
.NET Framework types for collections can be divided into the following categories:
Interfaces that define standard collection protocols (IList, ISet, ICollection, etc.)
.NET collection namespaces are as follows:
| Namespace | Collections |
| System.Collections | Non-generic collection classes and interfaces. |
| System.Collections.Specialized | Strongly-types non-generic collection classes. |
| System.Collections.Generic | Generic collection classes and interfaces. |
| System.Collections.ObjectModel | Proxies and bases for custom collections. |
| System.Collections.Concurrent | Thread-safe collections. |
The ability to traverse a collection whether it is a simple collection like an array or a complex one like a dictionary or red/black tree is universal. .NET Framework supports the ability to traverse any collection using a pair of interfaces, IEnumerable and IEnumerator and their generic counterparts.
IEnumerator interface defines the basic low-level protocol to traverse a collection in a forward-only matter. Its declaration is:
public interface IEnumerator { // Summary: Gets the current element in the collection // Returns: The current element in the collection. object Current { get; }
// Summary: Advances the enumerator to the next element of the collection. MoveNext
// must be called before retrieving the first element to allow for an
// empty collection // Returns: true if the enumerator was successfully advanced to the next element;
// false if the enumerator has passed the end of the collection. bool MoveNext();
// Summary: Sets the enumerator to its initial position, which is before the first // element in the collection. void Reset();
}
Note that collections do not implement enumerators, but rather provide enumerators via the IEnumerable interface. IEnumerable interface is the most basic interface that .NET collections implement. Another meaningful name for IEnumerable is IEnumeratorProvider:
public interface IEnumerable { // Summary: Returns an enumerator that iterates through a collection. // Returns: A System.Collections.IEnumerator object that can be used to iterate through // the collection. IEnumerator GetEnumerator();
}
// Shows low-level use of IEnumerable and IEnumerator public void BasicEnumeratorUsage()
{
var data = "Hello";
// Because string implement IEnumerable, we can call GetEnumerator and call its methods IEnumerator enumerator = data.GetEnumerator();
while (enumerator.MoveNext())
{
var c = enumerator.Current;
Trace.WriteLine(c);
}
}
// It is rare to use the logic in BasicEnumeratorUsage method, because C# provides // the foreach keyword. BasicEnumeratorUsage2 provides same functionality as // BasicEnumeratorUsage public void BasicEnumeratorUsage2()
{
var data = "Hello";
foreach (var c in data)
Trace.WriteLine(c);
}
By defining a single method to return an enumerator:
IEnumerable allows Iteration logic to be implemented in a separate class.
IEnumerable allows several consumers to enumerate the collection at once without interfering with each other.
IEnumerator and IEnumerable always implemented by their generic counterparts, IEnumerator<T> and IEnumerable<T>:
public interface IEnumerator<out T> : IDisposable, IEnumerator { // Summary: Gets the element in the collection at the current position of the enumerator. // Returns: The element in the collection at the current position of the enumerator. T Current { get; }
}
public interface IEnumerable<out T> : IEnumerable { // Summary: Returns an enumerator that iterates through the collection. // Returns: A System.Collections.Generic.IEnumerator<T> that can be used to iterate through
// the collection. IEnumerator<T> GetEnumerator();
}
By defining a types version of Current and GetEnumerator, these interfaces support type safety and avoid the overhead of boxing with value-types. Note that arrays automatically implement IEnumerable<T> where T is member type of the array.
It is standard practice for collection classes to publicly expose IEnumerbale<T> while hiding the non-generic IEnumerable through explicit interface implementation. So if you call GetEmumerator directly you get the type-safe generic IEnumerator<T>. However, note that calling GetEnumerator on an array returns the non-generic IEnumerator. This is to keep backwards compatibility when generics where not available:
public void BasicEnumeratorUsage3()
{
// Generic collections publicly expose IEnumerable<T> List<int> numbers = new List<int> {1, 2, 3};
IEnumerator<int> enumerator = numbers.GetEnumerator();
// Arrays publicly expose IEnumerable. So GetEnumerator returns the non-geneic IEnumerator int[] numbers2 = numbers.ToArray();
IEnumerator enumerator2 = numbers2.GetEnumerator();
// To get the generic IEnumerator, use casting required for explicit interface implementations
// NOTE: You rarely need to write this code as you would use foreach instead IEnumerator<int> enumerator3 = ((IEnumerable<int>) numbers2).GetEnumerator();
}
IEnumerator<T> implements IDisposable:
public interface IEnumerator<out T> : IDisposable, IEnumerator
This allows enumerators to hold references to resources such as database connections, and ensure that those resources are released when enumeration is complete. The foreach statement recognizes this details and translates this code
foreach (var item in numbers) { ... }
to,
using (var enumerator = numbers.GetEnumerator())
{
while (enumerator.MoveNext())
{
var element = enumerator.Current;
...
}
} // IDisposable.Dispose() called here
You implement IEnumerable / IEnumerable<T> for one or more of the following reasons:
To support the foreach statement.
To interoperate with any type or method expecting a standard collection.
To support collection initializers
To implement IEnumerable / IEnumerable<T> on a class, you must provide an enumerator. You can do this in three ways:
If the class implementing IEnumerable / IEnumerable<T> wraps a collection, return the collection's enumerator.
Use yield return.
Instantiate a class that derives fro IEnumerator / IEnumerator<T>.
Option 2 uses yield return to create an iterator, a C# language feature to iterate over collections. The iterator automatically handles the implementation of IEnumerable / IEnumerator or their generic versions. Here's a simple example
// A simple class that uses IEnumerable<T> and 'yield return' to implement an interator. // Because IEnumerable<T> implements IEnumerable, we must implement both the generic and // non-generic versions of GetEnumerator. Standard practice is to implement the non-generic // GetEnumerator explicitly, and have it call the generic GetEnumerator class CustomCollection1<T> : IEnumerable<T>
{
public List<T> Data { get; set; }
public CustomCollection1()
{
Data = new List<T>();
}
// With yield return, the compiler writes a hidden nested enumerator class, and then // refactors GetEnumerator to instantiate and return that class public IEnumerator<T> GetEnumerator()
{
foreach (var item in Data)
yield return item;
}
// Eplicit interface implementation. Hidden unless you cast to IEnumerable IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
public void BasicIterator()
{
// Instantiate the custom collection and add data to the underlying collection var collection = new CustomCollection1<int>();
collection.Data.Add(1);
collection.Data.Add(2);
collection.Data.Add(3);
// Now iterate over the custom collection. Note that we are not iterating over // the underlying 'Data' collection foreach (var item in collection)
Trace.WriteLine(item);
}
The final approach is to write a class that implements IEnumerator or IEnumerator<T> directly:
// A simple class that implements an IEnumerator. // Because IEnumerable<T> implements IEnumerable, we must implement both the generic and // non-generic versions of GetEnumerator. Standard practice is to implement the non-generic // GetEnumerator explicitly, and have it call the generic GetEnumerator class CustomCollection2<T> : IEnumerable<T>
{
public List<T> Data { get; set; }
public CustomCollection2()
{
Data = new List<T>();
}
public IEnumerator<T> GetEnumerator()
{
Trace.WriteLine("Generic GetEnumerator");
return new EnumeratorImp<T>(this);
}
// Explicit interface implementation. Hidden unless you cast to IEnumerable IEnumerator IEnumerable.GetEnumerator()
{
Trace.WriteLine("IEnumerable.GetEnumerator");
return GetEnumerator();
}
private class EnumeratorImp<T> : IEnumerator<T>
{
private readonly CustomCollection2<T> collection;
private int currentIndex = -1;
public EnumeratorImp(CustomCollection2<T> coll)
{
Trace.WriteLine("EnumeratorImp ctor");
collection = coll;
}
public T Current
{
get { Trace.WriteLine("Generic Current");
if (currentIndex == -1)
throw new InvalidOperationException("Enumeration not started");
if (currentIndex == collection.Data.Count)
throw new InvalidOperationException("Past end of collection");
return collection.Data[currentIndex];
}
}
object IEnumerator.Current
{
get { Trace.WriteLine("IEnumerator.Current");
return Current;
}
}
public void Dispose()
{
Trace.WriteLine("Dispose");
// Add any necessary clean up code ... } // currentIndex initialized to -1, so first call to MoveNext should move to the first // (and not second) element public bool MoveNext()
{
Trace.WriteLine("MoveNext");
if (currentIndex == collection.Data.Count) return false;
++currentIndex;
return currentIndex < collection.Data.Count;
}
public void Reset()
{
Trace.WriteLine("Reset");
currentIndex = -1;
}
}
}
public void BasicIterator2()
{
// Instantiate the custom collection and add data to the underlying collection var collection = new CustomCollection2<int>();
collection.Data.Add(1);
collection.Data.Add(2);
collection.Data.Add(3);
// Now iterate over the custom collection. Note that we are not iterating over // the underlying 'Data' collection foreach (var item in collection)
Trace.WriteLine(item);
}
Output:
Generic GetEnumerator
EnumeratorImp ctor
MoveNext
Generic Current
1
MoveNext
Generic Current
2
MoveNext
Generic Current
3
MoveNext
Dispose
As a producer of data: Because Enumerable<T> derives from IEnumerable, always implement IEnumerable whenever implementing IEnumerable<T>. However, it's very rate that you would implement these interfaces from scratch. In all cases, you can use the higher-level approach of using iterator methods, Collection<T> and LINQ.
