From a user perspective, application response time defines performance, and performance is defined through key application metrics such as transaction throughput and resource utilization. Metrics related to hardware such as network throughput and disk access are common performance bottlenecks.
Note that performance and scalability are not interchangeable terms. They are two distinct issues- while performance relates to how fast the application responds to user requests, scalability relates to the capability of the system to add additional resources to compensate for increased work load.
Disregarding performance will result in an application that performs poorly. Responsibility for performance occur both at design time and at run time:
Performance requirements should be defined before development begins. In general, to properly define performance requirements, you will need to:
Based on this you can select appropriate metrics and determine specific performance goals.
The following suggestions help identify the expected application load:
Application features typically correspond to use cases and usage scenarios. Here you need to precisely define the semantics of each feature (use case) that is performance-sensitive. You need to fully examine how the feature processes the use-case including verifications, business processing, database access, caching, and so on. It is these definitions that drive the tests that measure performance.
Also note that accurate estimates of the usage of various application services can help create tests that mimic real-life usage of the system.
Changing some aspects of a project to improve performance may not be an option. For example, if an application has to be delivered by a specified date, then re-designing it for performance may not be an option. Hardware constraints may also be a factor, especially for user workstations. All these constraints must be documented because they are constant during performance tuning.
Aspects of the projects that are not constrained may be changed during performance tuning. For example, examine if transactions (when used) are really needed. Examine if new servers can be added to the application topology, and so on. These issues can help remove bottlenecks in the system.
Capacity planning is determining the most efficient way of increasing a system's performance and scalability, while at the same time predicting the point at which a resource will cause a bottleneck in the system. The starting point for capacity planning is determining the application's capacity, which you can determine by:
Capacity is indirectly influenced by performance. A well-tuned application can increase capacity by efficiently using available resources and releasing resources that are not used by an active process. At some point, the application can handle more request without degrading performance. This is the point at which you either scale up by upgrading or replacing existing servers, or scale out by adding more servers..
Ideally, you should do some capacity planning that established acceptable performance benchmarks and resource usage limits. You should also develop a plan to scale your system as soon as performance degrades.#
Performance testing assumes that the application is functioning, stable, and robust. The application must pass its functional tests before you can test for performance, otherwise, bugs in the code can potentially mask performance problems, or even worse, give the impression that there is a performance problem.
The following guidelines should be used when testing for performance:
To tune performance, you must be able to maintain records of each performance test pass. These records should include:
Try to automate as much as possible of the performance tests to eliminate possible operator differences. Also during each test pass, run the same exact set of performance tests - otherwise, it will not be possible to distinguish whether different performance results are due to code changes or to test changes.
Testing should be as realistic as possible. For example, test the application to determine how it performs when many clients are accessing it simultaneously ( a multi-threaded test-harness can simulate multiple clients in a reproducible manner.) If the application accesses a database, the database should contain a realistic number of records. If the database is too small, performance results will be inaccurate.
Make sure you document how to set up a database for running a performance test. The instructions should specify that the database should not include changes make by a previous test pass.
After defining performance goals and developing performance test, run the tests one to establish a baseline. Baseline results along with documenting the initial test environment will provide a solid foundation for the tuning effort.
Stress testing is a specialized form of performance testing. The goal of stress testing is to crash the application by increasing the processing load until the application begins to fail due to saturation of resources or occurrence of errors. Stress testing often reveals subtle bugs that go unnoticed until the application is deployed. While some of these bugs may be logical (i.e., array limit was exceeded ), most often they are the result of design flaws. Therefore, stress testing should begin early in the development phase of each part of the application. These kinds of bugs should be fixed at their source rather than fixing bugs that manifest themselves as a result of the source bug.
Finding a solution to poor performance is often like conducting a scientific experiment. You can most often solve performance problems by following the same process for conducting a scientific experimentation. This process contains six steps:
The output of the experiment is a theory which consists of a hypothesis supported by a collection of evidence accumulated by the process.
For example, you observe a poor performance in a distributed application which uses thread pooling for server-side objects. Using the performance monitor - PerMon - you (1) observe that the number of threads per CPU never exceeds 10 threads . You (2) hypothesize that the maximum number of threads per thread pool is set to a low value and needs to be increased. You (3) predict that increasing the ThreadCountPerThreadPool property will improve performance. The ThreadCountPerThreadPool property has now become the (4) control and you start (5) testing various values of this property and see how it affects performance. If performance that is more satisfactory is achieved after several adjustments to this property, you establish a (6) theory that certain property settings can provide enhanced performance in combination with all current variables.
Performance tuning is the main activity associated with performance management. Reduced to its most basic level, performance tuning is about finding and eliminating performance bottlenecks. Bottlenecks usually appear when a piece of hardware or software approaches the limit of its capacity.
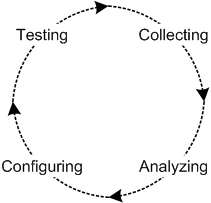
Tuning the performance of an application uses a tuning cycle shown below:
However, before starting the performance tuning cycle, you need to establish the framework for ongoing performance tuning activities. For example:
After establishing boundaries and expectations for performance tuning, you can begin the tuning cycle. As shown by the figure above, the tuning cycle is an iterative series of four (4) controlled performance experiments. These four steps are:
This is the starting point of any tuning exercise. During this phase you simply collect performance data with the collection of performance counters that you have chosen for a specific part of the system. These counters (often from PerfMon) could be the CPU, threads, network I/O, back-end database connections, and so on.
Regardless of what part you are tuning, you require a baseline measurement against which you should compare performance changes. You can use your first data-gathering pass to establish a baseline set of values for the system's behavior.
After collecting performance data, you start analyzing it to determine performance bottlenecks. Keep in mind that a performance counter is only an indicator - it does not necessarily identify the bottleneck because you can trace a performance bottleneck back to multiple sources. One the best examples is a CPU performance counter which can be directly affected by low disk space. It is also common for problems in one system component to result from problems in another system component.
The following points provide guidelines for interpreting counter values and eliminating false or misleading data:
After collecting and analyzing data, you can determine which part of the system is a candidate for a configuration change, and then implement this change. When tuning performance, the cardinal rule is to implement one configuration change at a time before repeating the tuning cycle again.
After completing a single configuration change, determine the impact of this single change on the system performance. At this point, you need to determine if this single change improved performance, degraded performance, or had no effect on performance. If performance has been improved, you can quite, otherwise you must step through the tuning cycle again.
The following practices are recommended for creating high-performance applications: