
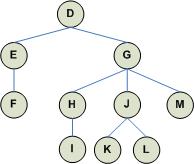
A tree is used to represent hierarchical structures. An example of a tree data structure is shown below - note how the tree is shown upside-down:
Definition: A tree is a collection of nodes. One of the nodes is designated as the root node, with the remaining nodes each being a sub-tree. For example, node D is the root node and nodes E and G are sub-trees of root node D. Nodes H, J, and M are considered sub-trees of node G, while node F is a sub-tree of node E.
For convenience, the following general notation is used to represent a tree: T = {r, T1, T2, ... , Tn}. Note that this definition is recursive - a tree is defined in terms of itself. For example, the three trees above are represented as follows:
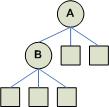
Ta = {A}.
Tb = {B, {C}}.
Tc = {D, {E,{F}}, {G, {H,{I}}, {J,{K}, {L}}, {M}}}.
Terminology:
Consider a tree T = {r, T1, T2, ... , Tn} where n ³ 0:
Degree: The degree of a node is the number
of sub-trees associated with it.
For example, the degree of T is
n, Tb is 1 and Tc
is 2.
Leaf: A node of degree zero has no sub-trees. Such
a node is called leaf.
For example, in table Tc,
nodes F, I,
K, L,
and M are leaves.
Child: Each root of a sub-tree is called a child.
For example, In table Tc,
nodes F is a child of node
E, and node E
is a child of node D.
Parent: The root node r
of tree T is called the parent of all roots
ri of sub-trees Ti.
For example, In table Tc,
node D is the parent of nodes
E and node G.
Siblings: Two roots ri
and rj of distinct sub-tree
Ti and Tj
of tree T are called siblings.
For example, In table Tc,
nodes E and G
are siblings. Nodes H, J,
and M are also siblings.
Path: Given a Tree T
containing a set of nodes r, a path in the
tree T is defined as a non-empty sequence
of nodes
For example, in tree Tc, the
path P = {D, G, H, I} is path going from
node D to node I
through G and H.
Level (or Depth): The level of depth
of a node ri in tree T
is the length of the unique path from the root r
to ri. The root of tree T
is at level zero.
For example, in tree Tc, the
depth of node H is 2 and of node
K is 3.J,{
Ancestor/Descendant: Node
ri is a descendant of node
rj is there exists a distinct path
in tree T from node rj to node
ri. Similarly, node
rk is an ancestor of node
rl is there exists a distinct path
in tree T from node rk to node
rl.
For example, in tree Tc,
I is a descendant of node
G and node G
is an ancestor of node I.
Recall that the degree of a node is the number of sub-trees for that node. The general case allows each node to have a different degrees - for example a node may have 3 sub-trees and another node may have 2 sub-trees. In this section we consider N-ary trees in which each node has a degree N. In other words, a N-ary tree is a tree in which each node has N sub-trees exactly.
Note: An empty tree is one that has no nodes. However, from an object-oriented perspective, an empty tree must be instance of the some object class. Therefore, it is incorrect to represent an empty tree with null since null refers to nothing at all.
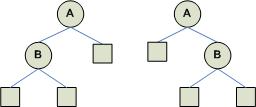
The following figure shows some 3-ary trees. Square boxes denote empty trees and circle denote non-empty trees.

The above trees are represented as follows:
Ta = {A,0,0,0}.
Tb = {B,{C,0,0,0},0,0}.
Tc = { D,{E,{F,0,0,0},0,0},{G,{H,{I,0,0,0},0,0},{J,{K,0,0,0},{L,0,0,0},0},{M,0,0,0}},0}
In mathematics, elements of a set are normally unordered. However, must practical implementations of trees define an implicit ordering of sub-trees. Therefore, it is usual to assume that sub-trees are ordered. For example, the two tertiary trees Tb = {B,{C,0,0,0},0,0}. and Tb' ={B,0,{C,0,0,0},0}. are considered unequal. Trees in which order of sub-trees is important are called ordered trees.