As a consumer of data: You can manage completely with the generic interfaces.
ICollection and IList Interfaces
IEnumerable and IEnumerable<T> are interfaces for forward-only iterations. They do not provide a mechanism to get the size of the collection, access a member by index, search, or modify the collection. Such functionality is provided by both ICollection, IList, and IDictionary interfaces. Each comes with generic and non-generic versions, with the non-generic versions used for legacy applications. The easiest way to summarize these interfaces:
| Interface | Purpose |
| IEnumerable<T> | Minimum functionality (forward-only iteration) |
| ICollection<T> | Medium functionality (Count property) |
| IList<T> | Maximum functionality (random access by index / key ) |
public interface IEnumerable<out T> : IEnumerable public interface ICollection<T> : IEnumerable<T>, IEnumerable public interface IList<T> : ICollection<T>, IEnumerable<T>, IEnumerable
Note the following:
It is rare that you will need to implement any of these interfaces. When you need to write a collection class, you should subclass Collection<T>, or use LINQ which covers many scenarios.
For historical reasons, ICollection<T> does not derive from ICollection, IList<T> does not derive from IList, and IDictionary<TKey, TValue> does not derive from IDictionary. A collection class however, can implement both generic and non-generic versions of an interface if beneficial.
ICollection<T> is the standard interface for countable collections of objects. Its main features are:
Ability to determine the size of a collection (Count).
Ability to determine if an item exists in the collection (Contains).
Copy the collection to an array (ToArray).
Determine whether the collection is read only (IsReadOnly).
For writable collections, the ability to add, remove, and clear items from the collection (Add, Remove, Clear)
Ability to traverse via the foreach statement.
public interface ICollection<T> : IEnumerable<T>, IEnumerable {- int Count { get; }
bool IsReadOnly { get; }
void Add(T item);
void Clear();
bool Contains(T item);
void CopyTo(T[] array, int arrayIndex);
bool Remove(T item);
}
ICollection is similar to ICollection<T> in providing a countable collection but has only Count and CopyTo methods, in addition to synchronization methods that were dumped in the generic version because thread safety is no longer considered intrinsic to the colleciton. Both interfaces are easy to implement. If implementing a read-only collection, the Add, Remove, and Clear methods should throw a NotSupportedException.
IList<T> is the standard interface for collections indexable by position. In addition to the functionality inherited from ICollection<T> and IEnumerable<T>, it provides the ability to read/write/insert/remove an element by position:
public interface IList<T> : ICollection<T>, IEnumerable<T>, IEnumerable { T this[int index] { get; set; }
int IndexOf(T item); // Performs a linear search on the list void Insert(int index, T item);
void RemoveAt(int index);
}
List<T> implements both IList<T> and IList. C# arrays also implement both IList<T> and IList, although methods to add/remove are hidden via explicit interface and throw NotSupportedException if called.
Class Array is the implicit base class for all single and multi-dimensional arrays. When an array is declared using C# syntax, i.e., int[] aData = new[] , the CLR implicitly subtypes the Array class and creates an appropriate pseudotype appropriate to the array's dimensions and element types. The pseudotype also implements the typed generic collection interfaces such as IList<int>. The CLR also treats array types specially, assigning them a contiguous memory space, making them very efficient for indexing, but prevents them from being resized.
Note that the Array class implements collection interfaces:
public abstract class Array : ICloneable, IList, ICollection, IEnumerable, IStructuralComparable,
IStructuralEquatable
However, IList is implemented explicitly to keep Array's public interface clean of methods such as Add or Remove which throw an exception on fixed-length collections such as arrays. The Array class has a static Resize method which works by creating a new array and then copying each element. Array.Resize is inefficient, and references to the array elsewhere in the program will still point to the original version. A better solution is to use the List class.
An array can contain value type or reference type elements. Value type elements are stored in place in the array. So an array of 10 long integers (each 8 bytes) will occupy 80 bytes of contiguous memory. A reference type element occupies the space required for an address (4 bytes = 32 bits on 31-bit systems, or 8 bytes = 64 bits on 64-bit systems). The following shows how arrays for value types and reference types affect memory:
public void ArrayMemory()
{
StringBuilder[] builders = new StringBuilder[5];
builders[0] = new StringBuilder("builder1");
builders[1] = new StringBuilder("builder2");
builders[2] = new StringBuilder("builder3");
long[] numbers = new long[3];
numbers[0] = 12345;
numbers[1] = 54321;
}
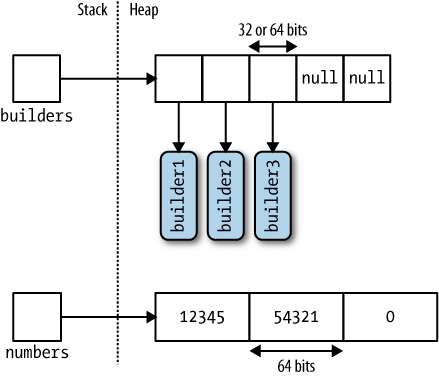
Note that Array is reference type. This means that arrayA = arrayB results in two variables that reference the same array. Similarly, two distinct arrays will always fail on equality test, because they point to two different memory location.
public void ArrayEquality()
{
int[] a1 = new[] {1, 2, 3, 4, 5};
int[] a2 = new[] {1, 2, 3, 4, 5};
var equal1 = a1 == a2; // equal1 = false var equal2 = a1.Equals(a2); // equal2 = false var equal3 = ReferenceEquals(a1, a2); // equal3 = false }
Arrays can be duplicated with the Clone method: arrayB = arrayA.Clone(). This results in a shallow clone meaning that only the memory of the array is copied. If the array contains value types, the values are copied, and if the array contains reference types, just the references are copied resulting in two arrays whose members reference the same objects. The following demonstrates the effect of cloning an array whose members are reference types:
public void ArrayCloning()
{
StringBuilder[] builders = new StringBuilder[5];
builders[0] = new StringBuilder("builder1");
builders[1] = new StringBuilder("builder2");
builders[2] = new StringBuilder("builder3");
StringBuilder[] builders2 = builders;
StringBuilder[] shallowClone = builders.Clone() as StringBuilder[];
}
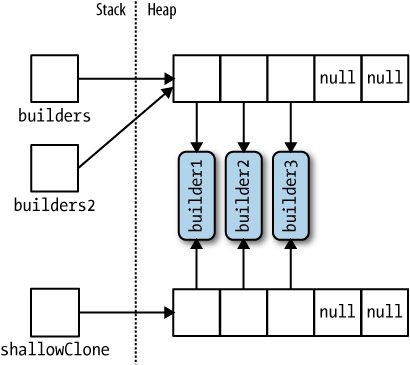
To create a deep copy where reference types elements are duplicated, you must loop through the array and clone each element manually. The same rule applies to other collection types. Array class is designed for use with 32-bit indexers and has limited support for 64-bit systems. However, the CLR does not permit any object including arrays to exceed 2GB in size whether it's running on 32-bit or 64-bit systems.
