condition is null, and the next iterations points
// to the next element
for (Element<T> eCurrent =
source.head; eCurrent != null; eCurrent = eCurrent.next )
{
this.Append(eCurrent.datum);
}
}
// Deletes a given element by doing a sequential search
and simply omitting the element from
// the list
public void Delete(T oValue)
{
// If list is empty, throw an
exception
if (IsEmpty)
throw new
InvalidOperationException("The list is empty");
// Search sequentially for the
element to be deleted. Note the syntax of the for loop
// used to iterate over the linked
list
Element<T> eElementToDelete = head;
Element<T> ePreviousElement = head;
for (Element<T> eCurrent = this.head;
eCurrent != null; eCurrent = eCurrent.next)
{
// Does the
current item have the same value?
if (eCurrent.datum.Equals(oValue))
{
eElementToDelete = eCurrent;
break;
}
else
ePreviousElement = eCurrent;
}
// We have looped through the list.
Now examine what we found
// If no item was found, through an
exception
if (eElementToDelete == null)
throw new
InvalidOperationException("Item was not found");
// The following logic can be easily
understood by looking at the linked list diagram
// (list B in Fundamentals - Data
Structures)
if (eElementToDelete == head)
// If item to
delete is the head, set the next element as the head
head =
eElementToDelete.next;
else if (eElementToDelete == tail)
// If item to
delete is the tail, set the previous item to be the tail
tail =
ePreviousElement;
else
ePreviousElement.next = eElementToDelete.next;
}
// Returns the count of elements in the list
public int Count
{
get
{
int nCount =
0;
for
(Element<T> e = head; e != null; e = e.next)
nCount++;
return nCount;
}
}
#endregion
#region IEnumerable<T> Members
public IEnumerator<T> GetEnumerator()
{
IEnumerator<T> e = (IEnumerator<T>)new
SLLEnumerator<T>(this);
return e;
}
#region IEnumerable Members
System.Collections.IEnumerator
System.Collections.IEnumerable.GetEnumerator()
{
IEnumerator e = (IEnumerator)new
SLLEnumerator<T>(this);
return e;
}
#endregion
}
// This is an enumerator class over a singly-linked list.
This is a standard implementation
// of an enumerator class
public class SLLEnumerator<T> : IEnumerator where T: IEquatable<T>
{
private int nIndex = -1;
private SinglyLinkedList<T> list = null;
public SLLEnumerator(SinglyLinkedList<T> sll)
{
list = sll;
}
#region IEnumerator Members
public object Current
{
get
{
if (eCurrent
== null)
throw new InvalidOperationException("Current position is null");
return
eCurrent.datum;
}
}
public bool MoveNext()
{
if (eCurrent == null)
eCurrent =
list.Head;
else
eCurrent =
eCurrent.NextElement;
return (eCurrent != null);
}
public void Reset()
{
eCurrent = null;
}
#endregion
}
static private void TestLinkedList()
{
// Create an empty linked list
string strValue = string.Empty;
int nCount = 0;
Element<string> eCurrent = null;
SinglyLinkedList<string> sll = new SinglyLinkedList<string>();
// Invoke variouso operations
eCurrent = sll.Head;
// eCurrent = null since list is empty
nCount = sll.Count;
// 0 since list is empty
// Add some data and examine list (recall Append adds data to
the bottom of the list
// and Prepend adds data to the top of the list)
sll.Append("A");
// A
sll.Append("B");
// A,B
sll.Prepend("C");
// C, A, B
sll.Append("D");
// C, A, B, D
nCount = sll.Count;
// 4
strValue = sll.Head.Value;
// "C"
strValue = sll.Tail.Value;
// "D"
// Delete data and examine list
sll.Delete( "A" );
// "A" which is head is removed. B now
becomes head
strValue = sll.Head.Value; // "C"
strValue = sll.Tail.Value; // "D"
}
A container is an object that contains within it other objects. When implementing a container such as a Stack, Queue or Deque, the first issue to be addressed is which foundational data structure should be used to hold the actual elements of the container. There are two foundational data structures - the array and the linked-list. The sections that followi present a linked-list based implementation as it much cleaner and more efficient than array-based implementations.