A binary tree is an N-ary tree for which N is 2. Binary trees are extremely important and useful. For example, there is an interesting relationship between binary trees and the binary numbering system. Binary trees are also useful for the representation of mathematical expressions
For convenience, the following general notation is used to represent a binary tree: T = {r, TL, TR}. Note that this definition is recursive - a tree is defined in terms of itself. The tree TL is called the left sub-tree and the tree TR is called the right sub-tree. The following shows examples of two binary trees:
Working with trees almost always involves some form of tree traversal. Tree traversal is the process of visiting each node in the tree. There are two different methods in which to visit systematically all the nodes of a tree - depth first traversal and width-first traversal. Within depth-first traversal, you can have pre-order traversal, in-order traversal, and post-order traversal.
Consider the following binary tree:
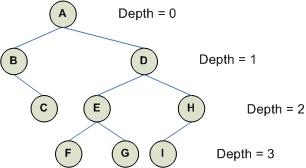
This is a recursive procedure (the procedure calls itself repeatedly):
Visit the root first
For each of the sub-trees, do a pre-order traversal in the order given
For the above binary tree, a pre-order traversal visits the node as follows: A, B, C, D, E, F, G, H, I.
In-order traversal only makes sense for binary trees. In-order traversal visits the root in between visiting the left and right sub-trees. This is a recursive procedure (the procedure calls itself repeatedly):
Traverse the left sub-tree.
Visit the root.
Traverse the right sub-tree.
For the above binary tree, a pre-order traversal visits the node as follows: B, C, A, F, E, G, D, I, H.
This is a recursive procedure (the procedure calls itself repeatedly):
For each of the sub-trees of the root, do a post-order traversal in the order given
Visit the root last.
For the above binary tree, a pre-order traversal visits the node as follows: C, B, F, G, E, I, H, D, A.
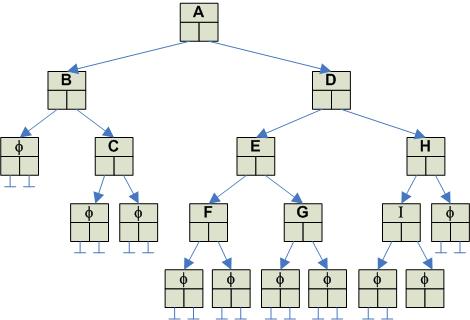
The recursive definition of a tree T = {r, T1, T2, ... , Tn} has important implications when considering the implementation of a tree. In effect, since a tree contains zero or more sub-trees, when implemented as a container, we get a container that contains other containers. The figure on the right shows the general approach used to implement the tree on the left:
 |
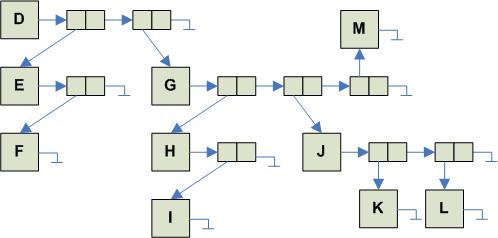 |
The basic idea is this: each node has associated with it a linked-list of its sub-trees. A linked list is used because there is no restriction on length. This allows each node to have an arbitrary degree .
By definition, a Nary tree is either an empty tree or a tree composed of a root and exactly N sub-trees. The following represent a Nary tree where N = 3.
 |
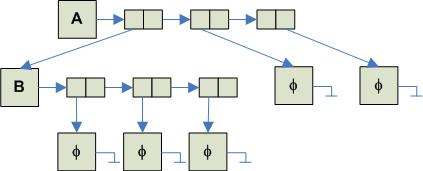 |
The basic idea is this: each node has associated with it an array of length N of sub-tree nodes. An array is used because we know that the arity of the tree is a fixed number, N.
By definition, a binary tree is either an empty tree or a tree composed of a root and exactly 2 sub-trees. The following represent a binary tree where N = 2.