The easiest way to create an array is through C# language constructs []. You can also instantiate an array by calling Array.CreateInstance which allows you to specify type, rank (number of dimensions), and lower bound (non-zero based array):
public void ArrayCreation()
{
{
// Easiest way to create arrays int[] aNumbers = { 1, 2, 3, 4 };
var first = aNumbers[0]; // 1 var last = aNumbers[aNumbers.Length - 1]; // 4 } { // Create an array dynamically var aNumbers2 = Array.CreateInstance(typeof (int), 4);
aNumbers2.SetValue(1, 0);
aNumbers2.SetValue(2, 1);
aNumbers2.SetValue(3, 2);
aNumbers2.SetValue(4, 3);
var first = aNumbers2.GetValue(0); // 1 var last = aNumbers2.GetValue(aNumbers2.Length - 1); // 4 var lb = aNumbers2.GetLowerBound(0); // 0 var up = aNumbers2.GetUpperBound(0); // 3 } }
When an array is instantiated using either [] syntax or CreateInstance, the elements are automatically initialized to null for reference type elements and to zeros for value types (by calling the default constructor of the value type). The Array class also provides this functionality via the Clear method. Note that Array.Clear does not affect array size, unlike ICollection<T>.Clear where the collection is reduced to zero elements.
Arrays are easily enumerated with foreach and Array.ForEach<T>:
public void ArrayEnumeration()
{
int[] aNumbers = new[] {1, 2, 3, 4};
// Enumerating through foreach foreach (var number in aNumbers)
Trace.WriteLine(number);
// Enumerating through Array.ForEach<T> Array.ForEach( aNumbers, number => Trace.WriteLine(number));
}
Array class provides a range of methods for finding elements within a one-dimensional array (methods in bold use a predicate - a predicate is a delegate accepting an object and returning a bool)
BinarySearch
IndexOf
LastIndexOf
Find
FindLast
Exits
TrueForAll
FindIndex
FindLastIndex
Array has the following built-in sorting methods in addition to other overloads:
public static void Sort<T>(T[] array);
public static void Sort<TKey, TValue>(TKey[] keys, TValue[] values);
Array.Sort requires that array elements implement IComparable (note that most primitive types such as integers, doubles, etc. implement IComparable). Otherwise, you must provide Sort with a custom comparison provider which is either an IComarer<T> instance or a Comparison delegate. The Comparison delegate follows same semantics as IComparer<T>.CompareTo:
Negative: x comes before y.
0: x and y have the same sorting position.
Positive: x comes after y.
public void ArraySorting()
{
int[] numbers = {55, 220, 1, 4}; // numbers: 1, 4, 55, 220 Array.Sort(numbers);
// Array.Sort() accepting a pair of arays work by sorting the items in array 1 // and re-arranging array 2 in tandem. In the example below, both array have // the same length and it is assumed that 3 is associated with C, 1 with A and // 2 with B int[] numbers2 = {3, 1, 2};
string[] values = {"C", "A", "B"}; // numbers2: 1, 2, 3. Values: A, B, C Array.Sort(numbers2, values);
// The following sorts an array of integers so that odd numbers come first int[] numbers3 = {6, 1, 2, 5, 3, 4};
Array.Sort(numbers3, (x, y) => x % 2 == y % 2 ? 0 : x % 2 == 1? -1 : 1);
}
As an alternative to calling Array.Sort, you can use OrderBy and ThenBy LINQ operators. Unlike Array.Sort, LINQ operators do not alter the input collection.
| Method | Description |
| Array.Clone | Return a shallow-copied array. |
| Array.Copy | Copy a contiguous subset of the array. |
| Array.ConstrainedCopy | Copy a contiguous subset of the array if all requested elements can be copied. On an error, the operation is rolled back. |
| Array.AsReadOnly | Return a wrapper that prevents elements from being re-assigned. |
| Array.ConvertAll<TInput, TOutpuy> | Creates and returns a new array of elements of type TOutput. |
| Array.Resize | Create a new array and copy over the elements. |
This section discusses on list-like collections (as opposed to dictionary-like collections). Always favour the generic versions over their non-generic versions.
List<T> class implements both IList and IList<T> provide a dynamically-sized array of objects. Unlike with arrays, all interfaces are implemented publicly:
[Serializable]
public class List<T> : IList<T>, ICollection<T>, IEnumerable<T>,
IList, ICollection, IEnumerable { ... }
Note the following:
Internally, List<T> works by maintaining an internal array that gets replaced with a larger one upon reaching capacity.
Appending elements is efficient as there is always a free slot at the end,
Inserting an element is slow as all elements after the insertion point must be shifted to make a free slot.
Searching if efficient if the BinarySearch method is used on a sorted list, otherwise searching is inefficient as each item must be checked individually.
LinkedList<T> is a generic doubly-linked list where each node references the node before, the node after, and the actual element:
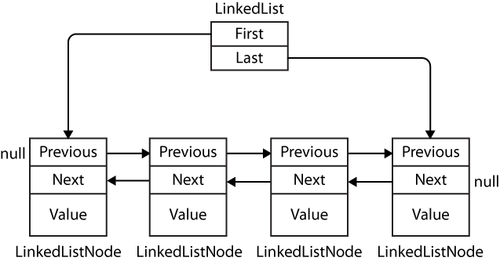
LinkedList<T> implements ICollection<T> and IEnumerable<T> and their non-generic versions, but not IList<T> since access by index is not supported:
[Serializable]
public class LinkedList<T> : ICollection<T>, IEnumerable<T>, ICollection, IEnumerable,
ISerializable, IDeserializationCallback { ... }
List nodes are implemented using LinkedListNode<T> class:
public sealed class LinkedListNode<T>
{
internal LinkedList<T> list;
internal LinkedListNode<T> next;
internal LinkedListNode<T> prev;
internal T item;
...
}
The main benefit is that an element can always be inserted efficiently anywhere in the list, since insertion involves creating a new node and updating a few references. However, finding where to insert the node in the first place can be slow as each node must be traversed. When adding a node, you can specify its position either relative to another node or at the start/end of the list. Similar methods are provided for removing elements, as well as methods to keep track of count, get head and tail of the list, search, etc.
AddFirst
AddLast
AddAfter
AddBefore
RemoveFirst
RemoveLast
Count
First
Last
Contains
Find
etc.
Queue<T> is a FIFO - First In First Out - data structure. Queue<T> is implemented internally using an array that is resized as required, just like List<T>. Queues are enumerable but they do not implement IList<T> interface since members cannot be accessed directly by index. As usual, a ToArray method is provided to copy elements to an array where they can be randomly accessed:
[Serializable]
public class Queue<T> : IEnumerable<T>, ICollection, IEnumerable { ... }
. Note that enqueuing and dequeuing operations are extremely fast.
Stack<T> is a LIFO - Last In First Out - data structure. Stack<T> is implemented internally using an array that is resized as required, just like List<T>. Stacks are enumerable but they do not implement IList<T> interface since members cannot be accessed directly by index. As usual, a ToArray method is provided to copy elements to an array where they can be randomly accessed:
public class Stack<T> : IEnumerable<T>, ICollection, IEnumerable { ... }
A BitArray is a dynamically sized collection of compacted bool values. It is more memory-efficient than both a simple array of bool and List<bool> because it uses only one bit for each value, unlike type bool which takes up a byte for each value.
public sealed class BitArray : ICollection, IEnumerable, ICloneable { ... }
public void BitArray()
{
var bitArray1 = new BitArray(2);
bitArray1[0] = true;
bitArray1[1] = true;
var bitArray2 = new BitArray(2);
bitArray2[0] = true;
bitArray2[1] = false;
var orResult = bitArray1.Or(bitArray2); // orResult[0]: true, orResult[1]: true }
Recall that a set is a collection of unique and unordered elements. This means that a set does not allows duplicates and set elements cannot be accessed by index. HashSet<T> and SortedSet<T> both have the following important features:
Their Contains method executes very quickly using a hash-based lookup.
They do not store duplicate elements and silently ignore requests to add duplicates.
Elements cannot be accessed by position.
HashSet<T> and SortedSet<T> both implement ISet<T>. HashSet<T> is implemented using a hashtable that stores just keys, while SortedSet<T> is implemented with a red/black tree:
public class HashSet<T> : ISerializable, IDeserializationCallback, ISet<T>,
ICollection<T>, IEnumerable<T>, IEnumerable { ... }
public class SortedSet<T> : ISet<T>, ICollection<T>, IEnumerable<T>, ICollection, IEnumerable,
ISerializable, IDeserializationCallback { ... }
SortedSet<T> offers the same set of members as HashSet<T>, plus the following:
GetViewBetween
Reverse
Min
Max
A dictionary is a collection in which each element is a key/value pair. Dictionaries are used for lookups and sorted lists. IDictionary<TKey,TValue> interface defines a standard protocol for dictionaries, and is implemented by a set of general-purpose dictionary classes. The classes differ in the following regard:
Whether or not items are sorted.
Whether or not items can be accessed by position (index) as well as by key.
Whether generic or non-generic.
Performance when large.
