![]()
Hashing is used for data structures whose design objective is providing efficient insertion and find operations. In order to meet this design objective, certain concessions are made: 1) we do not require that there be specific ordering of items in the container and 2) it is not a primary objective to make removal as efficient as insertion and find.
To meet the design objective of providing efficient insertion and find operations, we need a data structure for which both insertion and find operations are O(1) in the worst case. This constant time performance objective immediately leads us to the following conclusion: Our implementation must based on an array rather than on a linked list. This is because we access the kth element in an array in constant time whereas the same operation in a linked list takes O(k) time.
Previously two searchable containers were considered - the ordered list and the sorted list. For an ordered list, the cost of insertion is O(1) while the cost of find is O(n). For a sorted list, the cost of insertion is O(n) and the cost of find is O(log n). In order to meet this performance objective of constant time insertion and find, we need a way to do them without performing a search. That is, given an item x, we need to be able to determine directly from x the array position where it is stored.
We wish to implement a searchable container that will be used to store strings from the set of strings K:
S = {"one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"}
Suppose that we also define a function f(x) given by the following table:
| x | f(x) |
| "one" | 1 |
| "two" | 2 |
| "three" | 3 |
| "four" | 4 |
| "five" | 5 |
| "six" | 6 |
| "seven" | 7 |
| "eight" | 8 |
| "nine" | 9 |
| "ten" | 10 |
We implement the searchable container by creating an array whose length is 10. To insert any of the above items, we store it at position f(x) - 1. Similarly, to locate an item x we check if it is at position f(x) - 1. For example, to store item "three", we evaluate f("three") and get back 3. Therefore, we store item "three" at location 2. Similarly, to locate item "three", we evaluate f("three") which returns 3 and check if the item exists at location 2. If the function f(x) can be evaluated in constant time, then both the find and insert operations are O(1).
The object so far is designing a container that will hold some number of items of a given set K. In this context, the elements of K are called keys. The general approach is to store the keys in an array where the position of each key is determined by a function f(key) called the hash function. The hash function f(key) determines the position of the key directly from the key's value.
In the general case, we expect the size of the set of keys K to be relatively large or even unbounded. On the other hand, we also expect the number of items stored in the container to be significantly less than the size of K. In other words, if |K| is the size of K and n is the number of items stored in the container, then we expect n << |K|. Therefore, it seems prudent to use an array of size M where M ≤ |K|.
Consequently, what we need is a function that will map the set of value to be stored in the container to subscripts in an array of length M. This function is called the hash function:
h: K à {0, 1, 2, ... M-1}
In general, because M ≤ |K|, the mapping defined by the hash function will be many-to-many. That is, there will exist many pairs of distinct keys x and y such that x ≠ y, for which h(x) = h(y). This situation is called a collision (several approaches for dealing with collisions are explored in the following sections).
So what are the characteristics of a good hash function?
Ideally, given a set of keys {k1, k2, ..., kn}, the set of hash values {h(k1), h(k2), ..., h(kn)} contains no duplicates. In practice, unless we know something about the keys chosen, we cannot guarantee that there will be no collisions. For example, if the keys in our application are telephone numbers from a specific area code, then the area code should not be part of the hash function, as it will be the same for each telephone number.
Spreading keys evenly means that the hash values computed by the hash function h(x) are uniformly distributed. Unfortunately, in order to say something about the distribution of hash vales, we need to know something about the distribution of the keys.
This does not mean that it is easy to write the algorithm to compute the hash function. It just means that the running time of the hash function should be O(1).
In the following sections we explore several hashing methods. Here we assume that we are dealing with integer-values keys and that the value of the hash function falls between 0 and M-1:
| Function |
|
| Procedure | Divide the key x (recall we are dealing with integers only) by M and use the remainder modulo, |
| Notes | M is often chosen as a prime number (5,7,11,13,17,... ) and can be determined at runtime. |
For example:
public class DivisinHash
{
private static readonly int M = 1023;
public static int Hash(int x)
{
return Math.Abs(x) % M;
}
}
A potential disadvantage is that consecutive keys map to consecutive has values. While this ensures that consecutive keys do not collide, it does mean that consecutive array locations will be occupied. The other hashing methods that follow tend to scatter consecutive keys.
This method avoids doing any division since integer division is slower than integer modification. By avoiding division we can potentially improve the performance of the hashing algorithm. We can avoid division by making use of the fact that a computer does finite-precision integer arithmetic. For example, all arithmetic is done modulo W where W = 2w is a power of 2 such that w is the word size of the computer.
| Function |
|
| Procedure |
Assume that M is a power of 2, M = 2K, where k ≥ 1. Because M and W are both a power of 2, the ratio M/W is equal to 2w-k. Therefore, in order to multiply the term (x2 mod W) by M/W we simply shift to the right by w-k bits. In effect, we are extracting k bits from the middle of the square of the key x, hence the name. termine the number of bits in your OS's integer representation. (in C# do a typeof(int) to get number of bytes) T |
| Notes | Middle-square method scatters consecutive keys nicely, , however, since this method only considers a subset of bits in the middle of x2, keys which have a large number of leading or trailing zeros will collide. |
For example:
public class MiddleSquareHash
{
private const int k = 10;
private const int w = 32;
// size of System.Int32
public static int Hash(int x)
{
// Note that we
cast to uint before the shift so as to cause the right-shift operator to insert
zeros on the left.