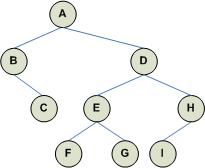 |
 |
The basic idea is this: each node has associated with it a left sub-tree and a right sub-tree . While we could use an array because we know that the arity of the tree is a fixed number 2, it is more efficient for each node to contain two fields that refer to the left and right sub-trees of that node.
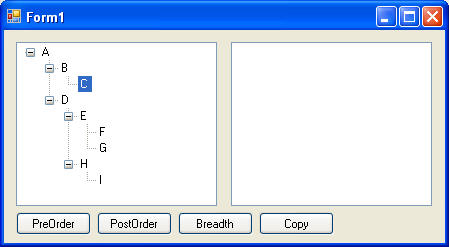
The following example shows how to traverse an already existing tree. The tree is actualy a Windows Forms TreeView whose nodes were added manually. Results are shown after the code:
public partial class Form1 : Form
{
int nCounter = 0;
public Form1()
{
InitializeComponent();
}
private void btnCopy_Click(object sender, EventArgs e)
{
TreeNode nodeNew =
CopyTree(trvLeft.Nodes[0]);
trvRight.Nodes.Add(nodeNew);
}
private void btnPreOrder_Click(object sender, EventArgs e)
{
nCounter = 0;
PreOrderTraversal(trvLeft.Nodes[0]);
}
private void btnPostOrder_Click(object sender, EventArgs e)
{
nCounter = 0;
PostOrderTraversal(trvLeft.Nodes[0]);
}
private void btnBreadth_Click(object sender, EventArgs e)
{
nCounter = 0;
BreadthTraversal();
}
#region Implementation
private void BreadthTraversal()
{
TreeNode nodeCurrent = null;
Queue q = new Queue();
q.Enqueue(trvLeft.Nodes[0]);
while (q.Count != 0)
{
nodeCurrent =
(TreeNode)q.Dequeue();
VisitNode(nodeCurrent);
// Collect next level's nodes for the current node
foreach (TreeNode node in nodeCurrent.Nodes)
q.Enqueue(node);
}
}
private void PreOrderTraversal(TreeNode nodeCurrent)
{
VisitNode(nodeCurrent);
foreach (TreeNode node in
nodeCurrent.Nodes)
PreOrderTraversal(node);
}
private void PostOrderTraversal(TreeNode nodeCurrent)
{
foreach (TreeNode node in
nodeCurrent.Nodes)
PostOrderTraversal(node);
VisitNode(nodeCurrent);
}
// Copying a tree is done using a
Post-Order traversal
private TreeNode CopyTree(TreeNode node)
{
TreeNode[] nodes = new
TreeNode[node.Nodes.Count];
for (int i =0; i < node.Nodes.Count;
i++)
{
nodes[i] =
CopyTree(node.Nodes[i]);
}
TreeNode nodeNew = new
TreeNode(node.Text);
nodeNew.Nodes.AddRange(nodes);
return nodeNew;
}
// Visiting a node is defined by
adjusting the text of the node with a counter
private void VisitNode(TreeNode node)
{
node.Text += nCounter.ToString();
nCounter++;
}
#endregion
}
Results are shown below. During each traversal visiting a node was defined by adjusting the text of the node to show the order in which that node was accessed. Figure below is original tree:
Traversing tree using Pre-Order traversal. Note how node text shows order in which nodes were accessed (root was accessed first):
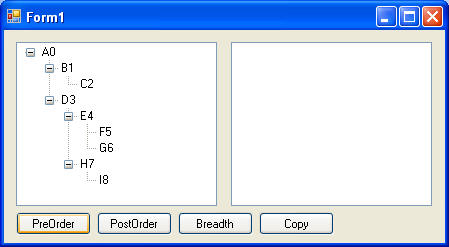
Traversing tree using Post-Order traversal. Note how node text shows order in which nodes were accessed (root was accessed last):
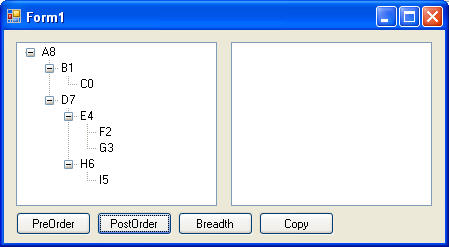
Traversing tree using Breadth traversal. Note how node text shows order in which nodes were accessed (root was accessed first):