The following table summarizes each of the dictionary classes and how they differ. Note that performance times are in milliseconds to perform 50,000 operations on a dictionary with integer keys and values on a 1.5GHz PC. Also note that differences in performance between generic and non-generic counterparts are due to boxing and show up only with value-types):
| Type | Internal structure | Retrieve by index? | Memory (avg bytes/item) |
Speed (random insertion) | Speed (sequential insertion) | Speed (retrieval by key) | retrieval time (Big-O) |
|
UNSORTED |
|||||||
| Dictionary<K,V> | Hashtable | No | 22 | 30 | 30 | 20 | O(1) |
| Hashtable | Hashtable | No | 38 | 50 | 50 | 30 | O(1) |
|
ListDictionary |
Linked list | No | 36 | 50,000 | 50,000 | 50,000 | O(n) |
| OrderedDictionary | Hashtable + array | Yes | 59 | 70 | 70 | 40 | O(1) |
|
SORTED |
|||||||
| SortedDictionary<K,V> | Red/black table | No | 20 | 130 | 100 | 120 | O(log n) |
| SortedList<K,V> | 2 x Array | Yes | 2 | 3,300 | 30 | 40 | O(log n) |
| SortedList | 2 x Array | Yes | 27 | 4,500 | 100 | 180 | O(log n) |
IDicionary<TKey,TValue> defines the standard protocol for all key/value-based collections. It extends ICollection<T> by adding methods and properties to access elements based on a key of arbitrary type:
public interface IDictionary<TKey, TValue> : ICollection<KeyValuePair<TKey, TValue>>,
IEnumerable<KeyValuePair<TKey, TValue>>, IEnumerable { TValue this[TKey key] { get; set; }
ICollection<TKey> Keys { get; }
ICollection<TValue> Values { get; }
bool ContainsKey(TKey key);
void Add(TKey key, TValue value);
bool Remove(TKey key);
bool TryGetValue(TKey key, out TValue value);
}
Dictionary<Tkey,TValue> implements IDictionary<Tkey,TValue>. It uses a hashtable to store keys and value and is fast and efficient:
public class Dictionary<TKey, TValue> : IDictionary<TKey, TValue>,
ICollection<KeyValuePair<TKey, TValue>>,
IEnumerable<KeyValuePair<TKey, TValue>>, IDictionary, ICollection, IEnumerable, ISerializable,
IDeserializationCallback { ... }
Dictionary<Tkey,TValue> implements both the generic and non-generic IDictionary with the generic IDictionary being exposed publicly. Note the following patterns for using dictionaries:
public void TestDictionary()
{
IDictionary<string, int> wordToNumber = new Dictionary<string, int>();
// Adding using Add wordToNumber.Add("one", 1); // Adds key and value as key does not exist wordToNumber.Add("one", 1); // Calling Add more than once with the same key throws an exception // An item with the same key has already been added. // Adding using indexer wordToNumber["two"] = 20; // Adds key and value as key does not exist wordToNumber["two"] = 2; // Updates the value of the key // Not recommended for retrieving a value: using the indexer int number1 = wordToNumber["one"];
int number2 = wordToNumber["three"]; // Key does not exist. Throws an exception. // The given key was not present in the dictionary.
// Recommended for retrieving a value: using TryGetValue if (wordToNumber.TryGetValue("one", out number1))
Trace.WriteLine(string.Format("Found value {0} for key 'one", number1));
else Trace.WriteLine("Did not find a value for key 'one");
// Three ways to enumerate a dictionary foreach (var kvp in wordToNumber)
Trace.WriteLine(string.Format("Key: {0}, Value: {1}", kvp.Key, kvp.Value));
foreach (var key in wordToNumber.Keys) Trace.WriteLine( key);
foreach (var value in wordToNumber.Values) Trace.WriteLine(value);
}
Dictionary uses a hashtable by converting each element's key into a hash code (an integer) which could be anywhere from 0 to Int32.MaxValue (or Int64.MaxValue on 64-bit machines). A hash code is meant to be an index to an array however it is not possible to allocate an array that takes up the system memory. The solution is to use buckets: An algorithm converts a hash code into a hash key which is then used to determine which bucket an entry belongs to. If the bucket contains more than one value, a linear search is performed on the bucket. A hashtable typically starts out maintaining a 1:1 ratio of buckets to values (a 1:1 load factor), meaning each bucket contains only 1 value. However, as more items are added to the hashtable, the load factor increases in a manner designed to optimize insertion, retrieval, and memory performance. And as with many other collections, performance can be slightly improved by specifying the collection's expected size in the constructor to avoid internal resizing operations.
A dictionary can work with keys of any type , providing it is able to determine equality among keys and obtain hash codes from those keys. By default, equality is determined via the key's object.Equals method and the has code is obtained via the key's GetHashCode method. This behaviour, especially for reference types, must be changed by overriding these methods or by providing an IEqualityComparer object. For example, strings are often used as keys and you can specify an IEqualityComparer for strings as follows:
var stringToInt = new Dictionary<string, int>(StringComparer.InvariantCultureIgnoreCase);
Some of the downsides of using a Dictionary<TKey,TValue>:
Items are not sorted. For example, given a Dictionary<int, stirng>, you cannot sort keys (integers) in ascending or descending. If you want to maintain sorting, use the-generic SortedDictionary<TKey,TValue> or SortedList<TKey,TValue>.
Items are not ordered, i.e., items cannot be accessed by index (the original order in which items were added is not maintained). If you want to maintain order, use the non-generic OrderedDictionary.
Duplicate keys are not allowed.
There are two generic dictionary classes internally structured so that their content is always sorted:
| Collection | Implementation | Notes |
| SortedDictionary<TKey,TValue> | Red/black tree |
|
| SortedList<TKey,TValue> | Ordered array pair |
|
An OrderedDictionary is a non-generic dictionary that maintains items in the order that they were added (i.e., you can access elements by both key and index). Note that an OrderedDictionary is not a sorted dictionary where the keys are sorted in some order. An OrderedDictionary uses both an ArrayList and a Hashtable to support item retrieval by index.
ListDictionary uses a single linked list to store underlying data and maintain order (it does not provide sorting). ListDictionary is very slow with large sets and is only efficient with a very small lists (say 10 items or less). HybridDictionary is a ListDictionary that automatically converts to a Hashtable when reaching a certain size to address ListDictionary performance problems. However, given the overhead of converting, you want just as well use a Hashtable.
All the collection classes discussed so far do not allow you to control when happens when an item is added to or removed from the collection. For example, you may need to
fire an even when an item is added and/or removed.
update properties because of the added / removed items.
detect an illegal add/remove operation and throw an exception.
etc.
.NET provides base collection classes for this exact purpose in the System.Collections.ObjectModel namespace. They are effectively wrappers that implement IList<T> or IDictionary<T>.
Collection<T> is a customizable wrapper for List<T>. In addition to implementing IList<T> and IList, it defines four virtual method and a property as follows:
public class Collection<T> : IList<T>, ICollection<T>, IEnumerable<T>, IList, ICollection, IEnumerable { // ... protected IList<T> Items { get; }
protected virtual void ClearItems();
protected virtual void InsertItem(int index, T item);
protected virtual void RemoveItem(int index);
protected virtual void SetItem(int index, T item);
}
The protected Items property allows the implementer to directly access the inner list. The four virtual methods provide the gateway by which you can hook in to change or enhance the list's normal behaviour. The virtual methods need not be overridden; they can be left as as until there's a need to alter the list's default behaviour. CollectionBase is the non-generic version of Collection<T> introduced in .NET 1.0. Favour using Collection<T> instead of CollectionBase.