// Therefore, the result always falls
between 0 and M-1
return (int)((uint)(x * x)) >> (w-k);
}
}
Multiplication method is a very simple variation of the middle-square method. Instead of multiplying the key x by itself, we multiply x by a carefully chosen value a, and then extract the middle k bits from this result.
| Function |
|
| Procedure | a should be chosen such that it does not have leading or trailing zeros. |
| Notes |
If we choose a such that it is relatively prime to W, then there exists another number a' such that aa' = 1 (mod W). In other words, a' is the inverse of (a mod W). Such a number has the nice property that ax multiplied by a' will give back x. In other words, axa' = aa'x = 1x. There are many possible constants with the desired properties, and one possibility which is suitable to 32-bit arithmetic (W = 232), is a =2654435769 with binary representation of 1001 1110 0011 0111 0111 1001 1011 1001 |
For example:
public class MultiplicationHash
{
private const int k = 10;
private const int w = 32;
// size of System.Int32
private const uint a = 2654435769U;
public static int Hash(int x)
{
// Note that we
cast to uint before the shift so as to cause the right-shift operator to insert
zeros on the left.
// Therefore, the result always falls
between 0 and M-1
return (int)((uint)(x * a)) >> (w-k);
}
}
The hashing methods presented earlier dealt only with integer keys. In reality keys might be strings or even objects of other classes. In general, given a set of keys K, and a positive constant M, a hash function is a function of the form:
h: K à {0, 1, 2, ... M-1}
In practice, it is convenient to implement the hash function h as a composition of two functions, f and g. The function f maps keys into integers and function g maps integers to {0, 1, ..., M-1}. Therefore, the hash function is given by:
h(x) = g( f(x) )
In other words, we have decomposed the problem into two parts. The first involves finding a suitable mapping from the set of keys K to non-negative integers, and the second problem involves mapping these non-negative integers into the internal [0, M-1]. The hashing functions described earlier (division, middle-square, and multiplication) all deal with integer values which is what function g is required to do. On the other hand, the choice for function f depends on the characteristics of its domain.
The following considres various different domains (sets of keys) and discusses a suitable hash function for each. Each domain considered corresponds to a C# class.Recall that a C# class ultimately derives from System.Object which declares a method called GetHashCode(). object.GetHashCode() therefore, corresponds to the function f which maps keys into integers.
C# integral types (byte, sbyte, char, short, ushort, int, uint, long, ulong) are the easiest to hash into integers. A suitable hash function is therefore the identity function f(x) = x:
public override int GetHashCode()
{
return (int)obj;
// recall the key is an integer so that cast should not
fail
}
C# floating point types (float and double) are just as easy as integral types. We seek a function f(x) which maps x (a floating point value) to a non-negative integer. This must be able to deal with the extremely wide range of floating-point values. For example, what is the integer representation for 0.0000003? 123.456768798? 999999.123?
Every non-zero floating-point number can be represented as:
-1s x m x 2e s e{0,1}. ≤ m ≤
where s is called the sign, m is called the mantissa or significant, and e is called the exponential. This suggests the following function definition for f(x):
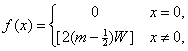
Where W i=2w such that w is the word size of the machine. In the IEEE standard floating-point format, the least significant 52 bits of a 64-bit floating point number represent the quantity m' = (m - 0.5) x 253. Since int is 32 bits, W = 232. f(x) then becomes m' 233/ 253 = m' / 220.
In other words, we compute the hash function simply by right-shifting the binary representation of the floating-point number by 20 bits. The following program illustrates:
public override int GetHashCode()
{
long lbits = System.BitConverter.DoubleToInt64Bits((double)obj);
return(int)((ulong)lbits >> 20);
}
The basic ideas is that a string is simply a sequence of characters that may be arbitrarily long. The challenge is to devise a function that allows us to map from an unbounded domain into the finite range of int. Please refer to Brun Preiss book on data structures for more information.
Recall that hashing provides a way to determine the position of an object directly from the object itself. Given an object x, we determine its position by evaluating the appropriate hash function h(x). Assume we determined the position and inserted the object at that position. Assume now that we would like to retrieve object x. But in order to find object x, we need to determine its location, and to determine its location, we need to evaluate h(x) ! That is we need to have object x in the first place.
In practice, when using hashing, we are dealing with keyed data. In other words, we are dealing with data of the form (key1, value1), (key2, value2), etc. where keyn is used to locate valuen.
.