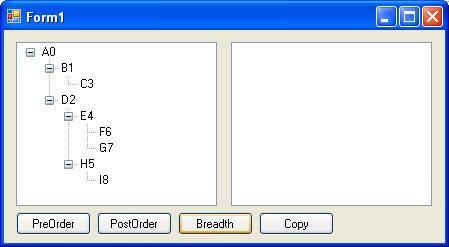
Copying a tree using a Post-Order traversal:
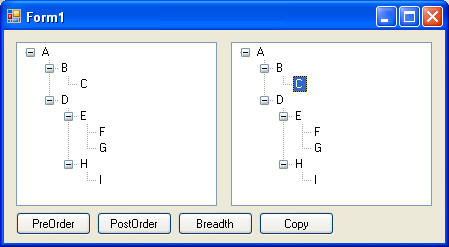
The first step in creating a N-ary tree (or any tree) is to create a class that represents a node. From an implementation point of view, a node typically contains data and a list of its child nodes:
// A strongly-typed
collection of Node<T> instances
internal class NodeList<T> : Collection<Node<T>>
{
// Data members
private int _degree;
// Constructors
public NodeList() : base() { /*
Empty implementation */ }
public NodeList(int degree_)
{
// Add the
specified number of nodes
_degree = degree_;
for (int i = 0; i < degree_; i++)
Items.Add(default(Node<T>));
}
// Finds a node by its value
public Node<T> FindByValue(T value)
{
foreach (Node<T> node in Items)
{
if (node.Value.Equals(value))
return node;
}
// No matching
node was found. Return null
return null;
}
}
internal interface INode<T>
{
T
Value { get; }
bool IsEmpty
{ get; }
NodeList<T> Children { get; }
int Degree
{ get; }
}
// The following node represents a node in a general tree,
one whose nodes can have
// an arbitrary number of children. The NodeList member variable represents the
node's
// children
internal class Node<T> : INode<T>
{
// Data members
private T
_value = default(T);
private NodeList<T> _nodeList = null;
private int
_degree = 0;
// Constructors
public Node(int degree_, T data_) : this(degree_,
data_, null) { /* Empty implementation */ }
public Node(int degree_, T data_, NodeList<T> nodeList_ )
{
_degree = degree_;
Value = data_;
Children = (nodeList_ == null) ? new
NodeList<T>(degree_) : nodeList_;
}
// INode
public T Value
{
get { return _value; }
set { _value = value; }
}
public NodeList<T> Children
{
get { return _nodeList; }
set { _nodeList = value; }
}
public bool IsEmpty
{
get { return (Children.Count == 0); }
}
public int Degree
{
get { return _degree; }
}
}
Note that class NodeList<T> inherits from System.Collectioins.Object.Collection<T> class. This class provides a ready-to-use class for creating generic collections. You can either instantiate an instance of Collection<T> directly, or derive from it to create you own generic collection. Collection<T> is always modifiable. If we wanted the node list to be read-only, we can derive from ReadOnlyCollection<T>. Finally, note that elements in Collection<T> are accessed via a zero-based index.
Note: Collection<T> is very similar to List<T>. Both class inherit from the same set of interfaces. List<T> has a richer set of members (LastIndexOf, Find, FindAll, FindIndex, etc.), however, Collection<T> is really meant to be used as base class to make it easier to create a custom collection rather than having to implement IList<T> and others. For example, one reason to use Collection<T> instead of List<T> is if you require events to be fired when items are added/removed from the list.