Typically, you would develop a container by developing a set of common interfaces that can be implemented according to the type of the container. The following uses the .NET model to explain how common interfaces can be used to implement different types of containers. The most basic container interface is ICollection<T>:
public interface ICollection<T> : IEnumerable<T>,
IEnumerable
{
// Properties
int Count { get; }
bool IsReadOnly { get; }
// Methods
void Add( T item );
void Clear();
bool Contains(T item );
void CopyTo( T[] array, int arrayindex );
bool Remove( T item );
}
ICollection<T> inherits from IEnumerable which means that any container implementing ICollection<T> will be an enumerable collection (i.e., elements of the container can be accessed via foreach C# keyword). The ICollection<T> interface is usually enough to implement containers that usually limit access to their members such as Queue and Stack.
Note that containers implementing ICollection<T> do not support access by index, i.e., accessing an element within the container using array syntax. To provide this support for containers, we can use IList<T> which derives from ICollection<T>. IList<T> represents a collection which can be accessed by index:
public interface IList<T> : ICollection<T>,
IEnumerable<T>, IEnumerable
{
// Properties
T this[int nIndex] { get; set; }
// Methods
int IndexOf(T item );
void Insert(int Index, T item );
void RemoveAt(int index);
}
First thing to note is that even though ICollection<T> inherits from IEnumerable<T> and IEnumerable, IList<T> declaration specifies IEnumerable<T> and IEnumerable as base interfaces. This technique (mentioned here) is known as interface re-implementation and allows IList<T> to re-implement these two base interfaces accordingly
Another interface that specializes ICollection is IDictionary<T> which represents a generic collection of key, value pairs.
Consider a pile of printed papers on your desk. Suppose you add papers only to the top of the pile and remove them only from the top of the pile. At any point in time, the top paper is the only visible paper. What you have here is a stack.
From an implementation perspective, a stack has only two methods to add/remove entries to the stack - Push to add an item (to the top) and Pop to remove an item (from the top). Typically, stacks have an additional method called Top that returns the top of the stack without actually removing the item.
The following presents an implementation of the Stack container based on a singly-linked list:
public interface IStack<T> : ICollection
where T : IEquatable<T>
{
void Push(T oValue);
T Pop();
void Clear();
T Top { get; }
}
public class StackAsLinkedList<T> : IStack<T>
where T :IEquatable<T>
{
// The linked list is used as the
underlying data structure used to hold data
protected SinglyLinkedList<T> list = null;
public StackAsLinkedList()
{
list = new SinglyLinkedList<T>();
}
#region IStack<T> members
public void Push(T o)
{
list.Prepend(o);
// Add item to top of linked list (top of stack)
}
public T Pop()
{
// Check stack
is not empty
if (list.IsEmpty)
throw new
InvalidOperationException("stack is empty");
// Get item
from top of linked list (top of stack)
T oTop = list.FirstValue;
list.Delete(oTop);
return oTop;
}
public void Clear()
{
list.Clear();
}
public T Top
{
get
{
if (list.IsEmpty)
throw new InvalidOperationException("stack is empty");
return
list.FirstValue;
}
}
#endregion
#region ICollection Members
public void CopyTo(Array array, int index)
{
throw new Exception("The method or
operation is not implemented.");
}
public int Count
{
get { return list.Count; }
}
public bool IsSynchronized
{
get { throw new Exception("The method
or operation is not implemented."); }
}
public object SyncRoot
{
get { throw new Exception("The method
or operation is not implemented."); }
}
#endregion
#region IEnumerable Members
public IEnumerator GetEnumerator()
{
return new SLLEnumerator<T>(list);
}
#endregion
}
static private void TestStackAsLinkedList()
{
// Create a stack and push data
StackAsLinkedList<int> intStack = new
StackAsLinkedList<int>();
intStack.Push(10);
intStack.Push(20);
intStack.Push(30);
intStack.Push(40);
intStack.Push(50);
// Invoke various operations on the
stack
int nCount = intStack.Count;
// 5
int nTop = intStack.Top;
// 50
int nCurrent = intStack.Pop();
// 50
nTop = intStack.Top;
// 40
nCount = intStack.Count;
// 4
// Iterate over stack
foreach (int n in intStack)
Trace.WriteLine(n);
}
Consider customers waiting in line to be served. As customers arrive, they join the end of the line waiting to be served. When a customer is served, he/she leaves the beginning of the line and gets served. What you have here is a queue. A queue is used when activities must be done in a first-come first-served bases (in electronics a queue is known as FIFO - First-In First-Out)
From an implementation perspective, a queue has only two methods to add/remove entries to the queue - Enqueue to add an item (to the bottom) and Dequeue to remove an item (from the top). Typically, stacks have an additional method called Head that returns the top of the queue without actually removing the item.