The following example shows how to use Collection<T>:
public class Department { public readonly EmployeeCollection Employees;
public Department()
{
Employees = new EmployeeCollection(this);
}
}
public class Employee { public string Name { get; private set; }
public int Id { get; private set; }
public Department Department { get; internal set; }
public Employee(string name, int id)
{
Name = name;
Id = id;
}
public override string ToString()
{
return string.Format("{0}/{1}", Name, Id);
}
}
public class EmployeeCollection : Collection<Employee>
{
public Department Department { get; internal set; }
public EmployeeCollection(Department dept)
{
Department = dept;
}
protected override void ClearItems()
{
foreach (var employee in this)
employee.Department = null;
base.ClearItems();
}
protected override void InsertItem(int index, Employee item)
{
base.InsertItem(index, item);
item.Department = Department;
}
protected override void RemoveItem(int index)
{
base[index].Department = null;
base.RemoveItem(index);
}
protected override void SetItem(int index, Employee item)
{
base.SetItem(index, item);
item.Department = Department;
}
}
public void BasicCustomizableCollection()
{
Department dept = new Department();
dept.Employees.Add( new Employee("Employee1", 1));
dept.Employees.Add(new Employee("Employee2", 2));
foreach (var employee in dept.Employees)
{
Trace.WriteLine(employee);
}
}
KeyedCollection<TKey,TValue> subclasses Collection<T>. It adds the ability to access items by key just like a dictionary, while removing the ability to specify an existing list in construction.
public class Collection<T> : IList<T>, ICollection<T>, IEnumerable<T>,
IList, ICollection, IEnumerable { ... }
public abstract class KeyedCollection<TKey, TItem> : Collection<TItem> { ... }
Note that KeyedCollection<,> does not implement IDictionary and does not support the concept of key/value pair. Keys are obtained instead from the items themselves via the abstract GetKeyForItem method. Think of KeyedCollection<,> as a Collection<T> plus fast lookup by key. Enumerating a KeyedCollection<,> instance is just like enumerating an ordinary list. The most common use for KeyedCollection<,> is providing a collection of items accessible by both index and by name. Finally, DictionaryBase is the non-generic version of KeyedCollection<,> introduced in .NET 1.0. Favour using KeyedCollection<,> instead of DictionaryBase.
ReadOnlyCollection<T> is a wrapper that provides a read-only view of a collection. ReadOnlyCollection<T> accepts the input collection in its constructor; it does not take a snapshot of the input collection, so subsequent changes to the input collection are visible via the read-only wrapper:
class MyReadOnlyCollection { private readonly List<string> internalList;
public ReadOnlyCollection<string> Names { get; private set; }
public MyReadOnlyCollection()
{
// Create and intialize internal list, from a db for example internalList = new List<string>();
// Note that the ReadOnlyCollection is initialized wiht internalList. Any changes to // internalList will be reflected in the ReadOnlyCollection. Names = new ReadOnlyCollection<string>(internalList);
}
// A simple method to simulate populating internalList with different data depending // on the date public void ReadFromDB(DateTime dt)
{
internalList.Clear();
if (dt.Date == DateTime.Now.Date)
{
internalList.Add("Name1");
internalList.Add("Name2");
internalList.Add("Name3");
}
else { internalList.Add("LastName1");
internalList.Add("LastName2");
internalList.Add("LastName3");
}
}
}
public void ReadOnly()
{
var readOnly = new MyReadOnlyCollection();
// Read only collection is initially empty Debug.Assert(readOnly.Names.Count == 0);
// Populate the internal list with data. Note how the contents of the read only collection // have now changed to reflect new contents of the internal list readOnly.ReadFromDB(DateTime.Now.Date);
// Enumerate read only collection foreach (var name in readOnly.Names)
Trace.WriteLine(name);
// Repopulate the internal list with different data. Note how the contents of the // read only collection have now changed to reflect new contents of the internal list readOnly.ReadFromDB(DateTime.Now.AddDays(1));
// Enumerate read only collection foreach (var name in readOnly.Names)
Trace.WriteLine(name);
}
Name1 Name2 Name3 LastName1 LastName2 LastName3
A type that is equatable, hashable, and comparable can function correctly in a dictionary or sorted list:
A type returning meaningful results for Equals and GetHashCode can be used as a key in a dictionary.
A type that implements IComparable / IComparable<T> can be used as a key in any of the sorted dictionaries or lists.
However, sometimes you want to:
Switch to alternative equating or comparison behaviour.
Use a dictionary or a sorted collection with a key type that is not intrinsically equatable or comparable.
To achieve these two points, .NET provides IEqualityComparer<T> and IComparable<T>:
IEqualityComparer<T>: Performs plug-in equality comparison and sorting. and is recognized by Dictionary<TKey,TValue>.
IComparable<T>: Performs plug-in order comparison and is recognized by the sorted dictionaries and collections, and Array.Sort.
An equality comparer allows you to plug in non-default equality and hashing behaviour, primarily for Dictionary<,> and the historic Hashtable classes. An equality comparer implements IEqualityCompare<T>:
public interface IEqualityComparer<in T>
{
bool Equals(T x, T y);
int GetHashCode(T obj);
}
To write a custom comparer, you implement IEqualityComparer<T>, however an alternative is to subclass the abstract EqualityComparer class defined as follows:
public abstract class EqualityComparer<T> : IEqualityComparer, IEqualityComparer<T>
{
public static EqualityComparer<T> Default { ... }
// IEqualityComparer<T>
public abstract bool Equals(T x, T y);
public abstract int GetHashCode(T obj);
// IEqualityComparer (explicitly implemented) int IEqualityComparer.GetHashCode(object obj) { ... }
bool IEqualityComparer.Equals(object x, object y) { ... }
}
EqualityComparer implements both IEqualityComparer<T> and IEqualityComparer interfaces. Your job is simply to override the two abstract methods Equals and GetHashCode exactly as you would implement IEquatable<T>.Equals and object.GetHashCode. The following example illustrates:
public class Customer { public string FirstName { get; private set; }
public string LastName { get; private set; }
public Customer(string first, string last)
{
FirstName = first;
LastName = last;
}
}
public class CustomerEqualityComparere : EqualityComparer<Customer>
{
public override bool Equals(Customer x, Customer y)
{
return x.LastName == y.LastName && x.FirstName == y.FirstName;
}
public override int GetHashCode(Customer obj)
{
return obj.FirstName.GetHashCode() ^ obj.LastName.GetHashCode();
}
}
public void TestEqualityComparer()
{
// Create two different customers but with the same name var customer1 = new Customer("Joe", "Bloggs");
var customer2 = new Customer("Joe", "Bloggs");
// Since we have not implemented IEquatable<Customer> or overridden object.Equals, // normal reference equality applies var bEqual1 = customer1.Equals(customer2); // bEqual1 = false var bEqual2 = customer1 == customer2; // bEqual2 = false // Since we have not implemented IEquatable<Customer> or overridden object.Equals, // normal reference equality also applies when using these two customer instances // in a dictionary int nValue;
bool bFound;
Dictionary<Customer, int> customerToAmount = new Dictionary<Customer, int>();
customerToAmount.Add(customer1, 100); // OK customerToAmount.Add(customer2, 200); // OK bFound = customerToAmount.ContainsKey(customer1); // bFound = true bFound = customerToAmount.ContainsKey(customer2); // bFound = true bFound = customerToAmount.TryGetValue(customer1, out nValue); // true. nValue = 100 bFound = customerToAmount.TryGetValue(customer2, out nValue); // true. nValue = 200 // Now use CustomerEqualityComparer customerToAmount = new Dictionary<Customer, int>(new CustomerEqualityComparer());
customerToAmount.Add(customer1, 100); // OK customerToAmount.Add(customer2, 200); // ArgumentException:
//An item with the same key has already been added. bFound = customerToAmount.ContainsKey(customer1); // bFound = true bFound = customerToAmount.ContainsKey(customer2); // bFound = true bFound = customerToAmount.TryGetValue(customer1, out nValue); // true. nValue = 100 bFound = customerToAmount.TryGetValue(customer1, out nValue); // true. nValue = 100 }
Calling EqualityComparer<T>.Default can be used as an alternative to implementing your own EqualityComparer<T>-derived class. The Default property checks whether type T implements the IEquatable<T> generic interface and if so returns an EqualityComparer<T> that uses that implementation. Otherwise it returns an EqualityComparer<T> that uses the overrides of Object.Equals and Object.GetHashCode provided by T.
public class Customer2 : IEquatable<Customer2>
{
public string FirstName { get; private set; }
public string LastName { get; private set; }
public Customer2(string first, string last)
{
FirstName = first;
LastName = last;
}
// IEquatable<Customer2> public bool Equals(Customer2 other)
{
if (other == null) return false;
if (ReferenceEquals( this, other)) return true;
return LastName == other.LastName && FirstName == other.FirstName;
}
// It is also a good practive to override object.Equals and object.GetHashCode public override bool Equals(object other)
{
return Equals(other as Customer2);
}
public override int GetHashCode()
{
return FirstName.GetHashCode() ^ LastName.GetHashCode();
}
}
public void TestDefaultEqualityComparer()
{
int nValue;
bool bFound;
// Using EqualityComparer<T>.Default Dictionary<Customer2, int> customer2ToAmount = new Dictionary<Customer2, int>(EqualityComparer<Customer2>.Default);
var c1 = new Customer2("Joe", "Bloggs");
var c2 = new Customer2("Joe", "Bloggs");
customer2ToAmount.Add(c1, 12); // OK customer2ToAmount.Add(c2, 34); // ArgumentException: An item with
// the same key has already been added. bFound = customer2ToAmount.ContainsKey(c1); // bFound = true bFound = customer2ToAmount.ContainsKey(c2); // bFound = true bFound = customer2ToAmount.TryGetValue(c1, out nValue); // true. nValue = 12 bFound = customer2ToAmount.TryGetValue(c2, out nValue); // true. nValue = 12
}
Recall that IComparable<T> defines a generalized comparison method that a type implements to create a type-specific comparison method for ordering instances. On the other hand, IComparer<T> is used to plug in custom ordering logic for sorted dictionaries and collections:
public interface IComparer { int Compare(object x, object y);
}
public interface IComparer<in T>
{
int Compare(T x, T y);
}
Note that a comparer (class that implements IComparer<T>) is useless to unsorted Dictionary<T> since Dictionary<T> required an IEqualityComparer<T> instance. Similarly, an IEqualityComparer<T> is useless for sorted dictionaries and collections since they require an IComparer<T> instance.