The code that follows implements a N-ary Tree:
internal interface INaryTree<T>
{
// Properties
Node<T> Root {get; set; }
int Degree { get; }
// Methods
void Clear();
Node<T> GetSubtree(int nIndex);
void AttachSubtree(int nIndex,
Node<T> node);
Node<T> DetachSubtree(int nIndex);
}
internal class NaryTree<T> : INaryTree<T>
{
// Data members
private Node<T> _root = null;
private int _degree = 0;
// Constructors
public NaryTree(int degree_)
{
_degree = degree_;
_root = null;
}
public NaryTree(int degree_, Node<T> root_)
{
Degree = degree_;
Root = root_;
}
// INaryTree interface
public int Degree
{
get { return _degree; }
set { _degree = value; }
}
public Node<T> Root
{
get { return _root; }
set { _root = value; }
}
public virtual void Clear()
{
_root = null;
}
public virtual Node<T> GetSubtree(int nIndex)
{
return _root.Children[nIndex];
}
public virtual void AttachSubtree(int nIndex, Node<T> node)
{
if (_root.IsEmpty)
throw new
InvalidOperationException("Tree is empty");
_root.Children[nIndex] = node;
}
public virtual Node<T> DetachSubtree(int nIndex)
{
if (_root.IsEmpty)
throw new
InvalidOperationException("Tree is empty");
// Save result
before overwriting it with a new tree (detaching)
Node<T> result =_root.Children[nIndex];
_root.Children[nIndex] = new
Node<T>(Degree, default(T));
return result;
}
public void DoBreadthTraversal(Node<T> root)
{
Node<T> nodeCurrent = null;
Queue q = new Queue();
int nLevel = -1;
q.Enqueue(root);
while (q.Count != 0)
{
nodeCurrent =
(Node<T>)q.Dequeue();
// Output ndoe information
if (nodeCurrent
== null)
Trace.WriteLine("node is null");
else
{
Trace.WriteLine(nodeCurrent.Value);
foreach (Node<T> node in nodeCurrent.Children)
q.Enqueue(node);
}
}
}
}
The following tree is created using the code below. Note how we start with the bottom nodes and then add these up until we finally add the root:
static private void TestNaryTree()
{
// E node
int nDegree = 3;
Node<string> nodeE = new Node<string>(nDegree, "E");
nodeE.Children[0] = new Node<string>(nodeE.Degree, "F");
// H node
Node<string> nodeH = new Node<string>(nDegree, "H");
nodeH.Children[0] = new Node<string>(nodeH.Degree, "I");
// J node
Node<string> nodeJ = new Node<string>(nDegree, "J");
nodeJ.Children[0] = new Node<string>(nodeJ.Degree, "K");
nodeJ.Children[1] = new Node<string>(nodeJ.Degree, "L");
// M node
Node<string> nodeM = new Node<string>(nDegree, "M");
// G node
Node<String> nodeG = new Node<string>(nDegree, "G");
nodeG.Children[0] = nodeH;
nodeG.Children[1] = nodeJ;
nodeG.Children[2] = nodeM;
// D node
Node<string> nodeD = new Node<string>(nDegree, "D");
nodeD.Children[0] = nodeE;
nodeD.Children[1] = nodeG;
// Finally create the tree with nodeD
as the root
NaryTree<string> tree = new NaryTree<string>(3);
tree.Root = nodeD;
// Traverse the tree
tree.DoBreadthTraversal(tree.Root);
}
Recall that arrays are stored in contiguous blocks of memory. This means that the time it takes to access a particular element of an array does not change as the number of elements in the array increases. Nary and binary trees, however, are not stored in contiguous blocks of memory. Rather, nary and binary trees have a reference to a root node which in turn has references to its child nodes; these child nodes have references to their child nodes and so on. This effectively means that the various nodes that make up a tree are scattered throughout the CLR managed heap. They are not necessarily contiguous.
Now if you wanted to access a particular node in a tree, you would have to traverse the tree looking for a node with a particular value. There is no direct access to a node as with an array. Searching a tree can take linear time as potentially all nodes need to be examined. In other words, as the number of nodes in the tree increases, so does the number of steps required to find a node. A binary tree may not offer any benefit over an array. However, by intelligently organizing items in a binary tree, we can greatly improve the search time. Enter Binary Search Trees (BSTs).