The following presents an implementation of the queue container based on a singly-linked list:
public interface IQueue<T> : ICollection
where T: IEquatable<T>
{
void Enqueue(T item);
T Dequeue();
T Head { get; }
}
class QueueAsLinkedList<T> : IQueue<T> where
T : IEquatable<T>
{
// The linked list is used as the
underlying data structure used to hold data
protected SinglyLinkedList<T> list = null;
public QueueAsLinkedList()
{
list = new SinglyLinkedList<T>();
}
#region IQueue<T> members
public void Enqueue(T o)
{
// Add item to
the bottom of the linked list
list.Append(o);
}
public T Dequeue()
{
// Check stack
is not empty
if (list.IsEmpty)
throw new
InvalidOperationException("stack is empty");
// Remove item
from the top of the linked list
T oTop = list.FirstValue;
list.Delete(oTop);
return oTop;
}
public void Clear()
{
list.Clear();
}
public T Head
{
get
{
if (list.IsEmpty)
throw new InvalidOperationException("stack is empty");
return
list.FirstValue;
}
}
#endregion
#region ICollection Members
public void CopyTo(Array array, int index)
{
throw new Exception("The method or
operation is not implemented.");
}
public int Count
{
get { return list.Count; }
}
public bool IsSynchronized
{
get { throw new Exception("The method
or operation is not implemented."); }
}
public object SyncRoot
{
get { throw new Exception("The method
or operation is not implemented."); }
}
#endregion
#region IEnumerable Members
public IEnumerator GetEnumerator()
{
return new SLLEnumerator<T>(list);
}
#endregion
}
static private void TestQueueAsLinkedList()
{
QueueAsLinkedList<int> q = new QueueAsLinkedList<int>();
q.Enqueue(10);
// 10
q.Enqueue(20);
// 10, 20
q.Enqueue(30);
// 10, 20, 30
q.Enqueue(40);
// 10, 20, 30, 40
q.Enqueue(50);
// 10, 20, 30, 40, 50
// Invoke various operations on the
queue
int nCount = q.Count; // 5
int nTop = q.Head;
// 10
int n1 = q.Dequeue(); // 20, 30,
40, 50 (n1 = 10)
int n2 = q.Dequeue(); // 30, 40,
50 (n1 = 20)
q.Enqueue(60);
// 30, 40, 50, 60
foreach (int n in q)
Trace.WriteLine(n);
}
Consider a deck of playing cards. Cards can be added/removed to/from the top of the deck. Cards can also be added/removed to/from the bottom of the deck. A deque can be considered as the general case in which items can be added/deleted from top and bottom. The word deque is derived from doubled-ended queue. Stacks and queues are just special cases in which items are restricted in where they can be added or removed.
From an implementation perspective, a deque has four methods to add/remove entries - EnqueueHead and EnqueueTail to add an item to either end of the deque, and DequeueHead and DequeueTail to remove an item from either end of the deque. Typically, deques have additional methods called Head and Tail to return the top/bottom of the deque without actually removing the item.