As with equality comparers, there is an abstract class you can subtype instead of implementing IComparer and IComparer<T>:
public abstract class Comparer<T> : IComparer, IComparer<T>
{
public static Comparer<T> Default { get { ... } }
public abstract int Compare(T x, T y);
int IComparer.Compare(object x, object y) { ... }
}
Derive from this class to provide a custom implementation of the IComparer<T> interface for use with collection classes such as the SortedList<TKey, TValue> and SortedDictionary<TKey, TValue> generic classes. It is recommended to derive from Comparer<T> instead of implementing IComparer<T> since Comparer<T> also implements IComparer by delegating to your overridden implementation of the abstract Compare.
The difference between deriving from the Comparer<T> class and implementing the System.IComparable interface is as follows:
To specify how two objects should be compared by default, implement the System.IComparable interface in your class. This ensures that sort operations will use the default comparison code that you provided.
To define a comparer to use instead of the default comparer, derive from the Comparer<T> class. You can then use this comparer in sort operations that take a comparer as a parameter.
Note that the Comparer<T>.Default expects that type T implements IComparable<T>. If not, Comparer<T>.Default then expects that type T implements IComparable. If not, an exception is thrown when you attempt to use the comparer returned by Comparer<T>.Default.
The following example shows how to use Comparer<T>:
class Person { public int ID { get; private set; }
public string Name { get; private set; }
public Person(int id, string name)
{
ID = id;
Name = name;
}
public override string ToString()
{
return string.Format("{0} / {1}", ID, Name);
}
}
class PersonComparer : Comparer<Person>
{
public override int Compare(Person x, Person y)
{
if ((x == null) && (y == null))
return 0;
if ((x == null) && (y != null))
return -1;
if ((x != null) && (y == null))
return 1;
// x and y both not null return x.ID.CompareTo(y.ID);
}
}
public void TestComparer()
{
List<Person> persons = new List<Person>()
{
new Person(4, "Person1"),
new Person(2, "Person2"),
null,
new Person(3, "Person3"),
new Person(1, "Person1"),
};
persons.Sort( new PersonComparer());
persons.ForEach( person => Trace.WriteLine((person == null)? "Null" : person.ToString()));
// Comparer<T>.Default expects that type T implements IComparable<T>. If not, // Comparer<T>.Default then expects that type T implements IComparable. If not, // an exception is thrown when you attempt to use the comparer returned by //Comparer<T>.Default. try { Comparer<Person> comparer = Comparer<Person>.Default;
persons.Sort(comparer);
}
catch (Exception ex)
{
Trace.WriteLine(string.Format( "Failed to sort with Comparer<Person>.Default: {0}", ex.Message));
}
}
Null
1 / Person1
2 / Person2
3 / Person3
4 / Person1
Failed to sort with Comparer<Person>.Default: Failed to compare two elements in
the array.
StringComparer is a pre-defined plug-in class for equating and comparing strings, allowing you to specify language and case-sensitivity. StringComparer implements both IEqualityComparer and IComparer, so it can be used with any type of dictionary or sorted list:
public abstract class StringComparer : IComparer, IComparer<string>,
IEqualityComparer, IEqualityComparer<string> {...}
Because StringComparer is abstract, you obtain instances via its static methods and properties:
public void TestStringComparer()
{
try { var namesToIds = new Dictionary<string, int>(StringComparer.OrdinalIgnoreCase);
namesToIds.Add("Joe", 1);
namesToIds.Add("JOE", 1); // Exception: An item with the same key has already been added } catch (Exception ex)
{
Trace.WriteLine(ex.Message);
}
}
Structs implement structural comparison by default: two structs are equal if all their fields are equal. Sometimes, structural equality and order comparison is useful as plug-in options on other types such as arrays and tuples. There are two interfaces to help with this:
public interface IStructuralEquatable { // Determines whether an object is structurally equal to the current instance> bool Equals(object other, IEqualityComparer comparer);
// Returns a hash code for the current instance int GetHashCode(IEqualityComparer comparer);
}
public interface IStructuralComparable { // Determines whether the current collection object precedes, occurs in the same
// position as, or follows another object in the sort order int CompareTo(object other, IComparer comparer);
}
The IEqualityComparer / IComparer that you pass in are applied to each individual element in the composite object.
public void TestStructural()
{
var t1 = Tuple.Create(12.3, "Value1");
var t2 = Tuple.Create(12.3, "Value1");
// Call default Equals method. var bEqual = t1.Equals(t2); // true // Call IStructuralEquatable.Equals using default comparer. IStructuralEquatable equ = t1;
bEqual = equ.Equals(t2, EqualityComparer<object>.Default); // true // Call IStructuralEquatable.Equals using StructuralComparisons.StructuralEqualityComparer. bEqual = equ.Equals(t2, StructuralComparisons.StructuralEqualityComparer); // true }
Using generic collections instead of non-generic collections is highly recommended because you gain the immediate benefit of type safety and performance. For example, List<T> is the generic equivalent of ArrayList. List<int> is immediately type-safe as the list will only accept integers (it is a compile-time error to add non-int values to List<int>). On the other hand, ArrayList accepts object instances and this means that you can add an int, a string, and a double to the same list. In addition, generic collections perform better than their non-generic counterparts when the collection elements are value-types, because with generic there is no need to box the elements.
Consider the following generic types and their non-generic equivalents:
List<T> and ArrayList..
Dictionary<T> and Hashtable.
Collection<T> and CollectionBase.
ReadOnlyCollection<T> and ReadOnlyCollection.
Queue<T> and Queue.
Stack<T> and Stack.
SortedList<T> and SortedList.
LinkedList<T> (has no non-generic equivalent)
SortedDictionary<T> (has no non-generic equivalent)
KeyedCollection<T> (has no non-generic equivalent)
These collections vary in terms how elements are stored, sorted, searched, and compared. For example:
Queue and Queue<T> provide a First-In First-Out (FIFO) list.
Stack and Stack<T> provide a Last-In First-Out (LIFO) list.
SortedList and SortedList<T> provide sorted versions of Hashtable and Dictionary<T>, respectively.
Elements of Hashtable and Dictionary<T> are accessible by key only, but the elements of SortedList and SortedList<T> are accessible by key or index.
Indexes in all collections are zero-based, except for Array which allows you to set the lower bound of the array
Note that some of the generic collections have functionality not found in their non-generic counterparts. For example, List<T> which is the generic equivalent of ArrayList has a few methods that accept generic delegates, such as the Action delegate that represents a visitor that can be act on each element of the list, the Predicate delegate that allows you to specify methods for searching the list, and the Converter delegate that allows you to specify conversions between types.
One of the main difficulties with concurrent programming is mutable shared state. Typically, mutable shared state must be locked before it can be updated. Read-only collections such as ReadOnlyCollection<T>, IReadOnlyList<T> and IEnumerable<T> are facades over collections that can change. Also these types don't offer events to notify you when their contents change, worse still, changes to the underlying collection might occur on a different thread while enumerating the collection.