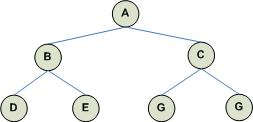
A Binary Search Tree is a special kind of binary trees designed to improve the efficiency of searching through a binary tree. BSTs exhibit the following important property: For any node, the value of every descendant node (not child node!) in the left subtree of n is less than the value of n, and the value of every descendant node (not child node!) in the right subtree of n is greater than the value of n. The following figure illustrates:
Note the following:
All the node values to the left of A must be less than A and all the node values to the right of A must be greater than A.
Similarly, all the the node values to the left of B must be less than B and all the node values to the right of B must be greater than B. But also note that all nodes in B's left and right subtrees must be less than the value of node A.
Similarly, all the the node values to the left of C must be less than C and all the node values to the right of C must be greater than C. But also note that all nodes in C's left and right subtrees must be greater than the value of node A.
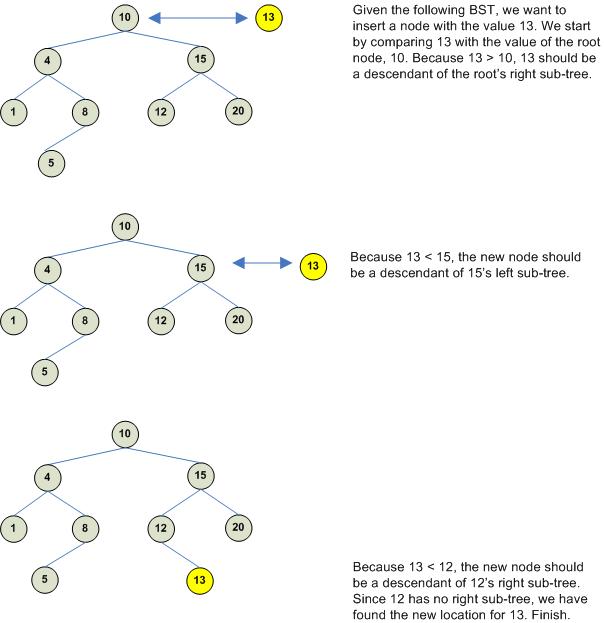
The following shows two examples of binary trees. The one on the left is a BST but the one on the right is not a BST (the right child of node 10 is 8, which should have been greater than 10):
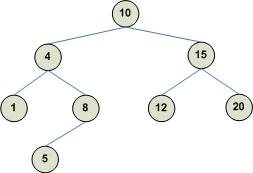
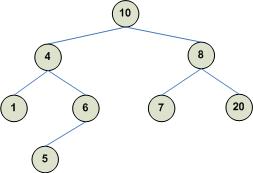
Consider the above left (valid) BST. To search for node 12 you would proceeds as follows: Start with the node and note that node 12 is greater than node 10, therefore node 12 should exist as a descendant to the right of node 10. Obtain the right child of node 10, which is node 15 and note that node 12 is less than node 15, therefore node 12 should exist as a descendant to the left of node 15. Obtain the left child of node 15 and note that this node has the required value.
More formally, the search algorithm goes as follows: you have the root node and the node value you wish to search for. Perform a number of comparisons until a null reference is obtained or until the node is found. At each step we deal with two nodes - node c which is the current node in the tree and node n which is the node we are searching for. Initially c is the root node. Perform the steps as follows:
If c is null, exit. Node n is not in the BST.
Compare c's value and n's value.
If n's value is less than c's value, then if n exits, it should exist in c's left subtree. Let c = c.LeftSubtree and go to step 1.
If n's value is greater than c's value, then if n exits, it should exist in c's right subtree. Let c = cRightSubtree and go to step 1.