public interface IDeque<T> : ICollection
where T: IEquatable<T>
{
void EnqueueHead(T item);
void EnqueueTail(T item);
T DequeueHead();
T DequeueTail();
T Head { get; }
T Tail { get; }
}
class DequeAsLinkedList<T> : IDeque<T> where T :
IEquatable<T>
{
// The linked list is used as the
underlying data structure used to hold data
protected SinglyLinkedList<T> list = null;
public DequeAsLinkedList()
{
list = new SinglyLinkedList<T>();
}
#region IDeque<T> members
public void EnqueueHead(T o)
{
list.Prepend(o);
}
public void EnqueueTail(T o)
{
list.Append(o);
}
public T DequeueHead()
{
// Check stack
is not empty
if (list.IsEmpty)
throw new
InvalidOperationException("stack is empty");
T oTop = list.FirstValue;
list.Delete(oTop);
return oTop;
}
public T DequeueTail()
{
// Check stack
is not empty
if (list.IsEmpty)
throw new
InvalidOperationException("stack is empty");
T oBottom = list.LastValue;
list.Delete(oBottom);
return oBottom;
}
public void Clear()
{
list.Clear();
}
public T Head
{
get
{
if (list.IsEmpty)
throw new InvalidOperationException("stack is empty");
return
list.FirstValue;
}
}
public T Tail
{
get
{
if (list.IsEmpty)
throw new InvalidOperationException("stack is empty");
return
list.LastValue;
}
}
#endregion
#region ICollection Members
public void CopyTo(Array array, int index)
{
throw new Exception("The method or
operation is not implemented.");
}
public int Count
{
get { return list.Count; }
}
public bool IsSynchronized
{
get { throw new Exception("The method
or operation is not implemented."); }
}
public object SyncRoot
{
get { throw new Exception("The method
or operation is not implemented."); }
}
#endregion
#region IEnumerable Members
public IEnumerator GetEnumerator()
{
return new SLLEnumerator<T>(list);
}
#endregion
}
Recall that we have two foundational data structures - the array and the linked list. We have also illustrated so far three containers - the stack, the queue and the deque. One of the most versatile containers is the list. A list is a series of items which can be individually accessed by index. In general, there are two kinds of lists - the sorted list and the ordered list. In a sorted list, the sequence in which items occur is important. For example, a book index is a sequence of keywords that are arranged alphabetically, in other words, a sorted list. In an ordered list, the sequence in which items occur is not important. For example, the types of containers presented in this chapter are not really sorted by anything.
The following shows how to implement an ordered list using a linked list as the underlying foundational data structure. Furthermore, the operations of the ordered list are described by the IList<T> generic interface:
public interface IList<T>
{
T this[int index] { get; set; }
int IndexOf(T item);
void Insert(int index, T item);
void RemoveAt(int index);
}
In the following ordered list implementation, a recurring theme is accessing or locating an element at a given index. The main approach is start at the head of the linked list and then loop x number of times until the item is located. Appropriate checks must be added to ensure that index is within limits. For example, the following code shows how to locate the ith element in a linked list:
// An indexer to access the element at index n
public T this[int n]
{
get
{
// Check that
given index is within range
if ((n < 0) || (n > sll.Count))
throw new
IndexOutOfRangeException("index " + index + " is out of range");
// Now loop
over the linked list to retrieve element at the given index. Start at the head
of the linked list
// and loop until the given index is
reached. Check in each iteration that the element is valid (i.e., not null)
Element<T> element = sll.Head;
for (int i = 0; i < index && element
!= null; i++)
element =
element.NextElement;
// Return
element at index n
return element.Value;
}
The following shows how to implement a list using a linked list:
class OrderedListAsLinkedList<T> : IList<T>
where T : IEquatable<T>
{
// The linked list is used as the
underlyind data structure used to hold data
protected SinglyLinkedList<T> sll = null;
public OrderedListAsLinkedList()
{
sll = new SinglyLinkedList<T>();
}
#region Helpers
Element<T> GetElementAtIndex(int index)
{
// Check that
given index is within range
if ((index < 0) || (index >
sll.Count))
throw new
IndexOutOfRangeException("index " + index + " is out of range");
// Now locate
the ith element and insert a new element immediately after the locate element
Element<T> element = sll.Head;
for (int i = 0; i < index && element
!= null; i++)
element =
element.NextElement;
// Element at
this index is guaranteed to be found since index is within range.