An alternative to locking or using read-only collections is making use of immutable collections. You can store all types of data in these collections. The only immutable aspect is the collections themselves, not the items they contain. Immutable data structures are guaranteed to never change and can be passed freely between threads. Immutable collection never allow mutations, but offer mutating methods that return new collections, while sharing data across versions very efficiently. Use immutable collections if you need:
System.Collections.Immutable namespace includes the following collections:
Note that all these immutable collections inherit form IReadOnlyCollection<T>. Use the new .NET 4.5 readonly interfaces on all your public APIs, such as IReadOnlyCollection<T> and IReadOnlyList<T>. In your implementation you may use immutable collections, which implement these interfaces. If in the end you need to switch to mutable collections, you’ll be able to do so without any breaking changes.
This is how to create an empty immutable list
// Creating an empty immutable list
ImmutableList<string> emptyList = ImmutableList<string>.Empty
Note the use of the static Empty property similar to string.Empty property. A new ImmutableList<T> is by definition empty because every time we use a constructor to cerate an ImmutableList<T> we will create an empty object. So instead of wasting memory to create multiple objects that are always empty. we use the static Empty property to return an empty list singleton which all code in the application can share.
Because immutable collections can never change, any methods that would mutate the collection always return a new immutable collection. For example, adding an item to emptyList would return a new immutable list:
ImmutableList<string> listWithItem = emptyList.Add("Item1");
Debug.Assert(emptyList.Count == 0);
Debug.Assert(listWithItem.Count == 1);
Similar to the string class, mutating methods always return new strings that include the requested change. Now consider this:
ImmutableList<string> items = emptyList.Add("Item1");
items = items.Add("item2");
items = items.Add("item3");
items = items.Add("item4");
Debug.Assert(items.Count == 4
You do now want to come up with unique names for each assignment, so you can simply re-assign to the same variables. In each of the first four lines in the code above, we replace the reference stored in items with a new one. This means that you should always assign the result of mutating an immutable list to some variable:
ImmutableList<string> items = emptyList.Add("Item1");
items = items.Add("item2");
items = items.Add("item3");
items = items.Add("item4");
items.Add("item5"); // Result not assigned. items is not changed
items.Add("item6"); // Result not assigned. items is not changed
Debug.Assert(items.Count == 4);
To avoid creating so many intermediate objects you can use the ImmutableList<T>.AddRange method. Now consider the following:
ImmutableList<int> bigList = ImmutableList<int>.Empty.AddRange(Enumerable.Range(1, 10000));
ImmutableList<int> bigListPlus1 = bigList.Add(1);
Debug.Assert(bigList.Count == 10000);
Debug.Assert(bigListPlus1.Count == 10001);
The contents of the immutable collections are not copied with each change. This would result in poor performance in bug collections, consume too much memory, and stress the GC. Instead, immutable collections share as much memory between instances as possible. In the example above, the memory used by both bigList and bigListPlus1 collections is just slightly more than for bigList. This is because immutable collections are stored in immutable binary trees instead of flat arrays.
When a list is created based on an existing list, we start with the existing binary tree and change just a few nodes in it, allocating new objects for each changed node and return a list that points to the new root node of the binary tree. So bigList and bigListPlus1 actually share almost all their memory. If the app releases its reference to either list, only the data unique to that particular list becomes a candidate for garbage collection, so no memory leaks are created.
Each mutation call into an immutable collection, results in allocating a few new nodes in the binary tree. Thousands of these mutation calls can add up in terms of GC pressure and performance. The same problem exists when mutation strings repeatedly, which is usually avoided by using StringBuilder. Immutable collections use the same builder approach as strings; all immutable collections provide the ToBuilder methods which are used to initialize and update collections. Immutability is restored by calling ToImmutable methods. For example,
ImmutableHashSet<int>.Builder builder = ImmutableHashSet<int>.Empty.ToBuilder();
for (int i = 0; i < 1000; i++)
builder.Add(i);
ImmutableHashSet<int> immutableSet = builder.ToImmutable();
Debug.Assert(immutableSet.Count == 1000);
Builders give you the ability to start and finish a series of mutations with immutable instances, but in between use mutability for greater efficiency. Both the collections you start and finish with are in fact immutable. ToBuilder does not copy the collection, but rather keeps using the existing immutable collection you already had. When the builder collection is modified, it allocates a new reference to the collection that points to a slightly modified collection, which preserves the original collection unmodified. Finally, when ToImmutable is called, the builder freezes its modified internal structure and returns the new reference to the immutable collection. No immutable collections are modified in the execution of the above example, nor was the entire collection copied at any time.
Immutable collections are heavily tunes for maximum performance and minimum GC pressure. They are typically faster when you requires snapshot semantics. For example, consider this code which provides snapshot semantics in a multi-threaded application:
private List<int> _customerIds;
public IReadOnlyList<int> CustomerIds
{
get
{
lock (_customerIds) return _customerIds.ToList();
}
}
Every time CustomerIds is called, an entire copy of the internal collection is made. Performance can be greatly improved by replacing this mutable collection with an immutable one because neither locking nor copying would be required:
private ImmutableList<int> _customerIds;
public IReadOnlyList<int> CustomerIds
{
get { return _customerIds; }
}
Immutable types generally have a performance of O(log n) due to their internal data structures that allow sharing across instances of the collections. Immutable collections use immutable balanced binary trees to store their data, allowing very efficient data sharing across mutated instances of the collections. As a result however, every lookup or change requires a tree traversal that has (at worst) an algorithmic complexity of O(log n).
The immutable collections spend a bit more memory per element for storage than their mutable counterparts. When removing elements from your collection, the mutable collections generally don’t shrink their arrays so you don’t reclaim that memory. Immutable collections immediately shrink their binary trees for each removed element so the memory is a candidate for garbage collection.
Assume you have the following mutable design for managing orders and order lines:
class MOrderLine
{
public int Quantity { get; set; }
public double UnitPrice { get; set; }
public float Discount { get; set; }
public double Total
{ get { return (Quantity*UnitPrice)*(1.0f - Discount); } }
}
class MOrder
{
public List<MOrderLine> OrderLines { get; private set; }
public MOrder()
{
OrderLines = new List<MOrderLine>();
}
}
public MOrder CreateMutableOrder()
{
MOrder mutableOrder = new MOrder();
mutableOrder.OrderLines.Add( new MOrderLine {Discount = 0.0f,
Quantity = 5, UnitPrice = 9.99});
mutableOrder.OrderLines.Add(new MOrderLine { Discount = 0.1f,
Quantity = 2, UnitPrice = 19.99 });
// The caller of this function can still get access to OrderLines property and call Add
return mutableOrder;
}
We can turn this code to use immutable lists as follows:
public class IMOrderLine
{
private readonly int _quantity;
private readonly double _unitPrice;
private readonly float _discount;
public int Quantity { get { return _quantity; } }
public double UnitPrice { get { return _unitPrice; } }
public float Discount { get { return _discount; } }
public IMOrderLine(int quantity, double unitPrice, float discount)
{
_quantity = quantity;
_unitPrice = unitPrice;
_discount = discount;
}
public double Total { get { return (_quantity * _unitPrice) * (1.0f - _discount); } }
// We make the design more convenient by adding WithXxx methods that let you update
// individual properties without having to explicitly call the constructor. Note that we
// do not create new instances if the incoming value is equal to the current value
public IMOrderLine WithQuantity(int value)
{
return (value == Quantity) ? this :
new IMOrderLine(value, this.UnitPrice, this.Discount);
}
public IMOrderLine WithUnitPrice(double value)
{
return (value == UnitPrice) ? this : new IMOrderLine(this.
Quantity, value, this.Discount);
}
public IMOrderLine WithDiscount(float value)
{
return (value == Discount) ? this :
new IMOrderLine(this.Quantity, this.UnitPrice, value);
}
}
public class IMOrder
{
public ImmutableList<IMOrderLine> OrderLines { get; private set; }
// Constructor takes an IEnumerable<> allowing you to pass any collection
public IMOrder(IEnumerable<IMOrderLine> lines)
{
OrderLines = lines.ToImmutableList();
}
public IMOrder()
{
OrderLines = ImmutableList<IMOrderLine>.Empty;
}
public IMOrder WithLines(IEnumerable<IMOrderLine> lines)
{
return Object.ReferenceEquals(lines, OrderLines) ? this : new IMOrder(lines);
}
public IMOrder AddLine(IMOrderLine orderLine)
{
return WithLines(OrderLines.Add(orderLine));
}
public IMOrder RemoveLine(IMOrderLine orderLine)
{
return WithLines(OrderLines.Remove(orderLine));
}
}
public IMOrder CreateImmutableOrder()
{
IMOrder immutableOrder = new IMOrder();
immutableOrder.AddLine(new IMOrderLine(1, 9.99, 0.0f));
immutableOrder.AddLine(new IMOrderLine(1, 19.99, 0.1f));
return immutableOrder;
}
Definition: Big-O notation is used to describe the complexity of an algorithm in terms of time and space. It shows how an algorithm scales.