Note that the search time to find a node in a BST depends on the the BST's topology, in other words, how the node are organized with respect to each other. For example, assume we wanted to insert nodes with the following values into a BST: 10, 15, 17, 20, and 30. When 10 is inserted, it is inserted as the root. Next, 15 is inserted as 10's right child. 17 is inserted as 15's right child and so on. The resulting BST is one whose topology is similar to an array:
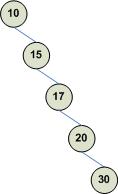
Searching this tree will take the same time (if not more) as searching an array. This is because after each comparison the problem space is reduced by 1 node and not by half of the current nodes. Therefore, the time it takes to search a BST depends on its topology, and the topology of a BST depends on the order in which nodes are inserted. Now consider adding the same nodes in the following order: 17. 10, 20, 15, 30 which result in a balanced BST (a balanced BST is one that exhibits a good ratio of depth to height):
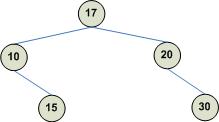
Obviously searching this BST is much more efficient than searching the previous BST as the number of items to search after each comparison is reduced significantly.
The topology is dependent on the order in which data was added to the BST. Data that is ordered or near-ordered will cause the BST's topology to resemble a long skinny tree (undesirable) rather than a short fat tree (desirable). The problem with BSTs is that they can easily become unblanaced. There are a special of BSTs that are self-balancing - as new nodes are added or existing nodes are deleted, these BSTs automatically adjust their topology to maintain an optimal balance. Examples of self-balancing trees are AVL trees and SkipLists
When inserting a new node, it will always be inserted as a new leaf. The only challenge is to find the BST node that will become the new node's parent. Like the searching algorithm, we need to make comparisons between the current node c and the node to be inserted n. We also need to keep track of node c's parent. Insertion proceeds as follows:
Initially c is the BST root and
parent is null. If c
is null, parent will be parent of
n. Compare n and
parent values
if (c == null)
{
parent = n.parent;
if (n.Value < parent.Value) parent.LeftTree = n;
if (n.Value > parent.Value) parent.RightTree = n;
}
If c is not null,
compare c and n values
as follows:
if (c != null)
{
parent = c;
if (n.Value < parent.Value) parent.LeftTree = n;
if (n.Value > parent.Value) parent.RightTree = n;
if (n.Value == parent.Value) throw new
InvalidOperationException( "Node already exists");
}
Repeat this process
Note that searching a BST and inserting a new node into a BST follow the same approach. This insertion procedure is shown graphically below:
Deleting a node is more difficult that inserting a node because deleting a node that has children requires that some other node be chosen to replace the hole created by the deleted node. If the node chosen to fill this hole is not chosen correctly, the tree may no longer be a valid BST.
The first step to delete a node is to search for the node the be deleted. We already know how to do this. The next step is to select a node from the BST to take the deleted node's position. The general approach is this: Leaf node can be deleted directly without any considerations. If the node is non-leaf, either swap it with the smallest value (key) in the right subtree or with the largest value (key) in the left subtree. At least on such swap is always possible since the node is a non-leaf node and therefore, at least one of its subtrees is non-empty. If after the swap the node to be deleted is not a leaf node, then we push it further down the tree with another swap and repeat the process until the node becomes a leaf node.
There are three cases to consider:
Note: remembering the following fact helps understand the three cases below: the smallest value in a BST is the left-most node, while the largest value is the right-most node.
Case 1: If the node being deleted has no right child, then the node's left child can be used as the replacement.
Case 2: If the deleted node's right child has no left child, then the deleted node's right child can replace the deleted node.
Case 3: If the deleted node's right child does have a left child, then the deleted node must be replaced by the left-most descendant of the deleted node's right child.
This deleting procedure is shown graphically below:

Note 1: A binary search tree is a special category of the more general M-way search tree in which each node contains M subtrees and not two subtrees as in BSTs.
Note 2: Other literature may refer to the node values in search trees as keys.
The height of a tree is an important concept when dealing with self-balancing BSTs. The height of a tree is defined as the length of the longest path starting at the root. The height of a tree can be defined recursively as follows:
The height of a leaf node is zero.
The height of a node with one child is the height of the child plus one.
The height of a node with two children is one plus the greater height of the two children.