// Now just return element
return element;
}
#endregion
#region IList<T> Members
public int IndexOf(T item)
{
int nIndex = 0;
for (Element<T> element = sll.Head;
element != null; element = element.NextElement)
{
if (element.Value.Equals(item))
return nIndex;
nIndex++;
}
// If we have
reached end of loop then item has not been found
return -1;
}
public void Insert(int index, T item)
{
// Retrieve
element at given index
Element<T> element =
GetElementAtIndex(index);
// Insertion
position located. Insert new element
element.NextElement = new
Element<T>(sll, item, element.NextElement);
}
public void RemoveAt(int index)
{
// Now locate
the element just before the element to be deleted
Element<T> element =
GetElementAtIndex(index);
sll.Delete(element.Value);
}
public T this[int index]
{
get
{
// Retrieve element at given index
Element<T> element = GetElementAtIndex(index);
return
element.Value;
}
set
{
Insert(index,
value);
}
}
#endregion
#region ICollection<T> Members
public void Add(T item)
{
sll.Append(item);
}
public void Clear()
{
sll.Clear();
}
public bool Contains(T item)
{
return (IndexOf(item) != -1);
}
public void CopyTo(T[] array, int nStartCopyIndex)
{
int nCount = sll.Count;
Element<T> eCurrent = sll.Head;
for (int i = 0; i < nCount; i++)
{
if (i >=
nStartCopyIndex)
{
array[i - nStartCopyIndex] = eCurrent.Value;
eCurrent = eCurrent.NextElement;
}
}
}
public int Count
{
get { return sll.Count; }
}
public bool IsReadOnly
{
get { return false; }
}
public bool Remove(T item)
{
bool bStatus = false;
if (Contains(item))
{
sll.Delete(item);
bStatus =
true;
}
return bStatus;
}
#endregion
#region IEnumerable<T> Members
public IEnumerator<T> GetEnumerator()
{
return (IEnumerator<T>)new
SLLEnumerator<T>(sll);
}
#endregion
#region IEnumerable Members
System.Collections.IEnumerator
System.Collections.IEnumerable.GetEnumerator()
{
return new SLLEnumerator<T>(sll);
}
#endregion
}
static private void TestOrderedListAsLinkedList()
{
OrderedListAsLinkedList<int> list = new
OrderedListAsLinkedList<int>();
list.Add( 10 );
list.Add( 20 );
list.Add( 30 );
list.Add( 40 );
list.Add( 50 );
// Add, remove and check results
bool bContains;
int n1 = list.IndexOf( 30 );
// 2
int n2 = list.IndexOf( 100 );
// -1
list.RemoveAt( n1 );
int nIndex = list.IndexOf( 30 ); // -1
bContains = list.Contains( 30 );
// Copy elements
int[] arr = new int[list.Count];
list.CopyTo( arr, 0 );
}
A sorted list is similar to an ordered list - they both hold items in sequence. However, in a sorted list, the position of an item is not arbitrary - the items in the sequence appear in a specific order regardless of how items were added. For example, items may appear ordered from smallest to largest.
When inserting an item into a sorted list, we has as a precondition that the list is already sorted. Once an item is inserted, we have the postcondition that the list is still sorted. Therefore, all the items initially in the list that are larger than the item to be inserted need to be moved to the right by one position. The following figure illustrates:
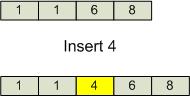
The algorithm used to insert an item in a sorted list (based on a linked list) is as follows: The existing sorted linked list is traversed to locate the linked list element which is greater than or equal to the object that is to be inserted. The traversal is done using two variables elementPrevious and elementCurrent. In the event that an item to be inserted is smaller than the first item in the list, the Prepend method is used.
A sorted list implementation is exactly the same as that of the ordered list. The only difference is in the Insert method which is given below ( in other words, replace ordered list implementation of Insert with the method below and you get a sorted list - you will also need to remove IList interface/implementation):
public void Insert(T item)
{
Element<T> elementCurrent = null;
Element<T> elementPrevious = null;
for (elementCurrent = sll.Head; elementCurrent != null;
elementCurrent = elementCurrent.NextElement)
{
if (item > elementCurrent.Value)
break;
elementPrevious = elementCurrent;
}
if (elementPrevious == null)
sll.Prepend(item);
else
elementPrevious.InsertAfter(item);
}