Note that you can only compare algorithms that do similar things. You cannot compare an algorithm that does sorting to an algorithm that does arithmetic operations (+, -, x, /), however, you can compare an algorithm that does multiplication to an algorithm that does additions.
Example 1: The following table illustrates very simple algorithms and their Big-O notation:
| Algorithm | Big-O Notation |
| 123456 + 789012 -------- |
To add two 6-digit numbers, we have to do 6 additions. To add two
n-digit numbers, we have to do n additions. The complexity is the number
of add operations and is directly proportional to the number of digits,
n. This is O(n) which is also called linear complexity. Subtraction is similar. |
| 123456 x 789012 -------- |
In multiplication, you take the first bottom digit and multiply it by each digit in the upper row. This is repeated for each digit in the bottom row. To multiply the two 6-digit numbers, you'll have to do 6x6 = 62 = 36 multiplications and a few additions (for carries). For 100 digits, you'll have to do 1002 = 10000 additions and a few carries. This is O(n2) which is also called quadratic complexity. |
Note that for multiplication, the complexity is actually O(n2+2n) to account for additions. However, we only care about the most significant part of the complexity, hence, 2n is dropped.
Example 2: Consider binary search which is used to look up a data item when the data is sorted. For example, telephone books list family names in alphabetical order, A's then B's, etc. For example to find family name Smith, a typical implementation might be to open up to the middle, take the 500,000th and compare it to "Smith". If it happens to be "Smith", we just got real lucky. Far more likely is that "Smith" will be before or after that name. If it's after we then divide the last half of the phone book in half and repeat. If it's before then we divide the first half of the phone book in half and repeat. And so on.
For a phone book of 3 names it takes 2 comparisons (at most).
For 7 it takes at most 3.
For 15 it takes 4 (7 → 3 → 2 → 1)
For 100 it takes 7 (100 / 2 = 50 → 25 → 12 → 6 → 3 → 2 → 1)
For 1,000,000 it takes 20
In Big-O notation, this is O(log n) or logarithmic complexity. The logarithm could ln, log10, log2, etc. It is does not matter which log, it still remains O(log n).
Generally Big-O is used to determine three cases for an algorithm:
Best Case: In the telephone book example, the best case is that we find the name in one comparison, or O(1) known as constant complexity.
Expected Case: This is O(log n).
Worst Case: This is O(log n).
Normally we do not care about the best case, we're interested in the expected and worst cases.
Example 3: Consider the phone book again. What if you have a phone number and you want to find the name. The phone book is unordered by phone number, so you'll have to start at the first name and compare the number. If it's a match, great, if not, move on to the next name. So to find a name by phone number:
Best Case: O(1)
Expected Case: O(n)
Worst Case: O(n)
Example 4: Consider the travelling salesman problem where you have N towns and each is linked to 1 or more other towns. If you have three towns, A, B, and C, you could go:
A → B → C (same as C → B → A)
A → C → B (same as B → C → A)
B → A → C (same as C → A → B)
If you have 4 towns, you'll have 12 possibilities, and with 5 towns it's 60 and with n towns it's n!. Therefore, the Big-O notation for the travelling salesman is O(n!).
Recall that Big-O notation shows how an algorithm scales. Consider the following:
| Big-O | Example | Meaning |
|
O(1) |
Find an item in a dictionary |
The algorithm will always execute in the same time (or space). The time it takes to find an item is always the same irrespective of how many items exist in the dictionary. Time to complete is constant. |
| O(n) | Find an item in a linked list |
The algorithm performance or memory requirements grows linearly with the size of the input data. The time it takes to find an item is directly proportional to the number of items that exist in the linked list. In a linked list with 1 item it may take 1ms to find it, but in a linked list with 1000 items, it may take 1000ms to find it. Time to complete is n. |
| O(n2) | Running nested loops |
The algorithm performance or memory requirements is the square of the size of the input data. Consider the multiplication example given earlier. Time to complete n items is equal to n x n = n2. |
| O(log n) | Binary search |
The time it takes to find an item in a Binary Search Tree is proportional to the log of the number of items that exist. |
| O(n log n) | Quick sort | The algorithm performance or memory requirements is n log n. |
| O(n!) | Travelling salesman | The algorithm performance or memory requirements is the factorial of the input data. |
| O(2N) | ? | The algorithm performance or memory requirements will double with each additional element. |
When writing Big-O notations, it is common practice to,
Drop all but the most significant terms. Instead of O(n2 + n log n + n), we write O(n2).
Drop constant coefficients. Instead of O(3n2) we write O(n2). If the function is constant, instead of say O(1234), we write O(1).
| Collection | Ordering | Contiguous Storage | Direct Access | Lookup Efficiency | Manipulate Efficiency | Notes |
| Dictionary | Unordered | Yes | Via Key | O(1) | O(1) | High performance lookup |
| SortedDictionary | Sorted | No | Via Key | O(log n) | O(log n) | Uses Binary Search Tree |
| SortedList | Sorted | Yes | Via Key | O(log n) | O(n) | Similar to SortedDictionary, but tree is implemented as an array. |
| List |
User has control over element ordering |
Yes | Via index | Index: O(1) Value: O(n) |
O(n) | Best when direct access is required but no sorting |
| LinkedList | User has control over element ordering | No | No | O(n) | O(1) | Best when no direct access is required |
| HashSet | Unordered | Yes | Via Key | O(1) | O(1) | Unique unordered collection. Like dictionary except key and value are the same. |
| SortedSet | Sorted | No | Via Key | O(log n) | O(log n) | Unique sorted collection, like SortedDictionary except key and value are same object. |
| Stack | Last In First Out | Yes | Only Top | Top: O(1) | O(1) | |
| Queue | First In First Out | Yes | Only Front | Front: O(1) | O(1) |
The generic Dictionary<TKey,TValue> allows us to add/remove and seek items in constant time complexity O(1) - if you know how to use it properly.
In order to provide O(1) time complexity, the generic dictionary is built using a hash table, which is a data structure which consists of an array of buckets for storing elements. The dictionary handles inserting new items by obtaining a hash code for the item via GetHashCode, and using that hash code to determine in which bucket to place the item (usually by performing a mod operation on the hash code to adjust it to the size of the buckets array). For example, the buckets array might have a length of 30, and an item's hash code might be 1234. To determine which bucket to insert the item, we can do 1234 mod 30 = 4, so it's the fourth bucket.
Now consider the following:
public void TestDictionary2()
{
var dict = new Dictionary<int, string>(); // No capacity specified. Default is 3 dict.Add(1, "A"); // O(1) dict.Add(2, "B"); // O(1) dict.Add(3, "C"); // O(1) dict.Add(4, "D"); // O(N) dict.Add(5, "E"); // O(1) }
When instantiating a dictionary with a default constructor, an array of 3 items is allocated. After adding 3 items, the dictionary's inner array of buckets is full. When adding item <4, "D">, the dictionary checks if the number of items in the dictionary is equal to its size, and in this case it is, and it allocates a new larger array whose size is 7. After adding more items, the process is repeated and the new size is 17. Dictionary<,> has an inner pre-calculated list of prime numbers that are used for the array size (From ILSpy on HashHelpers in System.Collections):
public static readonly int[] primes = new int[]
{
3,
7,
11,
17,
23,
29,
...
}
Therefore, it is always helpful to set an initial size when instantiating a dictionary - even if you have a rough estimate on the size - as it will avoid copying and re-allocating large arrays.
Collision happens when two items have the same hash code, and therefore will get the same index in the buckets array. There are several ways to handle collisions, and Dictionary<,> uses a method called chaining. Dictionary<,> actually has two arrays with the same number of items (from ILSpy):
private struct Entry { public int hashCode;
public int next;
public TKey key;
public TValue value;
}
private int[] buckets; // stores object's index in array entries[] private Dictionary<TKey, TValue>.Entry[] entries; // stores actual data
Entry.next corresponds to the next index in the entries array for the next item in the collision chain. Also note that the size of the Entry struct is determined by TKey and TValue: for Dictionary<int, string> the size is for 3 ints (12 bytes) plus 4 bytes for the string reference. Also note that the buckets array has the same size as the entries array. This means that Dictionary<,> has a load ration of 1:1 which means that the dictionary size cannot be less than the amount of items in it. Even if not all buckets are being used, all slots in entries array are used.