To compute the height of a tree, start at the leaf nodes and assign then a height of zero. Then move up the tree using the rules above to compute the height of each lead node's parent. Continue like this until each node is labelled. The height of the tree is then the height of the root node. This procedure is illustrated below:
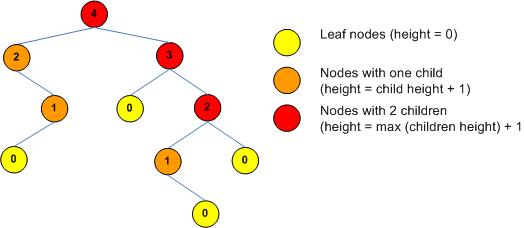
BSTs exhibit the best search time when the tree's height is near the floor of log2n where n is the number of nodes in the tree. Rrecall that logab = y is the same as ay = b. For example log28 = 3 is the same as 23 = 8. Also recall that the floor of a number is the greatest integer less than x. So for 3.14 the floor is 3 and for 5.999, the floor is 5.
For the tree above, n = number of nodes = 10, therefore log2n = log210 = 3.322.Thererfore, the optimal height is 3 and not 4 as shown above. Note that be moving the bottom-most node to another parent, we could reduce the tree's height by 1, thereby giving the optimal height-to-node ratio.
The challenge then is to ensure that the topology of the resulting BST results in a height that is near the floor of log2n where n is the number of nodes in the tree. And as we have seen, the topology of a BST depends on the order in which items were inserted. In most cases, especially with user input, we are unable to dictate the order in which items are inserted. The solution, therefore, is not to try to dictate the insertion order, but to ensure that after each insertion, the BST remains balanced. BSTs that are designed to maintain balance are referred to as self-balancing binary search trees.
There are many self-balancing BSTs such as AVL trees, red-black trees, B-trees, splay trees, etc. Some of these trees are discussed very briefly below:
AVL refers to Andelson Velskii Landis, the names of the inventors of this tree. AVL trees must maintain the following balancing property: for every node n, the height of n's left and right subtrees can differ by at most 1. If a node has only one child, then the height of the childless sub-tree is -1. This property is illustrated below:
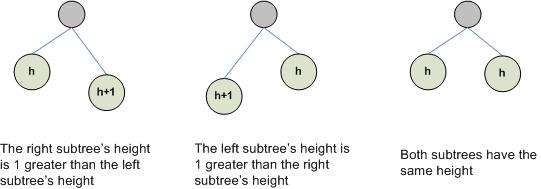
The following two BSTs illustrate a valid and an invalid AVL tree (note that an AVL trees is necessarily a BST, but a BST may not be an AVL tree. In other words, AVL trees must maintain the BST properties)

As nodes are added and deleted, it is vital that the balance property is maintained. AVL trees maintain this balance through rotations. A rotation slightly reshapes the topology of the tree such that the AVL balance property is maintained (and of course, the BST property is maintained).
Inserting a new node into an AVL tree is a two-stage process: First, the node in inserted into the tree using the same algorithm for inserting a node into a BST. After adding the new node, the AVL balance property is likely to have been invalidated along the path travelled down from the root to where the newly node was inserted. To fix these violations, stage two involves traversing back up the access path, checking the height of the left and right subtrees for each node along this return path. If the heights of the subtrees differ by more than one, a rotation is used to fix the anomaly.
Note: At most one rotation need to be performed per insertion, so once a rotation is performed, you can stop traversing the tree.The following figure illustrates:

To familiarize yourself with rotation check out the AVL tree applet at this location.
The following is a one-minute introduction to skip lists. Please refer to documentation in MSDN:
The concept of a skip list is very simple: Consider the skip list below:

A skip list is a linked list made up of a collection of elements. Each element has some data associated with it, a height, and a collection of element references. For example, in the figure above, element C has the data C, a height of 2, and two element references. The head element does not contain any data - it just serves as a starting point whose height should always be equal to the maximum element height in the list.
To search for D, we start at the Head and we begin by following the head element's top link to A. Now we ask, does A come before or after D? D element comes after A so we repeat our searching from A. Now note that at A we repeat our search at the same level following the top-most pointer, bypassing B and C to reach E. Again we ask, does E come before or after D? It is obvious that D comes before E. We have found D.